什么是大数据
- 什么是大数据
进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB(1MB大约等于一百万字节)、GB(1024MB)、TB(1024GB),一直向上攀升,目前,PB(等于1024TB)级的数据系统已经很常见,随着移动个人数据、社交网站、科学计算、证券交易、网站日志、传感器网络数据量的不断加大,国内拥有的总数据量早已超出 ZB(1ZB=1024EB,1EB=1024PB)级别。
传统的数据处理方法是:随着数据量的加大,不断更新硬件指标,采用更加强大的CPU、更大容量的磁盘这样的措施,但现实是:数据量增大的速度远远超出了单机计算和存储能力提升的速度。
而“大数据”的处理方法是:采用多机器、多节点的处理大量数据方法,而采用这种新的处理方法,就需要有新的大数据系统来保证,系统需要处理多节点间的通讯协调、数据分隔等一系列问题。
总之,采用多机器、多节点的方式,解决各节点的通讯协调、数据协调、计算协调问题,处理海量数据的方式,就是“大数据”的思维。其特点是,随着数据量的不断加大,可以增加机器数量,水平扩展,一个大数据系统,可以多达几万台机器甚至更多。
- hadoop概述
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用Java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。
Hadoop框架中最核心设计就是:HDFS和MapReduce。HDFS提供了海量数据的存储,MapReduce提供了对数据的计算。
Hadoop的发行版除了社区的Apache hadoop外,cloudera,hortonworks,IBM,INTEL,华为,大快搜索等等都提供了自己的商业版本。商业版主要是提供了专业的技术支持,这对一些大型企业尤其重要。DK.Hadoop是大快深度整合,重新编译后的HADOOP发行版,可单独发布。独立部署FreeRCH(大快大数据一体化开发框架)时,必需的组件。DK.HADOOP整合集成了NOSQL数据库,简化了文件系统与非关系数据库之间的编程;DK.HADOOP改进了集群同步系统,使得HADOOP的数据处理更加高效。
- hadoop开发技术详解
1、Hadoop运行原理
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:MapReduce和HDFS。基于Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。
基于MapReduce计算模型编写分布式并行程序相对简单,程序员的主要工作就是设计实现Map和Reduce类,其它的并行编程中的种种复杂问题,如分布式存储,工作调度,负载平衡,容错处理,网络通信等,均由MapReduce框架和HDFS文件系统负责处理,程序员完全不用操心。换句话说程序员只需要关心自己的业务逻辑即可,不必关心底层的通信机制等问题,即可编写出复杂高效的并行程序。如果说分布式并行编程的难度足以让普通程序员望而生畏的话,开源的Hadoop的出现极大的降低了它的门槛。
- Mapreduce原理
Map-Reduce的处理过程主要涉及以下四个部分:
•Client进程:用于提交Map-reduce任务job;
•JobTracker进程:其为一个Java进程,其main class为JobTracker;
•TaskTracker进程:其为一个Java进程,其main class为TaskTracker;
•HDFS:Hadoop分布式文件系统,用于在各个进程间共享Job相关的文件;
其中JobTracker进程作为主控,用于调度和管理其它的TaskTracker进程, JobTracker可以运行于集群中任一台计算机上,通常情况下配置JobTracker进程运行在NameNode节点之上。TaskTracker负责执行JobTracker进程分配给的任务,其必须运行于DataNode上,即DataNode既是数据存储结点,也是计算结点。JobTracker将Map任务和Reduce任务分发给空闲的TaskTracker,让这些任务并行运行,并负责监控任务的运行情况。如果某一个TaskTracker出故障了,JobTracker会将其负责的任务转交给另一个空闲的TaskTracker重新运行。
3、HDFS存储的机制
Hadoop的分布式文件系统HDFS是建立在Linux文件系统之上的一个虚拟分布式文件系统,它由一个管理节点( NameNode )和N个数据节点( DataNode )组成,每个节点均是一台普通的计算机。在使用上同我们熟悉的单机上的文件系统非常类似,一样可以建目录,创建,复制,删除文件,查看文件内容等。但其底层实现上是把文件切割成Block(块),然后这些Block分散地存储于不同的DataNode上,每个Block还可以复制数份存储于不同的DataNode上,达到容错容灾之目的。NameNode则是整个HDFS的核心,它通过维护一些数据结构,记录了每一个文件被切割成了多少个Block,这些Block可以从哪些DataNode中获得,各个DataNode的状态等重要信息。
HDFS的数据块
每个磁盘都有默认的数据块大小,这是磁盘进行读写的基本单位.构建于单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块.该文件系统中的块一般为磁盘块的整数倍.磁盘块一般为512字节.HDFS也有块的概念,默认为64MB(一个map处理的数据大小).HDFS上的文件也被划分为块大小的多个分块,与其他文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间.
任务粒度——数据切片(Splits)
把原始大数据集切割成小数据集时,通常让小数据集小于或等于HDFS中一个Block的大小(缺省是64M),这样能够保证一个小数据集位于一台计算机上,便于本地计算。有M个小数据集待处理,就启动M个Map任务,注意这M个Map任务分布于N台计算机上并行运行,Reduce任务的数量R则可由用户指定。
HDFS用块存储带来的第一个明显的好处一个文件的大小可以大于网络中任意一个磁盘的容量,数据块可以利用磁盘中任意一个磁盘进行存储.第二个简化了系统的设计,将控制单元设置为块,可简化存储管理,计算单个磁盘能存储多少块就相对容易.同时也消除了对元数据的顾虑,如权限信息,可以由其他系统单独管理。
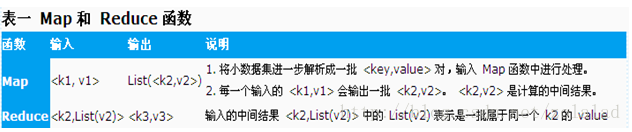
4、举一个简单的例子说明MapReduce的运行机制
以计算一个文本文件中每个单词出现的次数的程序为例,<k1,v1>可以是<行在文件中的偏移位置,文件中的一行>,经Map函数映射之后,形成一批中间结果<单词,出现次数>,而Reduce函数则可以对中间结果进行处理,将相同单词的出现次数进行累加,得到每个单词的总的出现次数。
|
5、MapReduce的核心过程----Shuffle['ʃʌfl]和Sort
shuffle是mapreduce的心脏,了解了这个过程,有助于编写效率更高的mapreduce程序和hadoop调优。
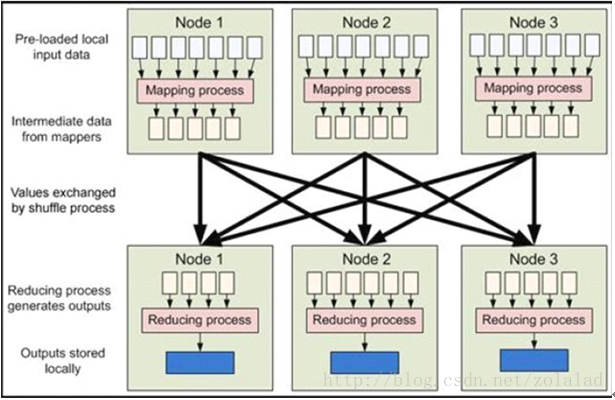
Shuffle是指从Map产生输出开始,包括系统执行排序以及传送Map输出到Reducer作为输入的过程。如下图所示:
|
首先从Map端开始分析,当Map开始产生输出的时候,他并不是简单的把数据写到磁盘,因为频繁的操作会导致性能严重下降,他的处理更加复杂,数据首先是写到内存中的一个缓冲区,并作一些预排序,以提升效率,如图:

每个Map任务都有一个用来写入“输出数据”的“循环内存缓冲区”,这个缓冲区默认大小是100M(可以通过io.sort.mb属性来设置具体的大小),当缓冲区中的数据量达到一个特定的阀值(io.sort.mb * io.sort.spill.percent,其中io.sort.spill.percent默认是0.80)时,系统将会启动一个后台线程把缓冲区中的内容spill到磁盘。在spill过程中,Map的输出将会继续写入到缓冲区,但如果缓冲区已经满了,Map就会被阻塞直到spill完成。spill线程在把缓冲区的数据写到磁盘前,会对他进行一个二次排序,首先根据数据所属的partition排序,然后每个partition中再按Key排序。输出包括一个索引文件和数据文件,如果设定了Combiner,将在排序输出的基础上进行。Combiner就是一个Mini Reducer,它在执行Map任务的节点本身运行,先对Map的输出作一次简单的Reduce,使得Map的输出更紧凑,更少的数据会被写入磁盘和传送到Reducer。Spill文件保存在由mapred.local.dir指定的目录中,Map任务结束后删除。
每当内存中的数据达到spill阀值的时候,都会产生一个新的spill文件,所以在Map任务写完他的最后一个输出记录的时候,可能会有多个spill文件,在Map任务完成前,所有的spill文件将会被归并排序为一个索引文件和数据文件。如图3所示。这是一个多路归并过程,最大归并路数由io.sort.factor控制(默认是10)。如果设定了Combiner,并且spill文件的数量至少是3(由min.num.spills.for.combine属性控制),那么Combiner将在输出文件被写入磁盘前运行以压缩数据。
大快大数据平台(DKH),是大快公司为了打通大数据生态系统与传统非大数据公司之间的通道而设计的一站式搜索引擎级,大数据通用计算平台。传统公司通过使用DKH,可以轻松的跨越大数据的技术鸿沟,实现搜索引擎级的大数据平台性能。
- DKH,有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。
- DKH,更是通过大快独有的中间件技术,将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
- DKH,虽然进行了高度的整合,但是仍然保持了开源系统的全部优点,并与开源系统100%兼容,基于开源平台开发的大数据应用,无需经过任何改动,即可在DKH上高效运行,并且性能会有最高5倍的提升。
DKH标准平台技术构架图

|

- 数据的黑暗陷阱是什么?——你想要一匹更快的马,还是一辆汽车?
- MYSQL存储经纬度使用什么数据类型
- 什么叫精粒度对象模型,什么叫粗粒度关系数据模型?
- JAVA 中的几种基本数据类型是什么,各自占用多少字节。
- 什么是互联网数据中心及它是如何工作?
- 每日刷题(2015/6/21):对比哈希表和STL map。哈希表是怎么实现的?如果输入数据规模不大, 可以使用什么数据结构来代替哈希表。
- 怎么理解什么是大数据呢?
- 什么是JSON数据
- 数据分析和数据挖掘之间,主要有什么关系?
- “全民K歌”有什么秘密?网站数据分析之数据的获取
- MySQL 中你应该使用什么数据类型表示时间?
- C#中什么是元数据类型
- uint8_t / uint16_t / uint32_t /uint64_t 是什么数据类型
- 大数据主要学什么,学习大数据你要会什么
- 一句话告诉你们什么是大数据
- 怎么理解VUE,VUE的数据驱动原理是什么,解释MVVM框架
- 【数字智能三篇】之一: 一页纸说清楚“什么是大数据”
- [SICP]数据意味着什么?
- 用数据告诉你到顶尖投行工作,究竟应该读什么专业
- 《Data Mining》学习——可以挖掘什么类型的数据?