【论文解读】用于卷积神经网络的注意力机制(Attention)----CBAM: Convolutional Block Attention Module
论文:CBAM: Convolutional Block Attention Module
收录于:ECCV 2018
摘要
论文提出了Convolutional Block Attention Module(CBAM),这是一种为卷积神将网络设计的,简单有效的注意力模块(Attention Module)。对于卷积神经网络生成的feature map,CBAM从通道和空间两个维度计算feature map的attention map,然后将attention map与输入的feature map相乘来进行特征的自适应学习。CBAM是一个轻量的通用模块,可以将其融入到各种卷积神经网络中进行端到端的训练。
主要思想
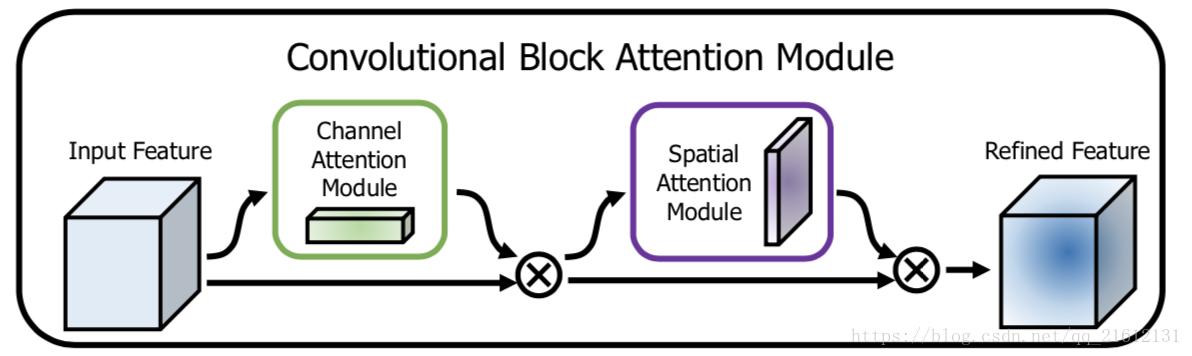
对于一个中间层的feature map:F∈RC∗H∗WF \in\mathbb R^{C*H*W}F∈RC∗H∗W,CBAM将会顺序推理出1维的channel attention map Mc∈RC∗1∗1M_c \in\mathbb R^{C*1*1}Mc∈RC∗1∗1以及2维的spatial attention map Ms∈R1∗H∗WM_s \in\mathbb R^{1*H*W}Ms∈R1∗H∗W,整个过程如下所示:
F′=Mc(F)⊗F
F^{'} = M_c(F) \otimes F
F′=Mc(F)⊗F
F′′=Ms(F′)⊗F′
F^{''}=M_s(F^{'}) \otimes F^{'}
F′′=Ms(F′)⊗F′
其中⊗\otimes⊗为element-wise multiplication,首先将channel attention map与输入的feature map相乘得到F′F^{'}F′,之后计算F′F^{'}F′的spatial attention map,并将两者相乘得到最终的输出F′′F^{''}F′′。下图为CBAM的示意图:
Channel attention module
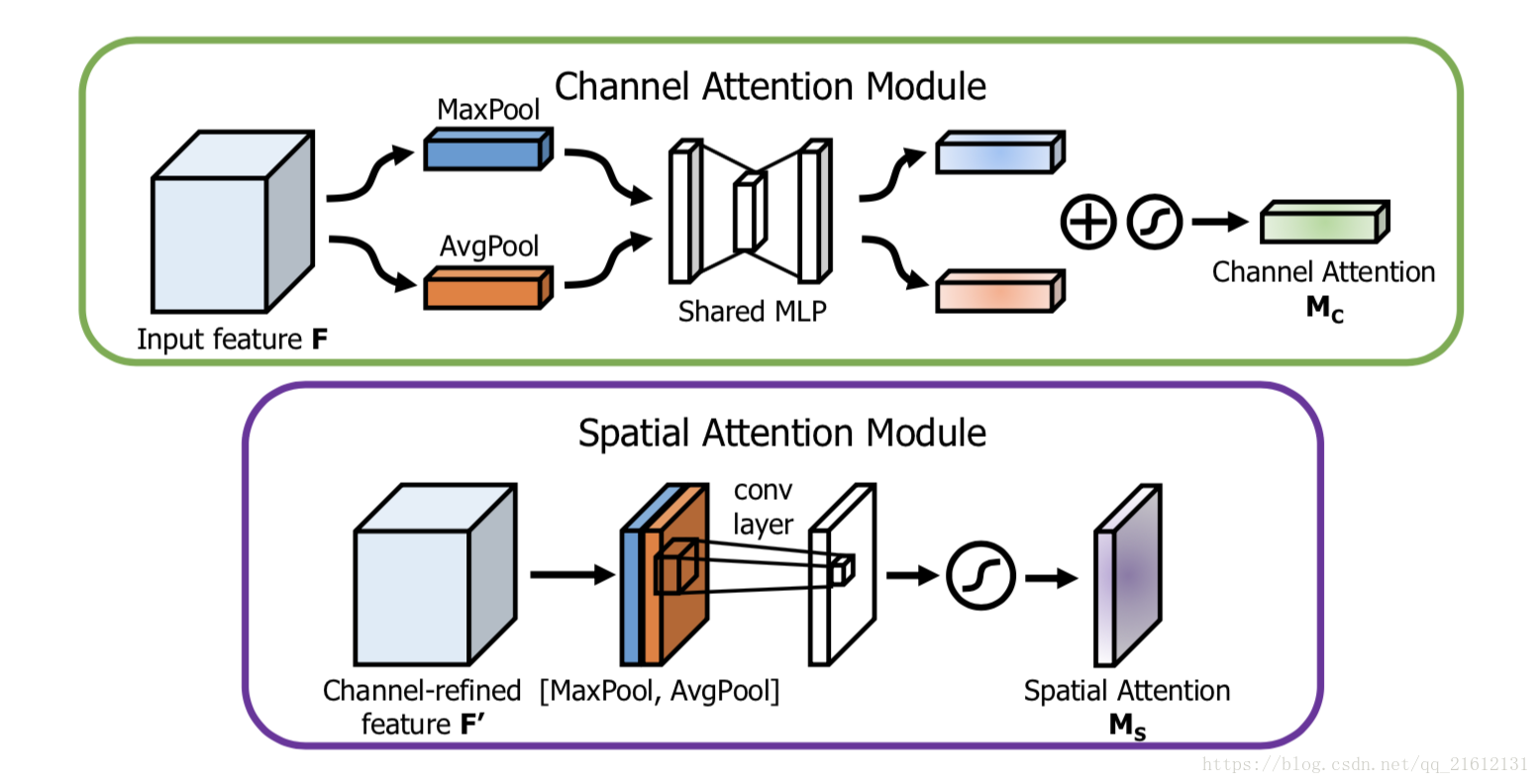
feature map 的每个channel都被视为一个feature detector,channel attention主要关注于输入图片中什么(what)是有意义的。为了高效地计算channel attention,论文使用最大池化和平均池化对feature map在空间维度上进行压缩,得到两个不同的空间背景描述:FmaxcF^{c}_{max}Fmaxc和FavgcF^{c}_{avg}Favgc。使用由MLP组成的共享网络对这两个不同的空间背景描述进行计算得到channel attention map:Mc∈RC∗1∗1M_c \in\mathbb R^{C*1*1}Mc∈RC∗1∗1。计算过程如下:
Mc(F)=σ(MLP(AvgPool(F)))+σ(MLP(MaxPool(F)))
M_c(F) = \sigma(MLP(AvgPool(F))) + \sigma(MLP(MaxPool(F)))
Mc(F)=σ(MLP(AvgPool(F)))+σ(MLP(MaxPool(F)))
Mc(F)=σ(W1(W0(Favgc)))+σ(W1(W0(Fmaxc)))
M_c(F) = \sigma(W_1(W_0(F^{c}_{avg}))) + \sigma(W_1(W_0(F^{c}_{max})))
Mc(F)=σ(W1(W0(Favgc)))+σ(W1(W0(Fmaxc)))
其中W0∈RC/r∗CW_0 \in \mathbb R^{C/r * C}W0∈RC/r∗C,W1∈RC∗C/rW_1 \in \mathbb R^{C * C/r}W1∈RC∗C/r,W0W_0W0后使用了Relu作为激活函数。
Spatial attention module.
与channel attention不同,spatial attention主要关注于位置信息(where)。为了计算spatial attention,论文首先在channel的维度上使用最大池化和平均池化得到两个不同的特征描述Fmaxs∈R1∗H∗WF^{s}_{max} \in \mathbb R_{1*H*W}Fmaxs∈R1∗H∗W和Favgs∈R1∗H∗WF^{s}_{avg} \in \mathbb R_{1*H*W}Favgs∈R1∗H∗W,然后使用concatenation将两个特征描述合并,并使用卷积操作生成spatial attention map Ms(F)∈RH∗WM_s(F) \in \mathbb R_{H*W}Ms(F)∈RH∗W。计算过程如下:
Ms(F)=σ(f7∗7([AvgPool(F);MaxPool(F)]))
M_s(F) = \sigma(f^{7*7}([AvgPool(F); MaxPool(F)]))
Ms(F)=σ(f7∗7([AvgPool(F);MaxPool(F)]))
Ms(F)=σ(f7∗7([Favgs;Fmaxs]))
M_s(F) = \sigma(f^{7*7}([F^{s}_{avg}; F^{s}_{max}]))
Ms(F)=σ(f7∗7([Favgs;Fmaxs]))
其中,f7∗7f^{7*7}f7∗7表示7*7的卷积层
下图为channel attention和spatial attention的示意图:
代码
环境:tensorflow 1.9
"""
@Time : 2018/10/19
@Author : Li YongHong
@Email : lyh_robert@163.com
@File : test.py
"""
import tensorflow as tf
import numpy as np
slim = tf.contrib.slim
def combined_static_and_dynamic_shape(tensor):
"""Returns a list containing static and dynamic values for the dimensions.
Returns a list of static and dynamic values for shape dimensions. This is
useful to preserve static shapes when available in reshape operation.
Args:
tensor: A tensor of any type.
Returns:
A list of size tensor.shape.ndims containing integers or a scalar tensor.
"""
static_tensor_shape = tensor.shape.as_list()
dynamic_tensor_shape = tf.shape(tensor)
combined_shape = []
for index, dim in enumerate(static_tensor_shape):
if dim is not None:
combined_shape.append(dim)
else:
combined_shape.append(dynamic_tensor_shape[index])
return combined_shape
def convolutional_block_attention_module(feature_map, index, inner_units_ratio=0.5):
"""
CBAM: convolution block attention module, which is described in "CBAM: Convolutional Block Attention Module"
Architecture : "https://arxiv.org/pdf/1807.06521.pdf"
If you want to use this module, just plug this module into your network
:param feature_map : input feature map
:param index : the index of convolution block attention module
:param inner_units_ratio: output units number of fully connected layer: inner_units_ratio*feature_map_channel
:return:feature map with channel and spatial attention
"""
with tf.variable_scope("cbam_%s" % (index)):
feature_map_shape = combined_static_and_dynamic_shape(feature_map)
# channel attention
channel_avg_weights = tf.nn.avg_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_max_weights = tf.nn.max_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_avg_reshape = tf.reshape(channel_avg_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_max_reshape = tf.reshape(channel_max_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_w_reshape = tf.concat([channel_avg_reshape, channel_max_reshape], axis=1)
fc_1 = tf.layers.dense(
inputs=channel_w_reshape,
units=feature_map_shape[3] * inner_units_ratio,
name="fc_1",
activation=tf.nn.relu
)
fc_2 = tf.layers.dense(
inputs=fc_1,
units=feature_map_shape[3],
name="fc_2",
activation=tf.nn.sigmoid
)
channel_attention = tf.reduce_sum(fc_2, axis=1, name="channel_attention_sum")
channel_attention = tf.reshape(channel_attention, shape=[feature_map_shape[0], 1, 1, feature_map_shape[3]])
feature_map_with_channel_attention = tf.multiply(feature_map, channel_attention)
# spatial attention
channel_wise_avg_pooling = tf.reduce_mean(feature_map_with_channel_attention, axis=3)
channel_wise_max_pooling = tf.reduce_max(feature_map_with_channel_attention, axis=3)
channel_wise_avg_pooling = tf.reshape(channel_wise_avg_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_max_pooling = tf.reshape(channel_wise_max_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_pooling = tf.concat([channel_wise_avg_pooling, channel_wise_max_pooling], axis=3)
spatial_attention = slim.conv2d(
channel_wise_pooling,
1,
[3, 3],
padding='SAME',
activation_fn=tf.nn.sigmoid,
scope="spatial_attention_conv"
)
feature_map_with_attention = tf.multiply(feature_map_with_channel_attention, spatial_attention)
return feature_map_with_attention
#example
feature_map = tf.constant(np.random.rand(2,8,8,32), dtype=tf.float16)
feature_map_with_attention = convolutional_block_attention_module(feature_map)
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
result = sess.run(feature_map_with_attention)
print(result.shape)
阅读更多

- 【论文笔记】CBAM: Convolutional Block Attention Module
- 论文阅读: 图像分类中的注意力机制(attention)
- 【转】论文阅读笔记-Segmentation-Aware Convolutional Networks Using Local Attention Masks
- 【论文笔记】CVPR2015 级联卷积神经网络用于人脸检测
- 实时字幕生成原理挖掘——论文解读DenseCap: Fully Convolutional Localization Networks for Dense Captioning
- Weakly supervised object recognition with convolutional neural networks 论文解读
- 神经网络注意力机制--Attention in Neural Networks
- Attention, 神经网络中的注意力机制
- 神经网络注意力机制--Attention in Neural Networks
- 深度卷积神经网络用于图像缩放Image Scaling using Deep Convolutional Neural Networks
- 论文阅读笔记-Segmentation-Aware Convolutional Networks Using Local Attention Masks
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- Semantic Segmentation --Improve Semantic Segmentation by Global Convolutional Network(GCN)论文解读
- Semantic Segmentation--SegNet:A Deep Convolutional Encoder-Decoder Architecture..论文解读
- [置顶] 实例分割初探,Fully Convolutional Instance-aware Semantic Segmentation论文解读
- Bags of Local Convolutional Features for Scalable Instance Search 论文解读
- [论文解读] Vehicle Detection from 3D Lidar Using Fully Convolutional Network
- AAAI 2018论文解读 | 基于文档级问答任务的新注意力模型
- 深度学习论文随记(二)---VGGNet模型解读-2014年(Very Deep Convolutional Networks for Large-Scale Image Recognition)
- CVPR 2017论文:基于网格的运动统计,用于快速、超鲁棒的特征匹配(附大神解读)