情感分析实例:IMDB影评情感分析-基于keras的python学习笔记(十二)
2019-01-25 21:08
781 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_44474718/article/details/86651958
分析某部电影是好电影还是不好的电影。数据集由IMDB(http://www.imdb.com/interfaces/)提供。
一、导入数据
数据通过keras的
imdb.load_data()函数导入,为了便于在训练中使用数据集,keras提供的数据集将单词转化成整数,这个整数代表单词在整个数据集中的流行程度。
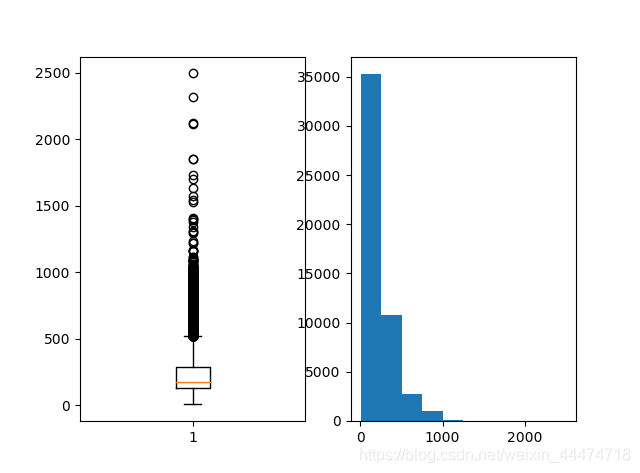
导入数据后,将训练数据和评估数据集合并,并查看相关统计信息,如中值和标准差,结构通过箱线图和直方图展示,代码如下:
from keras.datasets import imdb
import numpy as np
from matplotlib import pyplot as plt
(x_train, y_train), (x_validation, y_validation) = imdb.load_data()
# 合并训练集和评估数据集
x = np.concatenate((x_train, x_validation), axis=0)
y = np.concatenate((y_train, y_validation), axis=0)
print('x shape is %s, y shape is %s' % (x.shape, y.shape))
print('Classes: %s' % np.unique(y))
print('Total words: %s' % len(np.unique(np.hstack(x))))
result = [len(word) for word in x]
print('Mean: %.2f words (STD: %.2f)' %(np.mean(result), np.std(result)))
# 图表展示
plt.subplot(121)
plt.boxplot(result)
plt.subplot(122)
plt.hist(result)
plt.show()
执行代码,可以看到数据的离散状态和分布状态,结果如下:
x shape is (50000,), y shape is (50000,) Classes: [0 1] Total words: 88585 Mean: 234.76 words (STD: 172.91)
二、词嵌入
==词嵌入:是一种将词向量化的概念。==原理是:单词在高维空间中被编码为实值向量,其中词语之间的相似性意味着空间中的接近度。离散词被映射到连续数的向量。
from keras.datasets import imdb from keras.preprocessing import sequence from keras.layers.embeddings import Embedding (x_train, y_train), (x_validation, y_validation) = imdb.load_data(num_words=5000) x_train = sequence.pad_sequences(x_train, maxlen=500) x_validation = sequence.pad_sequences(x_validation, maxlen=500) Embedding(5000, 32, input_length=500)
三、多层感知器模型
下面从开发一个仅有单个隐藏层的多层感知器模型研究情感分析的问题。
from keras.datasets import imdb import numpy as np from keras.preprocessing import sequence from keras.layers.embeddings import Embedding from keras.layers import Dense, Flatten from keras.models import Sequential seed = 7 top_words = 5000 max_words = 500 out_dimension = 32 batch_size = 128 epochs = 2 def create_model(): model = Sequential() # 构建嵌入层 model.add(Embedding(top_words, out_dimension, input_length=max_words)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() return model if __name__ == '__main__': np.random.seed(seed=seed) # 导入数据 (x_train, y_train), (x_validation, y_validation) = imdb.load_data(num_words=top_words) # 限定数据集的长度 x_train = sequence.pad_sequences(x_train, maxlen=max_words) x_validation = sequence.pad_sequences(x_validation, maxlen=max_words) # 生成模型 model = create_model() model.fit(x_train, y_train, validation_data=(x_validation, y_validation), batch_size=batch_size, epochs=epochs, verbose=2)
四、卷积神经网络
卷积神经网络被设计为符合图像数据的空间结构,对场景中学习对象的位置和方向是鲁棒的。这种相同的原则可以用于处理序列问题(例如电影审查中的一维单词序列)。卷积神经网络的“特征位置的技术不变性”,同样可以帮助学习单词段落的结构。接下来在词嵌入层之后,增加一层一维卷积层和池化层,代码如下:
from keras.datasets import imdb import numpy as np from keras.preprocessing import sequence from keras.layers.embeddings import Embedding from keras.layers.convolutional import Conv1D, MaxPooling1D from keras.layers import Dense, Flatten from keras.models import Sequential seed = 7 top_words = 5000 max_words = 500 out_dimension = 32 batch_size = 128 epochs = 2 def create_model(): model = Sequential() # 构建嵌入层 model.add(Embedding(top_words, out_dimension, input_length=max_words)) # 1维度卷积层 model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() return model if __name__ == '__main__': np.random.seed(seed=seed) # 导入数据 (x_train, y_train), (x_validation, y_validation) = imdb.load_data(num_words=top_words) # 限定数据集的长度 x_train = sequence.pad_sequences(x_train, maxlen=max_words) x_validation = sequence.pad_sequences(x_validation, maxlen=max_words) # 生成模型 model = create_model() model.fit(x_train, y_train, validation_data=(x_validation, y_validation), batch_size=batch_size, epochs=epochs, verbose=2)

相关文章推荐
- 图像识别实例(CNN):CIFAR-10-基于keras的python学习笔记(十二--五)
- 基于python语言:Opencv3实例学习笔记1
- [Python][Scikit-learn][学习笔记01]线性回归之波士顿房价实例分析
- python cookbook第三版学习笔记十二:类和对象(三)创建新的类或实例属性
- 基于python语言:Opencv3实例学习笔记2
- learning jQuery 学习笔记十二(+jQuery 1.4.1 API)-- DOM操作-基于命令改变页面 ----包装元素
- input子系统学习笔记六 按键驱动实例分析下
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算
- 基于mini6410的linux驱动学习总结(五 字符设备驱动程序实例分析(虚拟设备驱动))
- Python ORM框架SQLAlchemy学习笔记之关系映射实例
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet之LR
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算
- input子系统学习笔记五 按键驱动实例分析上
- Python下的机器学习工具scikit-learn(学习笔记2--官方实例程序)
- Python & 数据分析学习笔记[第1篇]
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- spring学习笔记(10)@AspectJ研磨分析[3]增强织入顺序实例详解
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet之LR(转)
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算