python代码爬取html网页之scrapy框架
2019-02-18 15:20
489 查看
scrapy 爬虫框架
scrapy是个能够帮助用户实现专业网络爬虫的爬虫框架,不同于小编之前介绍的requests、Beautifulsoup、re这些函数功能库,可实现网站级爬虫,但对于处理js、提交表单、应对验证码等功能还有望扩展。
安装
scrapy爬虫框架的安装方法与其它第三方库无区别
#在cmd或anaconda prompt上运行即可 pip install scrapy
命令执行
#scrapy命令行格式 scrapy <command> [options] [args]
| 命令 | 说明 |
|---|---|
| scrapy startproject <name> [dir] | 创建一个新爬虫项目,自动生成一系列文件目录,name指定项目名称 |
| scrapy genspider [option] <name> <domain> | 创建一个爬虫,domain指定所要爬取的网页url,option是可选命令操作符,name指定爬虫名称 |
| scrapy settings [option] | 获取爬虫配置信息,option是可选命令操作符 |
| scrapy runspider [option] <spider_file> | 运行爬虫程序,option是可选命令操作符,spider_file指定需要运行的文件,要有py后缀(旧版本用的是scrapy crawl <spider>) |
以上仅介绍了4个常用的scrapy命令,其余5个bench,fetch,shell,view,version自行在命令行窗口运行‘scrapy’查看
框架结构讲解
执行scrapy startproject 命令后,自动地在指定目录里生成了一堆文件,让人无从下手,接下来讲解一下scrapy爬虫框架。
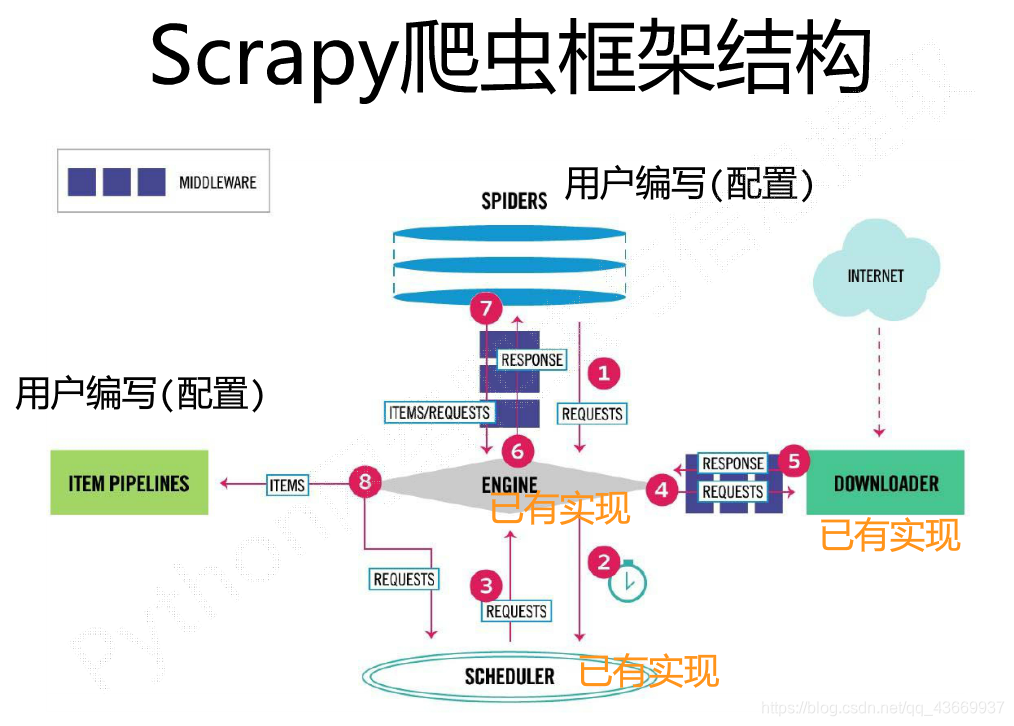

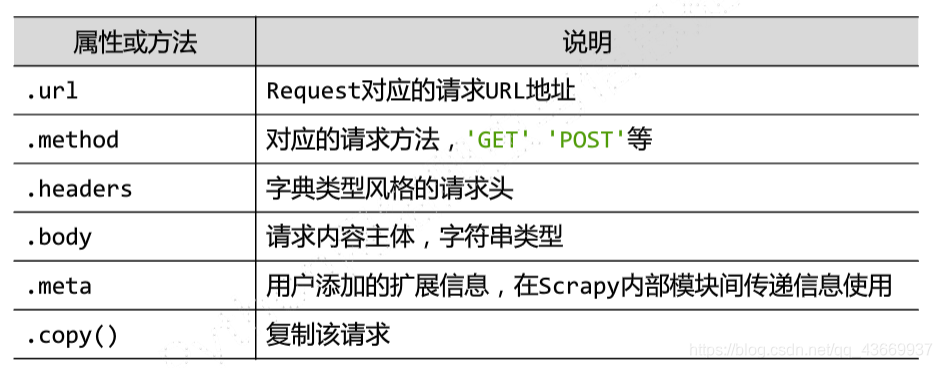
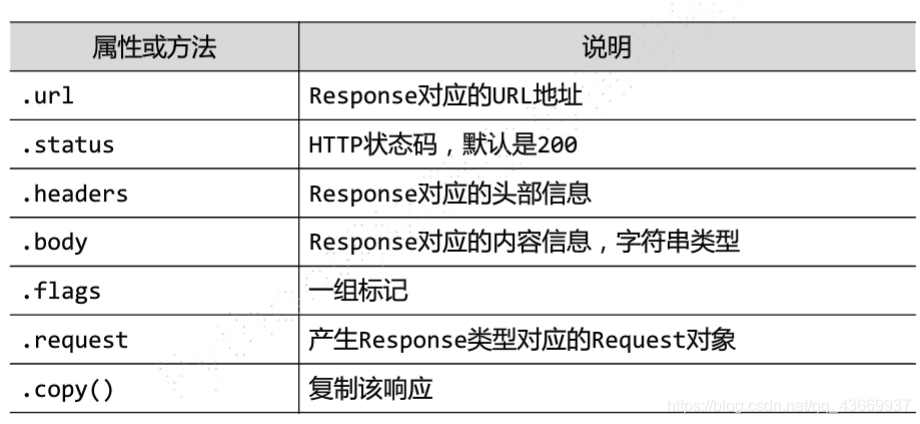
文件中经常出现的Response类、Requests类、Item类
Requests对象表示一个HTTP请求,由spider生成,由downloader执行。
而Response对象表示一个http响应,由downloader生成,由spider处理。
Item对象表示一个从HTML页面中提取的信息内容由spider生成,再由Item Pipline处理。Item类似字典类型,可按照字典类型操作。
从上图可以看出engine、downloader、scheduler模块已经是别人写好且完善,我们无需修改。一般我们主要配置在spiders文件夹中自己生成爬虫程序与pipelines.py如何输出数据。
值得注意的是对于文件修改,如果运行时出现了异常,看看是否自己的修改与setting.py的规定不符。scrapy默认支持CSS Selector解析页面。

相关文章推荐
- Scrapy:Python3版本上安装数据挖掘必备的scrapy框架详细攻略(二最完整爬取网页内容信息攻略)——Jason niu
- Python爬虫框架Scrapy实例代码
- Python 爬取网页HTML代码
- html制作简单框架网页二 实现自己的影音驿站 操作步骤及源文件下载 (可播放mp4、avi、mpg、asx、swf各种文件的视频播放代码)
- Python的爬虫框架scrapy用21行代码写一个爬虫
- Python_Scrapy_9.网页 HTML CSS
- Python网页爬取的通用代码框架
- python学习之----初见网络爬虫(输出整个网页html的代码)
- scrapy:python下的网页抓取及解析框架
- python爬取网页代码框架
- Scrapy:Python实现scrapy框架爬虫两个网址下载网页内容信息——Jason niu
- Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- Python抓取HTML网页并以PDF保存
- 网页HTML特殊符号代码大全,HTML特殊字符编码对照表
- [转]html网页 swf播放器使用代码
- CodeIgniter框架过滤HTML危险代码
- 网页中运行其它html代码
- Python爬虫爬取一个网页上的图片地址实例代码
- Python 爬取蚂蜂窝旅游攻略 (+Scrapy框架+MySQL)