决策树 - Cart + iris数据集 + python实现
- 决策树:
https://blog.csdn.net/weixin_43909872/article/details/85206009
- CART
Classification and regression tree
https://www.cnblogs.com/yonghao/p/5135386.html
CART 是在给定输入X条件下输出随机变量Y的条件概率分布的学习方法。CART对每个特征(包括标签特征以及连续特征)进行二分,经过最优二分特征及其最优二分特征值的选择、切分,二叉树生成,剪枝来实现CART算法。对于回归CART树选择误差平方和准则、对于分类CART树选择基尼系数准则进行特征选择,并递归调用构建二叉树过程生成CART树。 CART既可以用于分类也可以用于回归。
CART算法分两步:
a. 决策树生成:基于训练数据生成决策树,决策树尽量大
b. 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,用损失函数最小作为剪枝的标准
- iris数据集的分析:
算法步骤:
a. load iris data, 打乱顺序,取前100个为训练数据,30个validation data,用于剪枝,剩下20个用于最后测试。
data = pd.read_csv("iris.csv")
data = data.sample(frac=1.0)
data = data.reset_index()
deleteColumns = [0,1]
data.drop(data.columns[deleteColumns], axis=1, inplace=True)
trainDataset = data.loc[0:99]
validationDataset = data.loc[100:129]
testDataset = data.loc[130:-1]
b. 递归建立二叉树,对当前数据集选择最好的划分方式
最好的划分方式就是挨个用feature值里的每个例子的值去尝试划分,选择Gain(Gini)最大的划分方式,返回值是选定的feature和所用的value,我们设置了两个阈值,一个是gini gain,小于此值不再继续,一个是最小分类,如果节点小于4则不再分
feature,value = chooseBestSplit(dataset,leafType,errType,threshold)
因为我们是用于分类,所以采用gini系数
确定哪个feature和value带来的gini gain最大,下面是计算Gini系数的方法:
def regressErr(dataset): ''' 输入:数据集 功能:求数据集划分左右子数据集的误差平方和之和 输出: 数据集划分后的Gini值 ''' #每个种类的几率平方和/划分节点 count0 = len(dataset[dataset['Species'] == 0]) count1 = len(dataset[dataset['Species'] == 1]) count2 = len(dataset[dataset['Species'] == 2]) count = len(dataset) gini = 1 - np.square(np.true_divide(count0, count)) - np.square(np.true_divide(count1, count)) - np.square(np.true_divide(count2, count)) gini = np.true_divide(gini, 2) return gini
c.递归执行b步骤,直到没有节点可分
- 剪枝
CART采用CCP(代价复杂度)剪枝方法。代价复杂度选择节点表面误差率增益值最小的非叶子节点,删除该非叶子节点的左右子节点,若有多个非叶子节点的表面误差率增益值相同小,则选择非叶子节点中子节点数最多的非叶子节点进行剪枝。
计算误差率增益的方式类似于生成树时计算的算法,不再实现
运行结果:
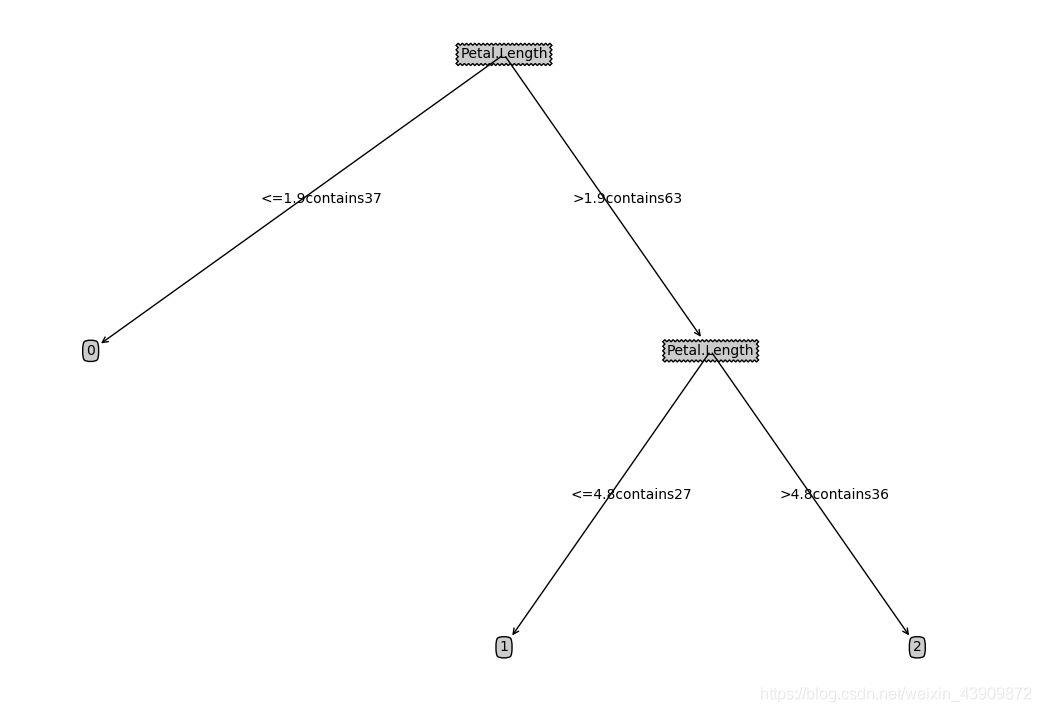
代码:
import numpy as np
import treePlotter
import pandas as pd
def binarySplitDataSet(dataset,feature,value):
'''
输入:数据集,数据集中某一特征列,该特征列中的某个取值
功能:将数据集按特征列的某一取值换分为左右两个子数据集
输出:左右子数据集
'''
matLeft = dataset.loc[dataset[feature] <= value]
matRight = dataset.loc[dataset[feature] > value]
return matLeft,matRight
def regressLeaf(dataset):
'''
输入:数据集
功能:求数据集输出列的均值
输出:对应数据集里数量最多的种类
'''
count0 = len(dataset[dataset['Species'] == 0])
count1 = len(dataset[dataset['Species'] == 1])
count2 = len(dataset[dataset['Species'] == 2])
weights = [count0, count1, count2]
return np.argmax(weights)
def regressErr(dataset):
'''
输入:数据集
功能:求数据集划分左右子数据集的误差平方和之和
输出: 数据集划分后的Gini值
'''
#每个种类的几率平方和/划分节点
count0 = len(dataset[dataset['Species'] == 0])
count1 = len(dataset[dataset['Species'] == 1])
count2 = len(dataset[dataset['Species'] == 2])
count = len(dataset)
gini = 1 - np.square(np.true_divide(count0, count)) - np.square(np.true_divide(count1, count)) - np.square(np.true_divide(count2, count))
gini = np.true_divide(gini, 2)
return gini
def chooseBestSplit(dataset,leafType=regressLeaf,errType=regressErr,threshold=(0.01,4)):
thresholdErr = threshold[0];thresholdSamples = threshold[1]
#当数据中输出值都相等时,feature = None,value = 输出值的均值(叶节点)
if len(set(dataset['Species'].T.tolist())) == 1:
return None,leafType(dataset)
Err = errType(dataset)
bestErr = np.inf; bestFeatureIndex = 0; bestFeatureValue = 0
featureNames = dataset.columns[0:-1].tolist()
for featureName in featureNames:
for featurevalue in dataset[featureName].tolist():
matLeft,matRight = binarySplitDataSet(dataset,featureName,featurevalue)
if (np.shape(matLeft)[0] < thresholdSamples) or (np.shape(matRight)[0] < thresholdSamples):
continue
temErr = errType(matLeft) + errType(matRight)
if temErr < bestErr:
bestErr = temErr
bestFeatureIndex = featureName
bestFeatureValue = featurevalue
#检验在所选出的最优划分特征及其取值下,误差平方和与未划分时的差是否小于阈值,若是,则不适合划分
if (Err - bestErr) < thresholdErr:
return None,leafType(dataset)
matLeft,matRight = binarySplitDataSet(dataset,bestFeatureIndex,bestFeatureValue)
#检验在所选出的最优划分特征及其取值下,划分的左右数据集的样本数是否小于阈值,若是,则不适合划分
if (np.shape(matLeft)[0] < thresholdSamples) or (np.shape(matRight)[0] < thresholdSamples):
return None,leafType(dataset)
return bestFeatureIndex,bestFeatureValue
def createCARTtree(dataset,leafType=regressLeaf,errType=regressErr,threshold=(1,4)):
'''
输入:数据集dataset,叶子节点形式leafType:regressLeaf(回归树)、modelLeaf(模型树)
损失函数errType:误差平方和也分为regressLeaf和modelLeaf、用户自定义阈值参数:
误差减少的阈值和子样本集应包含的最少样本个数
功能:建立回归树或模型树
输出:以字典嵌套数据形式返回子回归树或子模型树或叶结点
'''
feature,value = chooseBestSplit(dataset,leafType,errType,threshold)#当不满足阈值或某一子数据集下输出全相等时,返回叶节点
if feature == None: return value
returnTree = {}
leftSet,rightSet = binarySplitDataSet(dataset,feature,value)
returnTree[feature] = {}
returnTree[feature]['<=' + str(value) + 'contains' + str(len(leftSet))] = createCARTtree(leftSet,leafType,errType,threshold)
returnTree[feature]['>' + str(value) + 'contains' + str(len(rightSet))] = createCARTtree(rightSet,leafType,errType,threshold)
return returnTree
if __name__ == '__main__':
data = pd.read_csv("iris.csv")
data = data.sample(frac=1.0)
data = data.reset_index()
deleteColumns = [0,1]
data.drop(data.columns[deleteColumns], axis=1, inplace=True)
trainDataset = data.loc[0:99]
validationDataset = data.loc[100:129]
testDataset = data.loc[130:-1]
cartTree = createCARTtree(trainDataset,threshold=(0.01,4))
treePlotter.createPlot(cartTree)

- python实现 模糊C均值聚类算法(Fuzzy-C-Means)-基于iris数据集
- Python 3实现k-邻近算法以及 iris 数据集分类应用
- python 实现 knn分类算法 (Iris 数据集)
- AdaBoost + iris数据集实现+python
- 决策树之CART算法原理及python实现
- 神经网络与深度学习 使用Python实现基于梯度下降算法的神经网络和自制仿MNIST数据集的手写数字分类可视化程序 web版本
- python 中,实现对数据集的归一化(0-1之间)
- python 实现 Peceptron Learning Algorithm ( 三) 感知机模型应用于Iris数据集
- Python实现DescionTree决策树 --- 划分数据集
- 在python中利用KNN实现对iris进行分类的方法
- 决策树 (Decision Tree) 进阶应用 CART剪枝方法及Python实现方式
- CART分类回归树分析与python实现
- 李航《统计学习方法》第六章——用Python实现最大熵模型(MNIST数据集)
- 识别MNIST数据集:用Python实现神经网络
- python iris实现格点差值
- 机器学习算法的Python实现 (3):CART决策树与剪枝处理
- python 实现 Peceptron Learning Algorithm ( 三) 感知机模型应用于Iris数据集
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- python实现机器学习之决策树
- R语言实现分层抽样(Stratified Sampling)以iris数据集为例