Kafka架构、Kafka核心组件、Kafka工作原理、Kafka应用场景
什么是消息系统?
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。 分布式消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用 - 一种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。 大多数消息模式遵循 pub-sub 。
一、Kafka 简介
(1)、Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
(2)、Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
(3)、Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
(4)、Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
(5)、无论是Kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
Kafka凭借着自身的优势,越来越受到互联网企业的青睐,唯品会也采用Kafka作为其内部核心消息引擎之一。Kafka作为一个商业级消息中间件,消息可靠性的重要性可想而知。先了解下Kafka的基本原理,然后通过对kakfa的存储机制、复制原理、同步原理、可靠性和持久性保证等等一步步对其可靠性进行分析,最后通过benchmark来增强对Kafka高可靠性的认知。
我们需要理解发布订阅消息的概念及其重要性。需要注意发布-订阅消息队列的特征是消息的sender(publisher)并不直接将data(message)发送给receiver, publisher 以某种方法对消息进行分类,而receiver (subscriber) 会订阅接收特定类别的消息。Pub/Sub 系统通常会有broker(消息被发布到的中心点)来进行实现,消息将被发送至broker。
二、Kafka 特性
(1)、多个生产者
无论kafka 多个生产者的客户端正在使用很多topic 还是同一个topic ,Kafka 都能够无缝处理好这些生产者。这使得kafka 成为一个从多个前端系统聚合数据,然后提供一致的数据格式的理想系统. 例如, 一个通过多个微服务向用户提供内容的站点, 可以为统计page view 而只设立一个topic, 所有的服务将pageview 以统一的格式写入这个topic. 消费程序能够以统一的数据格式来接收page view 数据, 而不需要去协调多个生产者流。
(2)、多个消费者
除了多个生产者之外,kafka 也被设计为多个消费者去读取任意的单个消息流而不相互影响;而其他的很多消息队列系统,一旦一个消息被一个客户端消费,那么这个消息就不能被其他客户端消费,这是kafka 与其他队列不同的地方;同时多个kafka 消费者也可以选择作为一个组的一部分,来分担一个消息流,确保这整个组,这个消息只被消费一次。
(3)、基于硬盘的消息保存
Kafka 不仅能够处理多个消费者,而且能够持久的保存消息这也意味着消费者不一定需要实时的处理数据。消息将按照持久化配置规则存储在硬盘上。这个可以根据每个topic 进行设置,允许根据不同的消费者的需求不同 设置不同消息流的保存时间不同, 持久化保存意味着一旦消费者来不及消费或者突然出现流量高峰, 而不会有丢失数据的风险.同样也意味着消息可以由consumer 来负责管理, 比如消费消息掉线了一段时间,不需要担心消息会在producer 上累积或者消息丢失, consumer 能够从上次停止的地方继续消费。
(4)、可扩展性
Kafka 最开始设计的时候就把灵活扩展考虑到里面,使其能够处理任意数量的数据;用户刚开始可以用一台进行验证其相关的理念,然后将其扩展成小的三台broker 的开发集群,随着数据的增加,甚至扩展为数十台,上百台规模的大集群。扩展可以在集群正常运行的时候进行,对于整个系统的运作没有影响;这也就意味着,对于很多台broker 的集群,如果一台broker 有故障,不影响为client 提供服务.集群如果要同时容忍更多的故障的话, 可以配置更高的replication factors。
(5)、高性能
上面的这些特性使得Apache Kafka 成为一个能够在高负载的情况下表现出优越性能的发布-订阅消息系统。Producer, consumer 和broker 都能在大数据流的情况下轻松的扩展. 扩展过程能够在依然提供从生产到消费亚秒级服务的情况下完成。
三、Kafka 核心组件
深入学习Kafka之前,必须了解主题(Topic)、经纪人(Broker)、生产者(Producer)或者发布者,以及消费者(Consumer)或者订阅者等主要术语
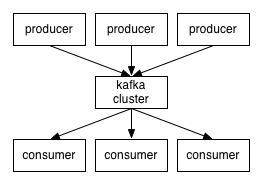
Topic:每一类消息的主题,Kafka将消息按照主题分类
Producer:发送消息者
Consumer:消费消息者(必须订阅后才可以消费,一个消费者可以消费1个或多个主题)
broker:发送的消息保存在一组服务器上,称之为Kafka集群,集群中的每一个Kafka就是一个blocker
四、Kafka的使用场景
(1)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
(6)事件源;

- Spring的工作原理核心组件和应用
- 架构设计:系统间通信(29)——Kafka及场景应用(中2)
- 架构设计:系统间通信(28)——Kafka及场景应用(中1)
- 架构设计:系统间通信(28)——Kafka及场景应用(中1)
- 架构设计:系统间通信(30)——Kafka及场景应用(中3)
- Kafka 架构原理、应用场景
- 架构设计:系统间通信(29)——Kafka及场景应用(中2)
- android 应用五大核心组件之三(Intent)
- 架构设计:系统间通信(33)——其他消息中间件及场景应用(下3)
- 核心应用组件(转载)
- Flume架构与源码分析-核心组件分析
- Android零基础入门第2节:Android 系统架构和应用组件那些事
- 【Hadoop系列第六章】HBase应用场景、原理与基本架构
- Yii学习——-核心应用组件
- 重新认识分层架构(现代企业级应用分层架构核心设计要素)
- ELK架构体系、ELK运行原理、ELK应用场景、ELK简单介绍(一)
- 浅析jQuery核心架构中应用Closure的设计模式
- Android层次化安全架构及核心组件概览
- flume架构与核心组件源代码分析
- http协议、Web架构, RESTFUL API及互联网应用的工作原理