网络爬虫技术快速入门
2018-11-21 12:15
197 查看
网络爬虫技术快速入门
一、爬虫流程
我们可以把它概括为四步:
- 发起请求
- 获取响应内容
- 解析响应内容
- 保存数据

二、请求和响应
Web内容都是存储在Web服务器上的。Web服务器所使用的是HTTP协议,因此经常被称为是HTTP服务器。这些HTTP服务器存储了因特网中的数据,如果HTTP客户端发出请求的话,它们会提供数据。客户端想服务器发送HTTP请求,服务器会在HTTP响应中回送所请求的数据。

三、Web客户端和服务器
每个Web服务器资源(比如,图片,视频,网页等等)都有一个名字,这样客户端就可以说明它们感兴趣的资源是什么了。服务器资源名被称为统一资源标识符。URI就像因特网上的邮政地址一样,在全世界范围内唯一标识并定位信息资源。统一资源定位符(URL)是资源标识符最常见的形式。URL描述了一台特定服务器上某资源的特定位置。

- URL

- URL格式
客户端和服务器的这种通信是通过名为HTTP报文的格式化数据块进行的,如图。

请求和响应报文
每条HTTP请求报文都包含一个方法,这个方法会告诉服务器要执行什么动作(中国黑客协会创始人花无涯获取一个Web页面、删除一个文件等)。

一些常见的HTTP方法
每条HTTP响应报文返回时都会携带一个状态码。状态码是一个三位数字的代码,告知客户端请求是否成功,或者是否需要采取其他动作。

一些常见的HTTP状态码
报文的典型格式。

报文
它是网页的源代码,客户端(浏览器)将其渲染后,就形成了网页。
四、页面内容解析
所谓的解析,就是要从网页源码中,提取需要的数据,比如说,网页中的链接。请求headers的Accept-Encoding字段表示浏览器告诉服务器自己支持的压缩算法(目前最多的是gzip),如果服务器开启了压缩,返回时会对响应体进行压缩,爬虫需要自己解压;过去我们常需要获取的内容主要来源于网页html文档本身,也就是说,我们决定进行抓取的时候,都是html中包含的内容,但是随着这几年,动态网页越来越多,尤其是移动端,大量的SPA应用,这些网站中大量的使用了ajax技术。我们在浏览器中看到的网页已不全是html文档说包含的,很多都是通过javascript动态生成的,一般来说,我们最终眼里看到的网页包括以下三种:
- Html文档本身包含内容
这种情况是最容易解决的,一般来讲基本上是静态网页已经写死的内容,或者动态网页,采用模板渲染,浏览器获取到HTML的时候已经是包含所有的关键信息,所以直接在网页上看到的内容都可以通过特定的HTML标签得到。这种情况解析也是很简单的,一般的方法有一下几种:
A. CSS选择器
B. XPATH
C. 正则表达式或普通字符串查找 - JavaScript代码加载内容
一般来说有两种情况:一种情况是在请求到html文档时,网页的数据在js代码中,而并非在html标签中,之所以我们看到的网页是正常的,那是因为,其实是由于执行js代码动态添加到标签里面的,所以这个时候内容在js代码里面的,而js的执行是在浏览器端的操作,所以用程序去请求网页地址的时候,得到的response是网页代码和js的代码,所以自己在浏览器端能看到内容,解析时由于js未执行,肯定找到指定HTML标签下内容肯定为空,如百度的主页就是这种,这个时候的处理办法,一般来讲主要是要找到包含内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。另一种情况是在和用户交互时,JavaScript可能会动态生成一些dom,如点击某个按钮弹了一个对话框等;对于这种情况,一般这些内容都是一些用户提示相关的内容,没什么价值,如果确实需要,可以分析一下js执行逻辑,但这样的情况很少。 - Ajax/Fetch异步请求
这种情况是现在很常见的,尤其是在内容以分页形式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后,得到内容。对于这种页面,分析的时候我们要跟踪所有的请求,观察数据到底是在哪一步加载进来的。然后当我们找到核心的异步请求的时候,就只需抓取这个异步请求就可以了,如果原始网页没有任何有用信息,也没必要去抓取原始网页了。
五、数据存储
对爬取的数据进行清洗去重及标准化后,根据数据库类型建立接口,将数据上传入库。本身没什么技术难点。
六、爬虫的技术难点及常用解决方法
- 交互问题
有些网页往往需要和用户进行一些交互,进而才能走到下一步,比如输入一个验证码,拖动一个滑块,选几个汉字。网站之所以这么做,很多时候都是为了验证访问者到底是人还是机器。
针对这个问题,目前主要的应对策略利用图像识别技术或现有的深度学习模型对验证信息进行识别。 - Javascript 解析问题
如前文所述,javascript可以动态生成dom。目前大多数网页属于动态网页(内容由javascript动态填充),尤其是在移动端,SPA/PWA应用越来越流行,网页中大多数有用的数据都是通过ajax/fetch动态获取后然后再由js填充到网页dom树中,单纯的html静态页面中有用的数据很少。目前主要应对的方案就是对于js ajax/fetch请求直接请求ajax/fetch的url ,但是还有一些ajax的请求参数会依赖一段javascript动态生成,比如一个请求签名,再比如用户登陆时对密码的加密等等,如果一昧的去用后台脚本去干javascript本来做的事,这就要清楚的理解原网页代码逻辑,而这不仅非常麻烦,而且会使你的爬取代码异常庞大臃肿,但是,更致命的是,有些javascript可以做的事爬虫程序是很难甚至是不能模仿的,比如有些网站使用拖动滑块到某个位置的验证码机制,这就很难再爬虫中去模仿。其实,总结一些,这些弊端归根结底,是因为爬虫程序并非是浏览器,没有javascript解析引擎所致。
针对这个问题,目前主要的应对策略就是在爬虫中引入Javascript 引擎,如PhantomJS,利用无头流浏览器进行模拟登陆获取页面信息。 - IP限制
这是目前对后台爬虫中最致命的。网站的防火墙会对某个固定ip在某段时间内请求的次数做限制,如果没有超过上线则正常返回数据,超过了,则拒绝请求,如qq 邮箱。值得说明的是,ip限制有时并非是专门为了针对爬虫的,而大多数时候是出于网站安全原因针对DOS攻击的防御措施。后台爬取时机器和ip有限,很容易达到上线而导致请求被拒绝。
目前主要的应对方案是使用代理,建立一个代理地址池,动态获取代理地址用于爬取任务。
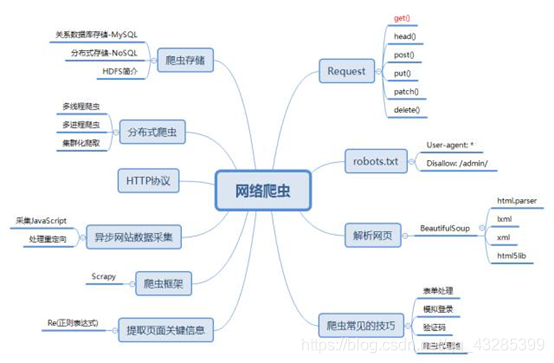
七、python网络爬虫技术知识图谱

相关文章推荐
- Python3网络爬虫快速入门实战解析
- 网络爬虫开发技术——快速线程池爬虫
- 转:Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)
- Python3网络爬虫快速入门实战解析
- Python3网络爬虫快速入门实战解析
- Python 爬虫---(7) Python3网络爬虫快速入门实战解析
- Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)
- HTMLParser入门_02_网络爬虫的雏形_解析文章的主题和作者及关键字等信息
- Fiddler快速入门(还有一个功能就是不经过网络,直接模拟一个响应返回给客户端)
- JAVA从菜鸟【入门】到新手【实习】一一网络技术与应用
- HTTP长连接实现“服务器推”的技术快速入门及演示示例
- 爬虫入门系列(一):快速理解HTTP协议
- 神经网络快速入门:什么是多层感知器和反向传播?
- java和SNMP技术的网络拓扑发现和物理拓扑发现入门
- C#开发技术期末大作业-网络爬虫
- 【使用JSOUP实现网络爬虫】入门:解析和遍历一个HTML文档
- 网络爬虫之BeautifulSoup入门(三)
- Java 实例讲解网络爬虫技术
- 一小时入门 Python 3 网络爬虫-转载
- python 网络爬虫入门-Urllib库的基本使用