Java源码解析HashMap的keySet()方法
HashMap的keySet()方法比较简单,作用是获取HashMap中的key的集合。虽然这个方法十分简单,似乎没有什么可供分析的,但真正看了源码,发现自己还是有很多不懂的地方。下面是keySet的代码。
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
从代码中了解到,第一次调用keySet方法时,keySet属性是null,然后进行了初始化,再将keySet属性返回。也就是说,HashMap里并不会随着put和remove的进行也维护一个keySet集合,而是在第一次调用keySet方法时,才给keySet属性初始化。
按照自己以往的理解,以为keySet返回的是一个集合,集合里面保存了HashMap的所有的Key。因为有了中先入为主的印象,所以读源码时,才感觉源码很奇怪。从源码中可以看到,初始化时,只是创建了一个KeySet类的对象,并没有把HashMap的key都加入进来,方法就返回了。除了自己以往的理解外,还有一个现象,让我坚信这时HashMap的key已经加入到keySet了,那就是在调试代码过程中IDE给出的调试信息。如下图。从图中可以看出,创建完成KeySet()后,调试信息就已经可以显示出,ks中有2个元素了。这个信息更加坚定了自己之前的理解。
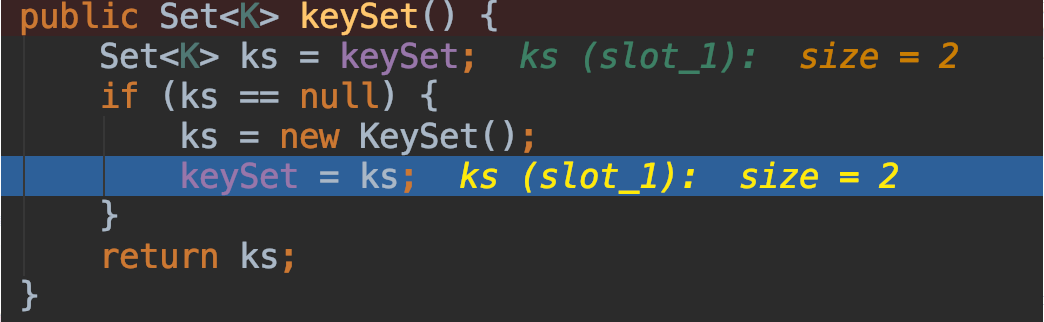
那么,HashMap的key是什么时候加入到keySet集合中的呢?顺着这个思路,我进行了一步一步的分析。自己看了KeySet类的构造函数,发现只有默认构造函数。那么我想,如果没有在KeySet构造函数里把HashMap的key加入进来,那么就有可能是在KeySet的父类的构造函数中加入进来的。然后,自己找遍了KeySet类的父类的构造函数,发现都是空实现,并没有任何加入HashMap的key的操作。这到底是怎么回事呢?
其实HashMap的key并没有加入到keySet集合中,而是在遍历的时候,使用迭代器对key进行的遍历。这是结论。下面我们看一下原因和过程。
首先看一下KeySet类的代码,如下图。可以看到,KeySet类中的迭代器函数,返回的是一个KeyIterator类的对象。它的next方法返回的是HashIterator的nextNode的key。也就是说,当使用迭代器遍历set内的元素时,KeySet类的迭代器,会保证能够依次获取到HashMap的节点的key值,这就是我们遍历keySet的过程的实质。
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
那么,这里我们可以思考这么一个问题。通过HashMap的keySet获取到keySet后,难道只能用迭代器遍历吗?keySet方法不把HashMap的key都加入到set中,那么调用者使用for(int i = 0; i < size; i ++)的方式遍历时,岂不是无法遍历set中的key了吗?是的,确实是的。keySet确实没有把key加入到set中,另外,它不用担心调用者用for(int i = 0; i < size; i ++)的方式遍历时获取不到key,因为set根本就没有set.get(i)这样类似的方法,要想遍历set,只能用迭代器,或者使用foreach方式(本质还是迭代器)。
这里还有个问题需要解释,就是在调试代码时,既然key没有加入到set中,那么IDE如何显示出set中有2个元素这样的信息的?原来,IDE显示对象信息时,会调用对象的toString方法。而集合的toString方法就是显示出集合中的元素个数。
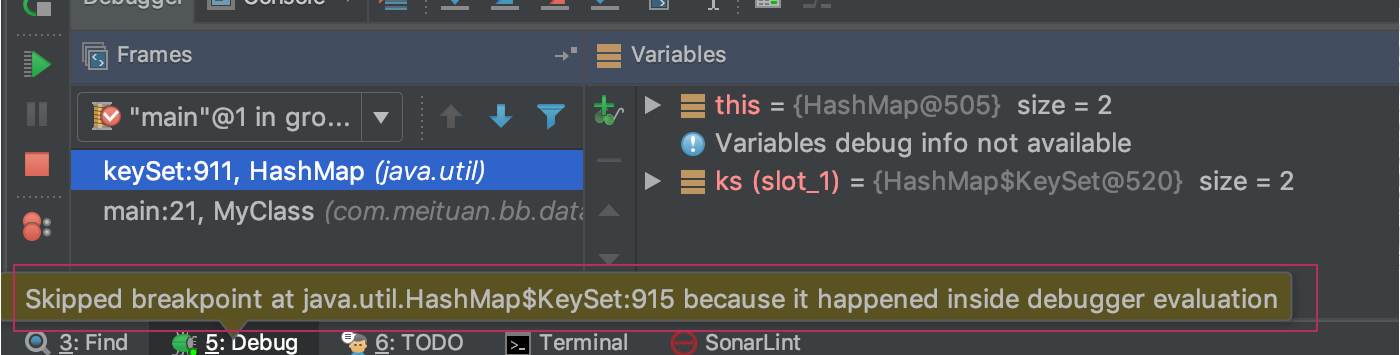
这里再思考一步,如果我们在集合的toString方法加上断点,那么IDE显示对象信息时,会不先停下来?答案是看情况。记得早些年间使用eclipse调试代码时,在toString方法加上断点后,显示对象信息时确实会停下来。然而我现在使用的是IDE是idea,idea在这一点上做了优化。如果是IDE显示对象信息调用的toString方法,那么toString方法的断点会被跳过,即不生效,但会给出一条提示信息,如下图。如果程序员主动调用对象的toString方法,那么,toString方法的断点会生效,可以正常断点调试。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。如果你想了解更多相关内容请查看下面相关链接
您可能感兴趣的文章:

- java 8 Hashmap深入解析 —— put get 方法源码
- Java8 HashMap put方法源码解析
- java 8 Hashmap深入解析 —— put get 方法源码
- java 8 Hashmap深入解析 —— put get 方法源码
- java 8 Hashmap深入解析 —— put get 方法源码
- 解析xml的几种方法,他们的原理,比较 以及JAVA源码
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
- Java8 HashMap resize()方法解析
- 解析xml的几种方法,他们的原理,比较 以及JAVA源码
- Java 1.8 HashMap 源码中 put()方法详解
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
- Java集合-08HashMap源码解析及使用实例
- Java HashMap 源码解析
- 2-5-Java多线程-创建线程的Runnable接口方法及Thread源码解析
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
- 【Java】HashMap源码分析——常用方法详解
- Java源码解析HashMap简介
- 【java集合】HashMap源码解析
- HashMap源码解析(JAVA 1.6)
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例