2.逻辑型数据库设计反模式-单纯的树(有层级的数据存储)
目录:
一.邻接表-最方便的设计
添加parent_id来关联父子关系
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, parent_id BIGINT UNSIGNED, -- 关键 bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (parent_id) REFERENCES Comments(comment_id), FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id) );
1.1.邻接表.查询问题
-
查询两层数据(问题不大)
SELECT c1.*, c2.* FROM Comments c1 LEFT OUTER JOIN Comments c2 ON c2.parent_id = c1.comment_id;
-
任意深度查询(问题很大)
SELECT c1.*, c2.*, c3.*, c4.* FROM Comments c1 -- 1st level LEFT OUTER JOIN Comments c2 ON c2.parent_id = c1.comment_id -- 2nd level LEFT OUTER JOIN Comments c3 ON c3.parent_id = c2.comment_id -- 3rd level LEFT OUTER JOIN Comments c4 ON c4.parent_id = c3.comment_id; -- 4th level
存在问题:1.查询不优雅,每增加一层需要额外拓展一个联接(sql的联接是有上限的)2.执行聚合函数也麻烦。
-
另外一种获取树结构的方法
查询出所有的行,通过应用程序来重构这棵树,再像树一样来使用。
SELECT * FROM Comments WHERE bug_id = 1234;
存在问题:在数据库和引用程序之前需要进行大量的复制,效率低下。如果仅仅是查询一个子树或者是一次聚合信息(eg:COUNT()),大材小用。
1.2.邻接表.添加,修改,删除问题
-
[优势]添加修改节点
-- 添加超级方便 INSERT INTO Comments (bug_id, parent_id, author, comment) VALUES (1234, 7, 'Kukla', 'Thanks!');
--修改也是超级简单 UPDATE Comments SET parent_id = 3 WHERE comment_id = 6;
-
[劣势]删除节点完蛋
SELECT comment_id FROM Comments WHERE parent_id = 4; -- returns 5 and 6 SELECT comment_id FROM Comments WHERE parent_id = 5; -- returns none SELECT comment_id FROM Comments WHERE parent_id = 6; -- returns 7 SELECT comment_id FROM Comments WHERE parent_id = 7; -- returns none DELETE FROM Comments WHERE comment_id IN ( 7 ); DELETE FROM Comments WHERE comment_id IN ( 5, 6 ); DELETE FROM Comments WHERE comment_id = 4;
存在问题: 1.删除一棵子树的时候,需要查询所有的后代节点,从最低级别通过外键约束来逐个删除。2.如果删除一个非叶子节点并且提升它的子节点,或者做子节点移动的时候,都需要先修改子节点的parent_id。
1.3.邻接表.总结:
邻接表适用于插入修改频繁,查询少的情况。给定节点获取可以快速获取父节点的情况(层级较少的情况)。
注: 如果数据库支持WITH或者CONNECT BY PRIOR的递归查询,邻接表的查询会高效很多。
二.路径枚举-最直观的设计
用一个字段来保存层级关系的完整路径
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, path VARCHAR(1000), -- 1/2/3/4/ bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id) );
.png)
2.1.[优势]查询节点的祖先元素
SELECT * FROM Comments AS c WHERE '1/4/6/7/' LIKE c.path || '%';
2.2.[优势]查询指定节点的所有后代
方便一系列的数据统计和聚合函数的使用。
SELECT * FROM Comments AS c WHERE c.path LIKE '1/4/' || '%';1b5d7 [/code]
2.3.[优势]做插入和修改
只是简简单单的添加或者更新一下path路径即可。
INSERT INTO Comments (author, comment) VALUES ('Ollie', 'Good job!');
UPDATE Comments
SET path = (SELECT path FROM Comments WHERE comment_id = 7)
|| LAST_INSERT_ID() || '/'
WHERE comment_id = LAST_INSERT_ID();
2.4.[劣势]乱穿马路
把多个字段通过符号分割,放在一个字段里,就会有乱穿马路的问题。
1.3.路径枚举.总结:
路径枚举能够很直观地展示出祖先到后代之间的路径。但是由于它不能确保引用完整性,使得这个设计非常的脆弱。枚举路径由于乱穿马路的问题,使得数据的存储变得非常的冗余。
三.嵌套集-最复杂的设计
@From:博客-MySQL实现嵌套集合模型
嵌套集解决方案是存储子孙节点的相关信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,从而表示这一信息,可以将这两个数字称为nsleft 和 nsright。
每个节点通过如下的方式确定nsleft 和nsright 的值:nsleft的数值小于该节点所有后代ID,同时nsright 的值大于该节点的所有后代的ID。这些数字和comment_id的值并没有任何关联。
确定这三个值(nsleft,comment_id,nsright)的简单方法是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值
[比较不好理解]是个难点
CREATE TABLE nested_category ( category_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, lft INT NOT NULL, rgt INT NOT NULL ); INSERT INTO nested_category VALUES (1,'ELECTRONICS',1,20), (2,'TELEVISIONS',2,9), (3,'TUBE',3,4), (4,'LCD',5,6), (5,'PLASMA',7,8), (6,'PORTABLE ELECTRONICS',10,19), (7,'MP3 PLAYERS',11,14), (8,'FLASH',12,13), (9,'CD PLAYERS',15,16), (10,'2 WAY RADIOS',17,18); SELECT * FROM nested_category ORDER BY category_id; +-------------+----------------------+-----+-----+ | category_id | name | lft | rgt | +-------------+----------------------+-----+-----+ | 1 | ELECTRONICS | 1 | 20 | | 2 | TELEVISIONS | 2 | 9 | | 3 | TUBE | 3 | 4 | | 4 | LCD | 5 | 6 | | 5 | PLASMA | 7 | 8 | | 6 | PORTABLE ELECTRONICS | 10 | 19 | | 7 | MP3 PLAYERS | 11 | 14 | | 8 | FLASH | 12 | 13 | | 9 | CD PLAYERS | 15 | 16 | | 10 | 2 WAY RADIOS | 17 | 18 | +-------------+----------------------+-----+-----+
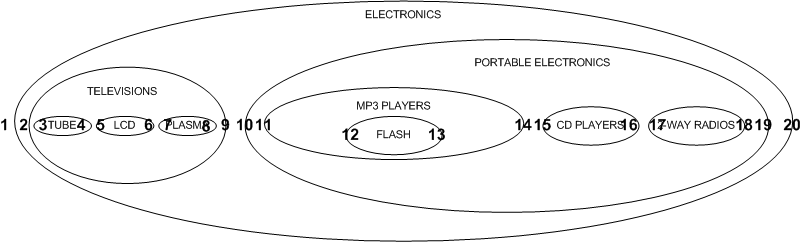
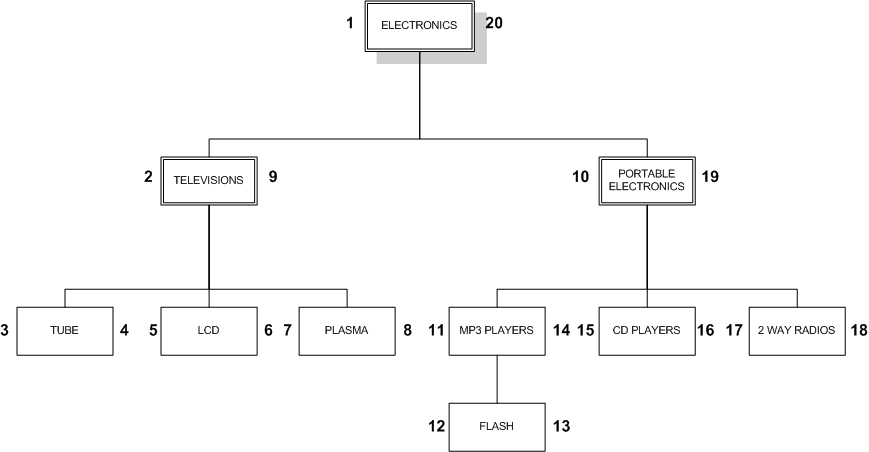
3.1.[优势]检索分层路径
由于子节点的lft值总在父节点的lft和rgt值之间,所以可以通过父节点连接到子节点上来检索整棵树。
SELECT node.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND parent.name = 'ELECTRONICS' ORDER BY node.lft; +----------------------+ | name | +----------------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +----------------------+</pre>
这个方法并不需要考虑层数,而且不需要考虑节点的rgt。
3.2.[优势]检索所有叶子节点
由于每一个叶子节点的rgt=lft+1,那么只需要这一个条件即可。
SELECT name FROM nested_category WHERE rgt = lft + 1; +--------------+ | name | +--------------+ | TUBE | | LCD | | PLASMA | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +--------------+
3.3.[优势]检索节点路径
不再需要多个join连接操作。
SELECT parent.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'FLASH' ORDER BY node.lft; +----------------------+ | name | +----------------------+ | ELECTRONICS | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | +----------------------+
3.4.[优势]检索节点深度
通过
COUNT和
GROUP BY函数来获取父节点的个数。
SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | ELECTRONICS | 0 | | TELEVISIONS | 1 | | TUBE | 2 | | LCD | 2 | | PLASMA | 2 | | PORTABLE ELECTRONICS | 1 | | MP3 PLAYERS | 2 | | FLASH | 3 | | CD PLAYERS | 2 | | 2 WAY RADIOS | 2 | +----------------------+-------+
3.4.[优势]分层的缩进
SELECT CONCAT( REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+-----------------------+
3.5.[优势]检索子树的深度
考虑到检索中需要自连接的
node或
parent,因此需要增加一个额外的连接来作为子查询来限制子树。
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | PORTABLE ELECTRONICS | 0 | | MP3 PLAYERS | 1 | | FLASH | 2 | | CD PLAYERS | 1 | | 2 WAY RADIOS | 1 | +----------------------+-------+
3.6.[优势]检索节点的直接子节点
假设一个场景,当用户点击网站上电子产品的一个分类时,将呈现该分类下的产品,同时需要列出所有子分类,并不是全部分类。
为了限制显示分类的层数,需要使用
HAVING字句.
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name HAVING depth <= 1 ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | PORTABLE ELECTRONICS | 0 | | MP3 PLAYERS | 1 | | CD PLAYERS | 1 | | 2 WAY RADIOS | 1 | +----------------------+-------+
3.7.嵌套集.总结:
嵌套集是一种复杂得方案,适合在对查询性能要求很高而且对其他要求一般得场合来使用。
由于嵌套集的插入和移动节点比较复杂,需要重新分配左右值,它不适合频繁的插入和删除节点的情况。
四.闭包表-最通用的设计
闭包表是解决分级存储的一个简单而优雅的解决方案,它记录了树中所有节点间的关系,而不仅仅只有那些直接的父子节点。是一种空间换时间的解决方案。
创建评论表的同时,在单独创建一张树的节点表来储存节点关系。
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, bug_id BIGINT UNSIGNED NOT NULL, author BIGINT UNSIGNED NOT NULL, comment_date DATETIME NOT NULL, comment TEXT NOT NULL, FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id), FOREIGN KEY (author) REFERENCES Accounts(account_id) ); CREATE TABLE TreePaths ( ancestor BIGINT UNSIGNED NOT NULL, descendant BIGINT UNSIGNED NOT NULL, PRIMARY KEY(ancestor, descendant), FOREIGN KEY (ancestor) REFERENCES Comments(comment_id), FOREIGN KEY (descendant) REFERENCES Comments(comment_id) );
4.1.[优势]闭包表处理CRUD操作
-
查询:
-- eg:查询所有的子节点: SELECT c.* FROM Comments AS c JOIN TreePaths AS t ON c.comment_id = t.descendant WHERE t.ancestor = 4;
--eg:查询所有的父节点 SELECT c.* FROM Comments AS c JOIN TreePaths AS t ON c.comment_id = t.ancestor WHERE t.descendant = 6;
-
插入
--eg:插入id为5的一个新节点 INSERT INTO TreePaths (ancestor, descendant) SELECT t.ancestor, 8 FROM TreePaths AS t WHERE t.descendant = 5 UNION ALL SELECT 8, 8;
-
删除
--eg:删除一个叶子节点为7的数据 DELETE FROM TreePaths WHERE descendant = 7;
--eg:删除一棵完整的树(删除id为4以及所有的后代) DELETE FROM TreePaths WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = 4);
4.2.闭包表.总结:
- 闭包表的设计比嵌套集更加的直接,两者都能快捷地查询给定节点的祖先和后代,但是闭包表能更加简单地维护分层信息。这两个设计都比使用邻接表或者路径枚举更方便地查询给定节点的直接后代和祖先。
- 闭包表是最通用的设计,并且以上的方案也只有它能允许一个节点属于多棵树。它要求一张额外的表来存储关系,使用空间换时间的方案减少操作过程中由冗余的计算所造成的消耗。

- 文档型数据库设计模式-如何存储树形数据
- [ mongoDB ] - 文档型数据库设计模式-如何存储树形数据 [转]
- [ mongoDB ] - 文档型数据库设计模式-如何存储树形数据
- 文档型数据库设计模式-如何存储树形数据
- 文档型数据库设计模式-如何存储树形数据
- 第16天(就业班) 数据约束、数据库设计、关联查询、存储过程、权限和备份
- 对数据库数据操作,工厂方法设计模式(Factory Method)
- [数据库]数据库存储层级结构数据
- 逻辑数据库设计 - 单纯的树(递归关系数据)
- 设计模式知识连载(39)---数据访问对象模式---本地存储DAO
- 用JAVA如何实现每天1亿条记录的数据存储,数据库方面怎么设计?
- 数据库的动态数据存储设计
- 存储动态数据时,数据库的设计方法
- 逻辑数据库设计 - 单纯的树(递归关系数据)
- 逻辑数据库设计 - 单纯的树(递归关系数据)
- 树形结构的数据存储和数据库表设计
- 工厂设计模式 - 数据存储的特有方式
- 动态产生的持久模型和数据存储的设计模式
- 如何设计一个数据库中间件(支持百亿级别数据存储)
- php 设计模式-数据映射模式(应用程序与数据库交互模式)