redis 五大数据结构__常用命令
linux 下下载redis数据库
apt install redis
如果提示权限不够的话, 直接提权:
sudo apt install redis-server
linux启用、停止服务
service redis start
service redis stop
service redis restart
xshell进入linux
cd .. # 返回根目录 ls # 查看文件 cd etc/
那么到这里,就该进入正题啦。
首先记录下连接、退出、切换数据库的命令
连接:redis:redis-cli 退出:exit 切换数据库:select n
数据库没有名称,默认有16个,通过0-15来标识,连接redis默认选择第一个数据库(通过select n切换)
一直说redis有五大数据结构, 都有什么呢。
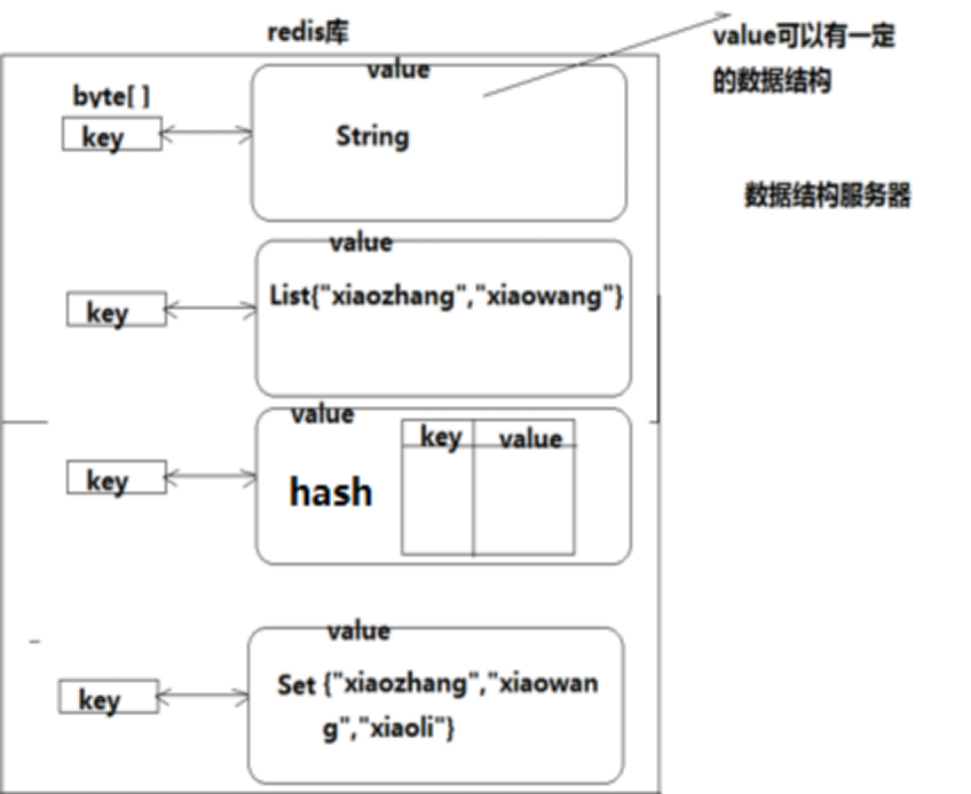
redis是key-value的数据结构,每条数据都是⼀个键值对
键的类型是字符串
注意:键不能重复
值的类型分为五种:
String ------> 字符串
Hash ------> 哈希
List ------> 列表
set ------> 集合
Zset ------> 有序集合
现在我们就开始详细的看下每个数据类型常用的命令有哪些;
string类型
string是redis最基本的类型,一个key对应一个value。
设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型。
设置数据:set key value
设置多组数据:mset key value [key value..]

为多组key设置值,该操作为原子操作,要么一组都设置成功,要么一组都设置失败;

返回一个或多个key的值,若key不存在返回nil,若key存在但不是字符串返回nil
查看数据:get key

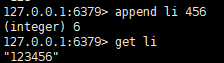
将指定的值追加到key末尾,若key不存在,则创建并赋值,返回追加后的字符串长度
追加数据:append key value
返回key的剩余生存时间, -1 表示永久存在, -2表示不存在
ttl key
设置 key的同时,设置过期时间(单位:秒) key 过期后将不再可用,会被系统自动删除。
set key value ex seconds
set age 18 ex 20
或 setex key seconds value 例: ( setex sex 20 '男' )
移除指定key的生存时间,成功返回1,若key不存在或不存在生存时间时返回0;
persist key
这里追加一个命令:
进入数据库:user db_name;
如果不知道数据库是否存在,记得加if exists
全局key操作
对redis的五个数据类型都适用的命令
rename key newkey 改名
当key和newkey相同或者key不存在时返回一个错误,当newkey已存在时则会覆盖;
keys * # 查看所有的key del key # 删除 返回成功的个数 exists key # 查看key是否存在 返回存在个个数 type key # 查看key类型 expire key seconds #设置过期时间 persist key #移除过期时间
list类型
List类型是一个字符串列表,可以在列表头部或尾部添加/删除数据
在插入数据时,按照插入顺序排序,在列表的头部或者尾部添加元素,
如果该键并不存在,Redis将为该键创建一个。
添加数据:rpush key value [value…] 在尾部添加数据
lpush key value [value…] 在头部添加数据


返回列表中元素的值。index从0开始,当index超出索引时返回null
lindex key index
 #查看第2个
#查看第2个
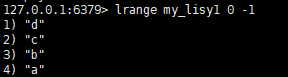
查看索引范围内元素的值
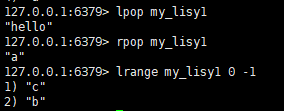
查看数据:lrange key start stop
#查看所有值
返回列表的长度
llen key

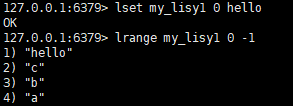
修改数据:lset key index value
指定索引号进行修改
删除数据:lpop key 删除左边第一个 rpop key 删除右边第一个
Hash类型
是一个键值(key=>value)对集合。是string 类型的 field 和 value 的映射表
user { name:juhao, age:18 }
user -> key(键) name,age ->field(域) juhao,18 ->value(值)
添加数据:
将field-value设置到hash表中,若key不存在会新建hash表再赋值,已存在则会覆盖;
hset key field value

查看域值:
hget key field

批量添加:
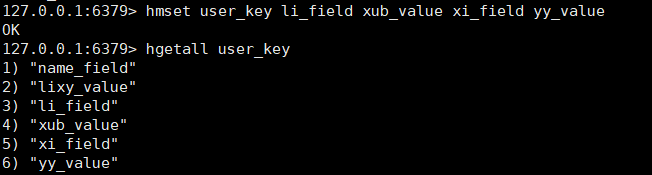
hmset key field value field2 value2
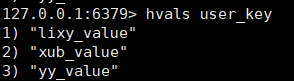
查看所有的value:
hvals key
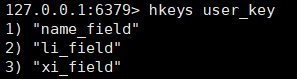
查看所有的field:
hkeys key
# 获取多个 field
hmget key field[field...]

# 获取全部`field` 和 `value
hgetall key
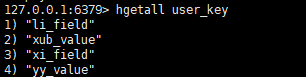
# 查看有几个键值对
hlen key

# 判断hash表中指定域是否存在,返回1,若key或field不存在则返回0;
hexists key field

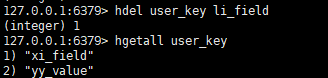
# 删除
hdel key field
Set类型
元素为string类型
无序集合
元素具有唯一性,不重复
sadd key member [member...] 增加元素
将一个或多个member元素加入到集合key中,若member已存在那么会忽略此元素,

# 返回集合key中元素的个数
scard key

# 获取集合中所有元素
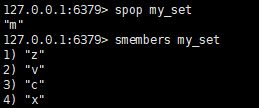
smembers key

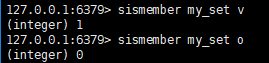
# 判断集合存在某个值
判断member在key中是否已存在, 返回0或1
sismember key member
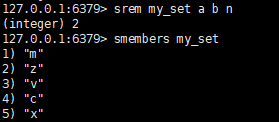
# 删除
移除一个或多个元素,不存在的member会被忽略,返回被移除元素个数
srem key member [member...]
# 随机删除
spop key
移除并返回集合中的一个随机元素,当key不存在时返回NULL
zset类型
类似于Set,不同的是Sorted中的每个成员都分配了一个分数(Score)用于对其中的成员进行排序(升序)。
zset的成员是唯一的,但分数(score)却可以重复。
# 添加/修改
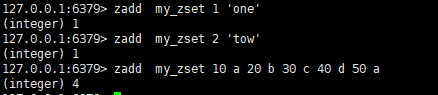
zadd key score member[ [score member] ..]
设置, 存在就更新
# 查看
zscore key member
查看score值

# 按索引返回key的成员, withscores表示显示score
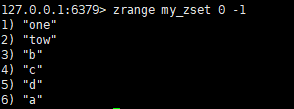
zrange key start stop[withscores]
# 显示全部
# 返回集合中 score 在给定区间的元素
zrangebyscore key min max

# 删除
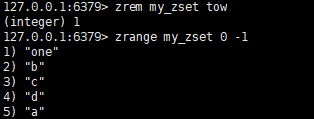
zrem key member [member...]
移除有序集合中的一个或多个元素,若member不存在则忽略;
# 删除集合中索引在给定区间的元素
zremrangebyrank min max
# 删除集合中 score 在给定区间的元素
zremrangebyscore min max

写到这里,redis整理完毕,命令不要死记硬背,用多了自然就记住了。
就像大家写sql ,新建 create table ;插入insert into; 查询 select * from 表 一样。
声明:本文为博主学习感悟总结,水平有限,如果不当,欢迎指正。如果您认为还不错,欢迎转载。转载与引用请注明作者及出处。

- Redis基础、高级特性与性能调优-Redis的数据结构和相关常用命令
- Redis 数据结构 和 常用命令
- RedisTemplate访问Redis数据结构(介绍和常用命令)
- redis_2_key_五大数据类型常用命令
- Redis数据结构及其常用命令
- Redis 5种数据结构常用命令
- Redis实用教程之三---Redis数据结构与常用命令
- Redis中的数据结构与常用命令
- 详细讲解redis数据结构(内存模型)以及常用命令
- Redis几种数据结构常用命令整合
- Redis学习笔记(四)—— redis的常用命令和五大数据类型的简单使用
- Redis常用命令以及代码实例
- Redis数据结构命令之String
- 【学习Redis】- 散列(哈希)类型和常用命令
- Redis常用命令
- Redis 常用命令汇总
- redis 常用命令
- Redis常用命令小总结
- Redis常用命令
- Redis常用命令