机器学习常见模型评估指标
2018-10-28 15:11
295 查看
1.单值评估指标
在机器学习或深度学习中,为了评估最终模型的好坏,我们经常会引入各种评估指标,为了便于指标的说明,我们这里具一个例子作为说明。假设我们想要建立一个垃圾邮件的分类模型,此时,模型预测结果的混淆矩阵如下表所示:
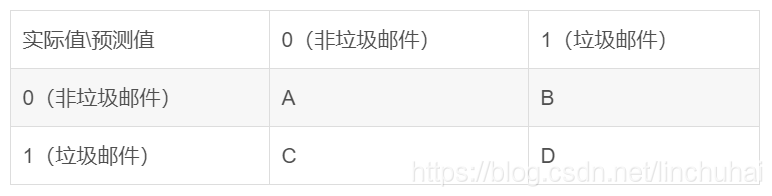
此时,我们常用的评估指标就有如下:
- 准确率:即预测样本中,类别预测正确的比率,其计算公式为:
;
- 精确率(查准率):即预测为正例的样本中,真正属于正例的样本比率(已经被预测为垃圾邮件的样本中,实际类别是垃圾邮件的样本比例),其计算公式为:
;
- 召回率(查全率、灵敏度):即真实情况为正例的样本中,被预测为正例的样本比率(实际类别是垃圾邮件的所有样本中,被预测为垃圾邮件的比例),其计算公式为:
;
- 特异度:即负例样本中被正确分类的比例(所有的非垃圾邮件中被预测为非垃圾邮件的比例),其计算公式为:
2.组合型指标
在实际一些应用场景中,有时模型在各个类别上预测错误的成本是不一样的,比如垃圾邮件分类模型中,我们习惯会认为正常邮件被预测为垃圾邮件的成本是要比垃圾邮件被预测为正常邮件的成本要高的,此时,我们一般不会直接基于某个单值指标,如准确率对模型进行评估,而是采用组合型指标,常见的组合型指标有如下:
- F1值:即精确率和召回率的调和平均,计算公式为:
;
- AUC:AUC值即为ROC曲线下方对应的面积,而ROC曲线是指这样一条曲线,其横坐标是1-特异度,纵坐标是灵敏度,当分类阈值由大到小,从将所有的样本判定为负类到将所有样本都判定为正类时,就可以依次获得各个分类阈值下对应的(1-特异度,灵敏度)坐标对,此时将各坐标对连接起来即为对应的ROC曲线。一般来讲,AUC值在0.5-1范围比较好,低于0.5则表示模型比随机猜测还差。
3. 优化指标与满意度指标
在企业的应用场景中,有时我们除了考虑模型的预测准确性之外,还可能会考虑其他的因素,比如模型的运行时间、模型的参数量大小等,此时,如果直接对这些指标进行直接加和或加权,则可能会导致一个量纲不匹配的问题,因此,我们一般是将模型的准确性指标称为优化指标(如准确率),将其他的指标称为满意度指标(如运行时间),然后在确保满意度指标达到指定范围的条件下(比如运行时间小于100ms),去最优化优化指标。
阅读更多
相关文章推荐
- 机器学习——模型测试与评估方法与指标
- 机器学习(二十四)——常见模型评估方法
- 机器学习模型评估指标汇总
- 西瓜书《机器学习》学习笔记--模型评估及选择(二) 留出法
- Stanford机器学习笔记-6. 学习模型的评估和选择
- 机器学习(周志华)读书笔记-(二)模型评估与选择
- 机器学习笔记(二)模型评估
- 机器学习模型性能评估方法笔记
- 机器学习模型评价指标准确率召回率精确率
- 『机器学习——周志华』学习笔记——第二章:模型评估与选择
- 机器学习(周志华 )-2模型评估与选择
- 机器学习之模型评估与模型选择(学习笔记)
- 模型评估指标AUC(area under the curve)
- 西瓜书-机器学习《二》模型评估与选择
- 机器学习笔记(IV)模型评估与选择(III)
- 机器学习模型评估与选择
- 机器学习笔记2.模型评估于选择----教材周志华西瓜书
- 机器学习:模型评估和优化
- 机器学习模型评价指标 -- 混淆矩阵
- 优达(Udacity)-机器学习基础-评估指标