PRIME:一种在RRAM-based主存中进行神经网络计算的存算融合结构
传统的计算机系统中,数据的计算和存储是分开的,分别在CPU和memory中。大量的数据从memory传输到cpu非常耗能并造成了瓶颈。很多研究针对这问题提出了方案,但大多数是通过将存储芯片集成到CPU上来减少数据传输。在神经网络计算中,这一做法虽然减少了突触权重的传输,却没有减少输入/出数据的传输。本文即是解决这一问题。不同于以往的做法,本文提出一种新思路:使memory具有计算功能。
文章提出的新存算融合结构叫做PRIME,其本质是RRAM crossbar array,其特别之处在于这个array按照其eNVM单元的功能被分为三个子阵列:FF array、Mem array、Buffer array。在FF array中每个单元可以作为神经网络的加速器,又可在不需要计算的时候作为普通存储单元。其转换由特别设计的外围电路实现。这样一来,PRIME的优势就很明显了:不需要特别的处理器和复杂的集成技术,其结构设计就是普通的存储器设计,故费用低;使用了存算融合结构和具有高效神经网络计算功能的RRAM。
除了介绍PRIME主要结构和电路之外,还提出了克服精度问题(本设计的主要挑战)的方法,并且设计软/硬件的接口以便软件开发者设置FF array以应用各种神经网络。各个阵列在下面会详细介绍。

神经网络在硬件上的加速
神经网络有一个输入层、一输出层、若干夹在中间的隐层。每一层上的是神经元,神经元有自己值。神经元与神经元之间传递信息时有突触权重。示意图如下

反应到硬件上如下图。
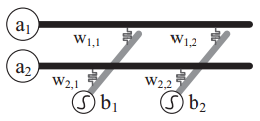
阵列的行的起始端代表输入层,列的末端代表输出层,RRAM单元的电导率是突触权重。输入信号即是输入的模拟电压,输出信号是每列的电流经过激活函数处理后的值,突触权重直接编程到每个单元中。
要用RRAM crossbar array实现神经网络,要有上文提到的专门设计的外围电路(例如模拟计算中的ADC、DAC),还要有sigmoid函数单元和减法单元。
PRIME结构
PRIME结构中有一个控制器,它会控制计算模式和存储模式,并对FF子阵列进行相应的设置。选择距离FF和全局行Buffer(Global row buffer)比较近的memory子阵列作为Buffer子阵列,Buffer通过数据口与FF连接,给FF传数据时不占用Mem的带宽。Buffer阵列的单元在不作为缓存时也可作为memory单元。
FF子阵列
FF的数据移动都是在存储器内的,故可使用的带宽非常宽,并且可以和cpu并行工作。一个FF subarray被分成两个array,一个用来存放负权重,一个存放正权重,这两个array共用一个输入口。
FF根据NN计算的要求对外围电路做了一些修改,详细的讲解可以参考论文:
①NN计算要求所有的数据都同步输入到字线上,故WDD中加入了锁存器;每条字线上都有电流放大器;WDD需要一个多路复用器,在存储模式时只提供两个电平,在计算模式下提供2Pin 个电平。Pin为输入数据bit数。
②列复用器中加入了sigmoid函数单元和减法单元。每个FF array里有两套列复用器,只需要在其中的一副上做上述修改。电压分别与正、负权重进行计算后,通过减法器做减法,得到的电流在通过sigmoid进行归一化,再在SA中进行检测,最后存回到Buffer中。但当一层输出是下一层输入时,可跳过Buffer。
③SA的精度要求比存储器高,精度为输出比特数Po,该设计通过在SA中加入counter实现精度1~Po的调节。对于输入SA的数据,若大于0,则SA直接输出其值,若小于0则输出0。
④Buffer和FF之间有连接单元,连接单元里很多解码器和复用器以保证FF可以访问任何Buffer的物理地址。
从上述电路设计可以看出,存储和计算使用了相同的电路,减少了面积开销。例如SA和WDD的存在就使得DAC和ADC不必要了。
FF在计算和存储模式下数据的流动路径不同。
计算模式下:FF从Buffer中取数据到锁存器,锁存器将数据分别送到正负array中,经过计算后的两路电流到减法器,得到的结果送入sigmoid进行归一化,归一化后的数据送入SA检测,得到的最终数据存回Buffer
存储模式下:所有单元都被设置成普通的存储单元,数据直接输入->存储->检测->存入总Buffer。
当FF又存储模式设置为计算模式时,其单元内存储的数据会先转移到特定分配的Mem array中,再把突触权重写入FF单元中。当这些工作完毕,PRIME控制器将外围电路设置为计算模式,FF开始计算。当计算结束后,FF又被设置回存储模式。
Buffer子阵列
Buffer作用是缓存FF array的输入输出数据。RRAM进行计算并不花费时间,是数据在存取上的延迟花费时间。所以把输入输出放入缓存是很有必要的。
Buffer中的数据一是来自于GRB,作为FF array的输入。二是来自FF array,缓存它的输出。GRB中的数据来自Mem subarray。所以计算模式下数据的移动可以表示为:
Mem subarray<—①—>GRB<—②—>Buffer array<—③—>FF array
其中过程①和③是相互独立的,但①和②必须按照次序,而不可同时进行。
PRIME 控制器
控制器负责给出指令。指令分为设置路径指令和数据流动指令。设置路径指令其实就是设置计算模式或存储模式,该指令只在每次设置FF array时执行一次。数据流动指令即指数据在mem\buf\FF之间的传递,这种指令贯穿整个计算过程。
精度问题
假如输入为Pin bit 权重为Pw bit 输出为Po bit。它们所代表的意思是,输入电平有2Pin 个level,权重有2Pw 个level,输出取前Po bit,PN表示输入总数。在最先进的技术中,一个比较可行的设定是:Pin=3 bit,Pw=4bit,Po=6bit。本文采用input and synapse composing 方案(实在不知道怎么翻译…不过这才是要多阅读文献的原因,在学术写作上英文比中文表达更有力^ _^),用保守的设定来实现高计算精度。
方案详述
首先,输入信号和突触权重都被分成高bit部分和低bit部分,分别串行地存入相应的阵列中。计算直接得到的精度是全精度Rfull,目标精度为Rtar,两者相等。根据不同高、低bit输入和权重的组合,Rfull被分为了四个部分,HH、HL、LH、LL,相应的,Rtar也被分为了四个部分。Rtar的精度取决于Po。Rfull的HH部分取Po比特 作为Rtar的HH部分,HL取Po-Pin/2比特,LH取Po-Pw/2比特,LL取Po-(Pin+Pw)/2。此处LL可能出现负值,但前面说过,SA对于负值会输出0。
下面是计算过程:
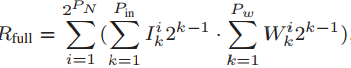
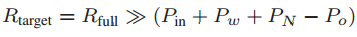
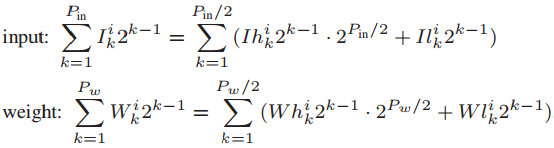

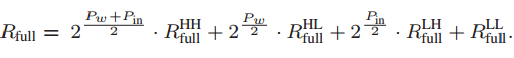

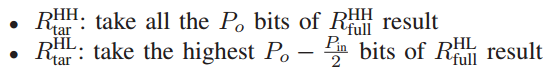

在crossbar上实现NN算法
前面所述的一切是MLP神经网络算法。
稍作变换可以实现卷积层算法,即将下式映射到crossbar array上:
其中finj 是输入特征映射,fouti是输出特征映射,gi,j是第j个输入和第i输出的卷积核,bi为偏置。就像突触权重一样,gi,j被串行编入到一列中(多列的话操作比较复杂,这里假设一列就能容纳所有卷积核),bi也被编入。然后再进行计算。
还可以实现Pooling layer
文章介绍了max pooling(输出最大值)和mean pooling(输出均值)。
max pooling:本文采用4:1 max pooling,即从4个数据中选出最大值。但它也可以通过多次操作实现n:1,n>4。其原理是将数据两两相减,并把得到的正负号存入winner code存储器,最后电路检测并输出最大值。反应到矩阵上是将{ai}向量与编入RRAM单元的做点积。
mean pooling简单得多,将{1/n,…1/n}编入RRAM单元,然后进行上述点积运算。
PRIME目前不能加速局部响应归一化层(LRN),需要借助CPU进行计算。没有查到多少关于这个层的资料,因为这个层的作用似乎不大,并且已经逐渐被其他技术代替了。[1]
引用注释
[1]https://www.geek-share.com/detail/2676712890.html 作者:江洋大盗与鸭子
阅读更多
- 使用 json 进行神经网络结构信息的格式化 (dump & load)
- 采用神经网络进行城市中长期负荷预测的一种信息系统
- 使用Matlab结合神经网络模型对多波段影像进行计算
- NLP多任务学习:一种层次增长的神经网络结构 | PaperDaily #16
- 神经网络卷积结构及计算过程
- 深度学习与计算机视觉系列(6)_神经网络结构与神经元激励函数
- 神经进化:一种不一样的深度学习——通过进化算法来探求神经网络的进化
- 深度学习与计算机视觉系列(6)_神经网络结构与神经元激励函数
- 类脑计算与神经网络加速
- 神经网络中的激活函数——加入一些非线性的激活函数,整个网络中就引入了非线性部分,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,但是 ReLU 并不需要输入归一化
- CNN学习笔记(二)卷积神经网络经典结构
- 利用MATLAB 2016a进行BP神经网络的预测(含有神经网络工具箱)
- 【深度学习】在Caffe中配置神经网络的每一层结构
- 基于遗传算法优化神经网络结构源程序
- 【一个批量计算的调度系统的设计与实现】如果需要对成千上万的网络抓包数据文件在规定的时间内进行解析,应该怎么做?
- Python + Graphviz绘制神经网络结构图--简化版本实现
- 79、tensorflow计算一个五层神经网络的正则化损失系数、防止网络过拟合、正则化的思想就是在损失函数中加入刻画模型复杂程度的指标
- 1.2 【干货】人工智能实验室主任吴恩达:用神经网络进行监督
- 让我们来开发一种更类似人脑的神经网络吧(五)
- 径向基神经网络的两种结构