LSTM实现股票预测--pytorch版本【120+行代码】
2018-12-20 20:45
627 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a19990412/article/details/85139058
简述
网上看到有人用Tensorflow写了的但是没看到有用pytorch写的。
所以我就写了一份。写的过程中没有参照任何TensorFlow版本的(因为我对TensorFlow目前理解有限),所以写得比较简单,看来来似乎也比较容易实现(欢迎各位大佬改进之后,发家致富,带带小弟hhh)。
效果
先简单的看看效果(会有点夸张hhh):
- 注意,我没有用全部数据!!而是真的用的训练集合来做的,下面的都是真实的…
- 不过,也没那么夸张,后面有讲解这幅图。

基于:
我以前写的几篇文章。
- RNN代码解释pytorch
- 所用的数据比较多,一般网上没办法直接获取。可以参照我以前写一个方法中的方法二 如何下载沪深300历史数据 当然也可以用tushare来实现(获取稍微少一点的数据)~
- 主要依赖于模型的建立 【时序数据处理】pandas某些列由于n个数据导致的,通过Series生成Dataframe
- 【解决办法】pandas画出时序数据(股票数据)横轴不是时间
项目描述
模型假设
我这里认为每天的沪深300的最高价格,是依赖于当天的前n天的沪深300的最高价。
然后用RNN的LSTM模型来估计(捕捉到时序信息)。
让模型学会用前n天的最高价,来判断当天的最高价。
思路很简单,所以模型也很简单~
导入包
import pandas as pd import matplotlib.pyplot as plt import datetime import torch import torch.nn as nn import numpy as np from torch.utils.data import Dataset, DataLoader
读取数据的函数
- 其中
generate_df_affect_by_n_days
函数,通过一个序列来生成一个矩阵(用于处理时序的数据)。就是把当天的前n天作为参数,当天的数据作为label。 - readData中的文件名为:
sh.csv
也可以是其他的文件大致类似的。自己可以修改。参数n就是之前模型中所说的n。train_end表示的是后面多少个数据作为测试集。
def generate_df_affect_by_n_days(series, n, index=False):
if len(series) <= n:
raise Exception("The Length of series is %d, while affect by (n=%d)." % (len(series), n))
df = pd.DataFrame()
for i in range(n):
df['c%d' % i] = series.tolist()[i:-(n - i)]
df['y'] = series.tolist()[n:]
if index:
df.index = series.index[n:]
return df
def readData(column='high', n=30, all_too=True, index=False, train_end=-300):
df = pd.read_csv("sh.csv", index_col=0)
d
24000
f.index = list(map(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d"), df.index))
df_column = df[column].copy()
df_column_train, df_column_test = df_column[:train_end], df_column[train_end - n:]
df_generate_from_df_column_train = generate_df_affect_by_n_days(df_column_train, n, index=index)
if all_too:
return df_generate_from_df_column_train, df_column, df.index.tolist()
return df_generate_from_df_column_train
类(RNN和数据读取类)
- RNN的类很简单,看模型也知道其实就两部分
- 数据读取类,这个主要为了满足pytorch习惯而设定的(建议大家也要养成这样的习惯)。
class RNN(nn.Module): def __init__(self, input_size): super(RNN, self).__init__() self.rnn = nn.LSTM( input_size=input_size, hidden_size=64, num_layers=1, batch_first=True ) self.out = nn.Sequential( nn.Linear(64, 1) ) def forward(self, x): r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state out = self.out(r_out) return out class TrainSet(Dataset): def __init__(self, data): # 定义好 image 的路径 self.data, self.label = data[:, :-1].float(), data[:, -1].float() def __getitem__(self, index): return self.data[index], self.label[index] def __len__(self): return len(self.data)
超参数
- n为模型中的n
- LR是模型的学习率
- EPOCH是多次循环
- train_end这个在之前的数据集中有提到。(注意是负数)
n = 30 LR = 0.0001 EPOCH = 100 train_end = -500
模型训练
其实前面都是准备工作
这里就正式开始了。
获取数据
- 训练模型仍然使用minibatch的思路
- 注意,模型必须要先把数据标准化,不然损失会很难降低下来。
# 数据集建立
df, df_all, df_index = readData('high', n=n, train_end=train_end)
df_all = np.array(df_all.tolist())
plt.plot(df_index, df_all, label='real-data')
df_numpy = np.array(df)
df_numpy_mean = np.mean(df_numpy)
df_numpy_std = np.std(df_numpy)
df_numpy = (df_numpy - df_numpy_mean) / df_numpy_std
df_tensor = torch.Tensor(df_numpy)
trainset = TrainSet(df_tensor)
trainloader = DataLoader(trainset, batch_size=10, shuffle=True)
训练模型部分
- 这个部分如果是不想要训练的话(比如已经训练好了模型),替换为
rnn = torch.load('rnn.pkl')(记得把原来的注释掉)
rnn = RNN(n) optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters loss_func = nn.MSELoss() for step in range(EPOCH): for tx, ty in trainloader: output = rnn(torch.unsqueeze(tx, dim=0)) loss = loss_func(torch.squeeze(output), ty) optimizer.zero_grad() # clear gradients for this training step loss.backward() # back propagation, compute gradients optimizer.step() print(step, loss) if step % 10: torch.save(rnn, 'rnn.pkl') torch.save(rnn, 'rnn.pkl')
画图
generate_data_train = [] generate_data_test = [] test_index = len(df_all) + train_end df_all_normal = (df_all - df_numpy_mean) / df_numpy_std df_all_normal_tensor = torch.Tensor(df_all_normal) for i in range(n, len(df_all)): x = df_all_normal_tensor[i - n:i] x = torch.unsqueeze(torch.unsqueeze(x, dim=0), dim=0) y = rnn(x) if i < test_index: generate_data_train.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean) else: generate_data_test.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean) plt.plot(df_index[n:train_end], generate_data_train, label='generate_train') plt.plot(df_index[train_end:], generate_data_test, label='generate_test') plt.legend() plt.show()
画图的结果就是:
- 这里,我在测试集合上,也是使用真实的当天的前n天的真实数据来作为输入。表面上看起来有点奇怪,但是这是可以理解的。现实生活中是可以做到的。
- 但是这幅图的话,太密了,下面我会画一张其中的片段的图片。
- 这是放大之后的:
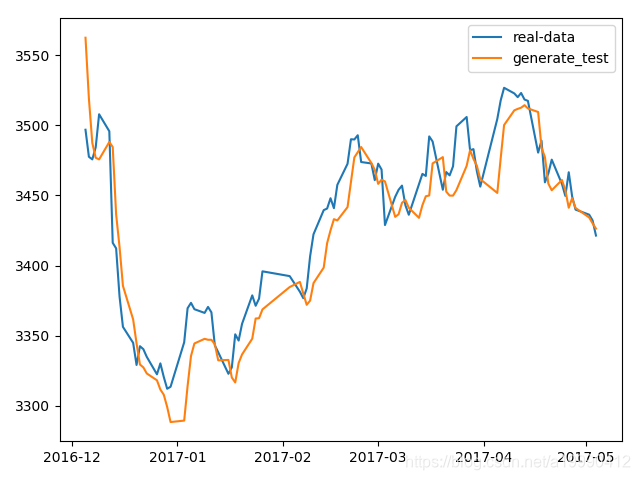
会发现出现有一定的滞后效应。不过也很正常啊,输入就只有价格…来预测价格… 这个模型的解释力真的不太行…
完整代码
import pandas as pd
import matplotlib.pyplot as plt
import datetime
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
def generate_df_affect_by_n_days(series, n, index=False):
if len(series) <= n:
raise Exception("The Length of series is %d, while affect by (n=%d)." % (len(series), n))
df = pd.DataFrame()
for i in range(n):
df['c%d' % i] = series.tolist()[i:-(n - i)]
df['y'] = series.tolist()[n:]
if index:
df.index = series.index[n:]
return df
def readData(column='high', n=30, all_too=True, index=False, train_end=-300):
df = pd.read_csv("sh.csv", index_col=0)
df.index = list(map(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d"), df.index))
df_column = df[column].copy()
df_column_train, df_column_test = df_column[:train_end], df_column[train_end - n:]
df_generate_from_df_column_train = generate_df_affect_by_n_days(df_column_train, n, index=index)
if all_too:
return df_generate_from_df_column_train, df_column, df.index.tolist()
return df_generate_from_df_column_train
class RNN(nn.Module):
def __init__(self, input_size):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out = nn.Sequential(
nn.Linear(64, 1)
)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
out = self.out(r_out)
return out
class TrainSet(Dataset):
def __init__(self, data):
# 定义好 image 的路径
self.data, self.label = data[:, :-1].float(), data[:, -1].float()
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.data)
n = 30
LR = 0.0001
EPOCH = 100
train_end = -500# 数据集建立
df, df_all, df_index = readData('high', n=n, train_end=train_end)
df_all = np.array(df_all.tolist())
plt.plot(df_index, df_all, label='real-data')
df_numpy = np.array(df)
df_numpy_mean = np.mean(df_numpy)
df_numpy_std = np.std(df_numpy)
df_numpy = (df_numpy - df_numpy_mean) / df_numpy_std
df_tensor = torch.Tensor(df_numpy)
trainset = TrainSet(df_tensor)
trainloader = DataLoader(trainset, batch_size=10, shuffle=True)
# rnn = torch.load('rnn.pkl')
rnn = RNN(n)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
for step in range(EPOCH):
for tx, ty in trainloader:
output = rnn(torch.unsqueeze(tx, dim=0))
loss = loss_func(torch.squeeze(output), ty)
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step()
print(step, loss)
if step % 10:
torch.save(rnn, 'rnn.pkl')
torch.save(rnn, 'rnn.pkl')#
generate_data_train = []
generate_data_test = []
test_index = len(df_all) + train_end
df_all_normal = (df_all - df_numpy_mean) / df_numpy_std
df_all_normal_tensor = torch.Tensor(df_all_normal)
for i in range(n, len(df_all)):
x = df_all_normal_tensor[i - n:i]
x = torch.unsqueeze(torch.unsqueeze(x, dim=0), dim=0)
y = rnn(x)
if i < test_index:
generate_data_train.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean)
else:
generate_data_test.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean)
plt.plot(df_index[n:train_end], generate_data_train, label='generate_train')
plt.plot(df_index[train_end:], generate_data_test, label='generate_test')
plt.legend()
plt.show()plt.cla()
plt.plot(df_index[train_end:-400], df_all[train_end:-400], label='real-data')
plt.plot(df_index[train_end:-400], generate_data_test[:-400], label='generate_test')
plt.legend()
plt.show()
阅读更多

相关文章推荐
- 代码可直接运行:利用LSTM预测股票每日最高价
- Android5.0以上版本录屏实现代码(完整代码)
- struts2 案例代码实现及遇到的问题【struts2.5版本】
- Html5版本的全套股票行情图开源了,附带实现技术简介
- 百度云网盘 360云盘 金山快盘 等 + Git GUI 实现代码版本管理-个人篇
- Html5版本的全套股票行情图开源了,附带实现技术简介
- RNN学习笔记(六)-GRU,LSTM 代码实现
- [置顶] Android版本更新的实现代码
- 深度学习之六,基于RNN(GRU,LSTM)的语言模型分析与theano代码实现
- 在TFS中使用Git Tags(标签或标记),实现代码的版本管理
- 通过判断JavaScript的版本实现执行不同的代码
- Java实现判断浏览器版本与类型简单代码示例
- Jfinal 2.1版本,JFinalConfig里自动配置路由的代码实现,直接晒代码
- leetcode:Copy List with Random Pointer 细致分析,以及代码实现(JAVA版本)
- C语言实现OOP 版本3 :简化代码
- 不到36行代码实现Scala版本的Kmeans
- 基于ARIMA的股票预测 Python实现 附Github
- "如何用70行Java代码实现深度神经网络算法" 的delphi版本
- Tensorflow实例:利用LSTM预测股票每日最高价(二)