爬虫入门教程③— 必备知识基础(二)HTTP请求简介
从我们在浏览器地址栏输入网址敲下了回车之后到一个鲜活的网页呈现在我们面前这中间究竟发生了什么呢?
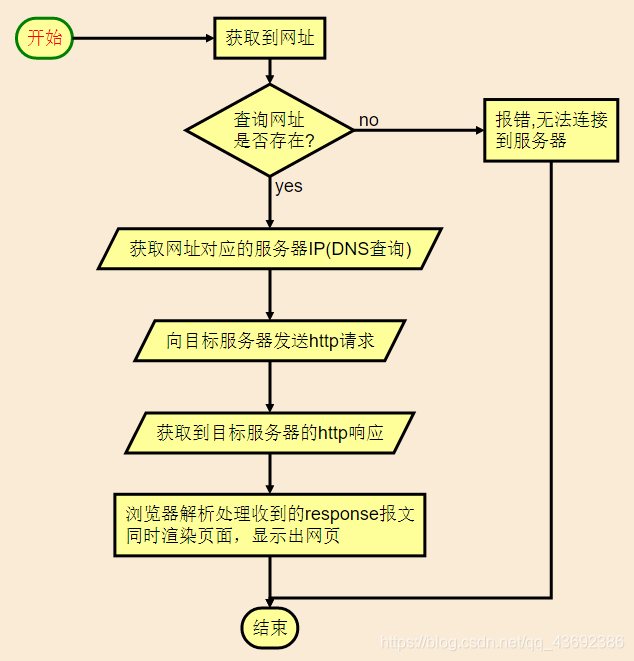
一次HTTP访问流程
DNS查询
DNS(Domain Name System,域名系统),万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过域名,最终得到该域名对应的IP地址的过程叫做域名解析(或主机名解析)。DNS协议运行在UDP协议之上,使用端口号53。在RFC文档中RFC 2181对DNS有规范说明,RFC 2136对DNS的动态更新进行说明,RFC 2308对DNS查询的反向缓存进行说明。
通俗来说,我们想去 www.baidu.com。但是计算机之间通信是采用的IP,所以我们必须知道www.baidu.com这个域名对应的服务器IP,于是我们去查一下DNS,就可以知道百度的服务器IP是多少了。
HTTP(S)协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了HTTP超文本传输协议标准架构的发展根基。Ted Nelson组织协调万维网协会(World Wide Web Consortium)和互联网工程工作小组(Internet Engineering Task Force )共同合作研究,最终发布了一系列的RFC,其中著名的RFC 2616定义了HTTP 1.1。
每一个完整的http请求,都由一个request和一个response组成。
打开浏览器,按了F12进入开发者模式,打开或者刷新网页,切换到network(网络)就可以看到请求和响应的信息了。
2.1 request
也就是我们常说的请求,这是由我们的客户端(浏览器/爬虫)发出的一个查询请求。
request包括的内容有:
请求头:主要是:请求的链接(URL)、客户端的Cookies、客户端的名字(UserAgent)、请求的方法(Method)、请求的参数(表单)。
请求的body:通常包含了一些要发送给服务器的数据,这些数据对用户是不可见的,不会显示在浏览器的地址栏里面。
HTTP headers
2.2. response
也就是服务器返回的响应。
响应也包括了响应头、响应的body。
在响应头里面通常有操作客户端Cookies的命令,增加cookie或者删除cookie,如果是跳转,那么会有一个跳转的目标网址,浏览器发现了,就会自动跳转到新的网址去。
响应的body,那就是响应的内容了,比如说网页内容,js代码,css代码,文件等等。
响应的body
2.3 综合知识
一个请求对应一个响应。构成了一个完整的HTTP请求。
在HTTP headers图里,我们可以看到有个General,里面有个StatusCode,这叫状态码。是人为规定一个用来判断请求状态的数字,常见的就是200,302,403,404.更多状态码详见HTTP状态码详解.
常见HTTP状态码的含义:
200–请求成功
302–请求跳转
403–拒绝访问
404–找不到资源。
那么HTTP和HTPPS协议有什么区别呢?HTTPS,简单概括就是升级版的HTTP协议,他最重要的功能,就是在HTTP基础上提高了安全性,基本上可以保证信息不会被第三方篡改。现在网站也基本上都在部署和使用HTTPS了。他的基本操作还是和http协议一样的,只不过是传输的数据经过了加密传输。
爬虫如果要获取到一个网页,那么就一定要发送一个HTTP请求,就必须经过这些过程。觉得麻烦吗?我也觉得。幸好已经有很多很优美的库,帮我们做好了大部分的工作,我们只需要专心我们的逻辑操作就OK了。
所以,感谢前辈大佬们。

- 爬虫入门教程④— 必备知识基础(三)网页的构成
- Java爬虫入门简介(一) —— HttpClient请求及其使用方法
- Android基础入门教程——7.1.3 Android HTTP请求方式-HttpURLConnection
- Android基础入门教程——7.1.2 Android Http请求头与响应头的学习
- Java爬虫入门简介(一) —— HttpClient请求及其使用方法
- Android基础入门教程——7.1.4 Android HTTP请求方式-HttpClient
- 【HttpClient4.5中文教程】【第一章 :基础】1.1执行请求(一)
- ARM基础知识教程(一):ARM简介
- 程序必备基础知识学习:通信协议——Http、TCP、UDP
- JAVA基础知识之网络编程——-网络基础(Java的http get和post请求,多线程下载)
- WCF入门教程:WCF基础知识问与答(转)
- VC入门必备--基础知识(二)
- 03.风哥Oracle数据库入门必备Linux基础系列视频教程(Oracle零基础教程)
- 什么是IndexedDB:Web离线数据库入门简介及基础教程
- 手游入门必备基础知识
- 【HttpClient4.5中文教程】【第一章 :基础】1.1执行请求(二)
- python爬虫入门(4)-补充知识:XPath 教程(转自w3school)
- Django基础知识与基本应用入门教程
- ionic入门教程第六课-从服务器请求数据的几种方式$http.get()、jsonp()分别和callback、$q的组合
- DirectX11入门教程——第二篇:DirectX11的基础知识