一文读懂Hadoop的前世今生
一、什么是Hadoop
1、Hadoop生态概况
Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠、高效、可伸缩的特点
Hadoop的核心是YARN,HDFS,Mapreduce,常用模块架构如下:
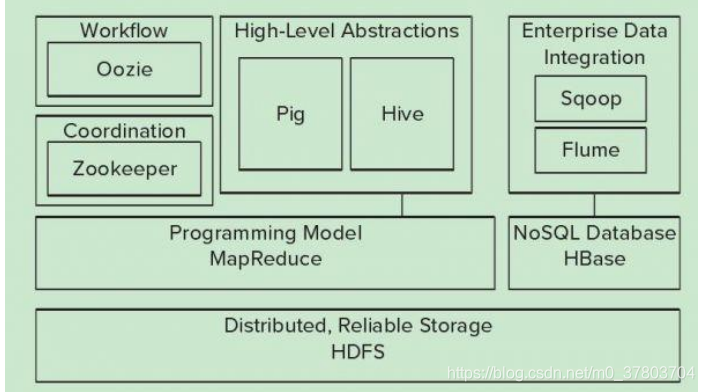
2、Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
3、Hadoop发展简史
Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。Hadoop源自始于2002年的Apache Nutch项目——一个开源的网络搜索引擎并且也是Lucene项目的一部分
在2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身
2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想
2005年,Nutch开源实现了谷歌的MapReduce
到了2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎
2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用
2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒
在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准
二、Hadoop的核心模块
1、YARN
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图).主要解决原始的Hadoop扩展性较差,不支持多种计算框架而提出的,架构如下
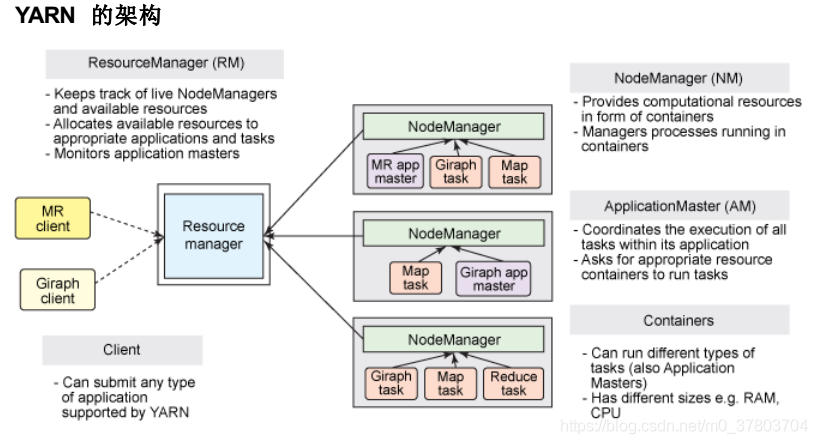
2、HDFS
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
以下是HDFS的数据存储架构图:

3、Mapreduce
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
Mapreduce工作流程如下所示:
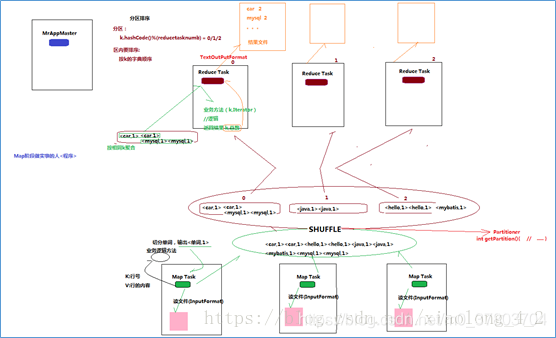
三、小结
1、Hadoop被视为事实上的大数据处理标准,讲述了Hadoop的发展历程,并阐述了Hadoop的高可靠性、高效性、高可扩展性、高容错性、成本低、运行在Linux平台上、支持多种编程语言等特性。
2、Hadoop目前已经在各个领域得到了广泛的应用,雅虎、Facebook、百度、淘宝、网易等公司都建立了自己的Hadoop集群。
3、经过多年发展,Hadoop项目已经变得非常成熟和完善,包括Common、Avro、Zookeeper、HDFS、MapReduce、HBase、Hive、Chukwa、Pig等子项目,其中,HDFS和MapReduce是Hadoop的两大核心组件。
如何学习大数据?学习没有资料?
4000想学习大数据开发技术,Hadoop,spark,云计算,数据分析、爬虫等技术,在这里向大家推荐一个学习资料分享群:894951460,里面有大牛已经整理好的相关学习资料,希望对你们有所帮助。

- 一文读懂智能助理的前世今生
- 四十五、一文读懂hadoop、hbase、hive、spark分布式系统架构
- 一文读懂大数据:Hadoop,大数据技术、案例及相关应用
- 一文读懂Hadoop、HBase、Hive、Spark分布式系统架构
- 一文读懂大数据:Hadoop,大数据技术、案例及相关应用
- 一文读懂hadoop、hbase、hive、spark分布式系统架构
- 一文读懂大数据:Hadoop,大数据技术及相关应用
- 一文读懂大数据:Hadoop,大数据技术及相关应用
- 技术向:一文读懂卷积神经网络CNN
- 一文读懂迭代器(iterator)在vector中的用法
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
- 福利 | 17篇精选技术干货大合集(手把手教、一文读懂系列)
- 一文读懂令美国恨之入骨的中国北斗卫星导航系统
- 一文读懂机器学习
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
- 2分钟读懂Hadoop和Spark的异同
- 一文读懂高性能网络编程中的I/O模型
- 一文读懂AlphaGo Zero算法
- 一文读懂块状元素和内联元素
- 技术向:一文读懂卷积神经网络CNN