redis 数据类型、使用场景、持久化和使用技巧
| redis |
|
|
|
Redis 使用场景 |
string |
数据结构是简单的key-value类型 |
|
set,get,decr,incr,mget |
||
|
1、redis定时持久化 2、操作日志 3、Replication机制 |
||
|
get、set、incr、decr 1、获取字符串的长度 2、往字符串append内容 3、设置和获取字符串的某一段内容和某一位(bit) 4、批量设置一系列字符串的内容 |
||
|
实现方式: String 在 Redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr、decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为int。 |
||
|
使用场景: 计数,INCRBY,可以计算出最近用户再页面停留不超过50S的用户,停留20S时显示条幅等 |
hash
|
Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口 |
|
实现方式: 上面已经说到 Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht |
|
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息 Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Ke y(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。 |
list
|
使用场景: 1、粉丝列表、关注列表,实现最新消息排列的功能 2、消息队列,PUSH 将任务存在list中,POP将任务取出执行,也可以直接查询和删除list中某一段的元素 3、显示最新的项目列表 4、并发量大(FIFO 排队等待处理) 5、优先级(设置不同的级别,然后轮询的方式处理,优先级高的处理完成 才能继续执行下去) |
|
因此用户的投票会相应的把新闻挖出来,但时间会按照一定的指数将新闻埋下去。下面是我们的模式,当然算法由你决定。 模式是这样的,开始时先观察那些可能是最新的项目,例如首页上的1000条新闻都是候选者,因此我们先忽视掉其他的,这实现起来很简单。 每次新的新闻贴上来后,我们将ID添加到列表中,使用LPUSH + LTRIM,确保只取出最新的1000条项目。 |
set
|
列表数据,自动排重,存储集合性的数据,可以求交集,并集,差集等 |
|
使用场景: 微博 实现共同关注,共同喜好、特定时间内的特定项目 1、想知道特定用户的数量 2、测试某个特定用户是否访问了这个页面 |
Sorted set
|
列表数据有序不重复 也可以做带权重的队列,按照优先级去执行 |
|
使用场景: 1、列出前100名高分选手 2、列出用户当前的排名 3、通过取交集可以查出学生各科成绩的总和 |
|
有一项后台任务获取这个列表,并且持续的计算这1000条新闻中每条新闻的最终得分。计算结果由ZADD命令按照新的顺序填充生成列表,老新闻则被清除。这里的关键思路是排序工作是由后台任务来完成的。 |
replication
Redis的replication机制允许slave从master那里通过网络传输拷贝到完整的数据备份
Redis 持久化

|
原理 |
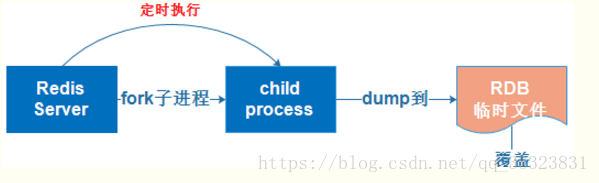
原理是将数据库定时dump到磁盘上 是指在指定时间内将内存中的数据集快照到 磁盘上,实际是fork一个子进程,先将数据集写入临时文件再替换之前的文件,用二进制压缩存储 整个数据库只包含一个文件 |
|
优点 |
1、若出现系统故障可以很容易的恢复,将一个文件压缩转移到其他存储介质上 备份策略:例如 每个小时备份近24小时的数据,每天备份近30天的数据 2、性能最大化 开始持久化是fork子进程,由子进程去完成持久化的工作,极大避免服务进程执行IO操作 3、数据集较大时,启动效率更高 |
|
劣势 |
1、一旦在持久化前出现宕机现象,就会有数据无法写入到磁盘的现象,造成数据丢失 2、如果数据集较大,由于是子进程再执行,可能会导致服务停止几百毫秒 |
|
持久化配置 |
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。 save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。 save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。 |
|
|
|
AOF
|
原理是将redis的操作日志以追加的方式写入文件中 以日志的形式记录每次的写、删除操作,查询操作不记录,以文本的方式记录,可以打开文件看到详细的操作记录 |
|||
|
优点 |
1、如果系统出现问题,再下一次启动redis前 可以通过redis-check-aof工具解决数据一致性的问题 2、如果日志过大,redis可以自动启动rewrite机制,即以append方式不断的将数据插入到老磁盘文件中,同时redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行,因此在进行rewrite时可以保证数据安全性 3、AOF包含一个格式清晰易于理解的日志文件,用于记录所有的操作。也可以通过该文件完成数据的重建 |
||
|
劣势 |
1、对于相同数量的数据集而言,AOF文件通常大于RDB文件,so在恢复大数据时 RDB比AOF快 2、AOF运行效率低于RDB |
||
|
持久化配置 |
appendfsync always #每次有数据修改发生时都会写入AOF文件。 appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。 appendfsync no #从不同步。高效但是数据不会被持久化。 |
||
|
|
|
||
| 使用方法 |
工作流程 |

|
|
|
1.所有的写入命令会增加到aof_buf(缓冲区) |
内容以文本协议格式, 命令: set hello 存储内容: \r\n$2\r\nset\r\n$5\r\nhellor\n *<count> // <count>表示该命令有2个参数 $<len> // <len>表示第1个参数的长度 <content> // <content>表示第1个参数的内容 写到缓冲区的原因: 1)redis 是单线程,如果每次都直接写入硬盘,性能就要取决于硬盘的负载 2)可以提供多种缓冲区同步硬盘的策略,性能和安全性方面达到平衡 |
||
| 2.缓冲区根据相应的策略同步文件到硬盘 |
fsync对单个文件进行操作,强制同步到硬盘。
|
||
| 3.随着aof文件越来越大,需要定期对文件进行重写达到压缩的目的 |
1.aof重写过程可以手动触发(直接调用bgrewriteaof命令)和自动触发 2. |
||
| 4.当redis重启时,可以对aof文件进行重写操作 | https://www.geek-share.com/detail/2727588433.html |


 [/td]
[/td]
阅读更多

- Redis五种数据类型的使用场景
- redis 五种数据类型的使用场景
- Redis常用数据类型介绍、使用场景及其操作命令
- Redis常用数据类型介绍、使用场景及其操作命令
- Redis常用数据类型介绍、使用场景及其操作命令
- 数据类型Redis使用场景
- Redis简介、与memcached比较、存储方式、应用场景、生产经验教训、安全设置、key的建议、安装和常用数据类型介绍、ServiceStack.Redis使用(1)
- redis 五种数据类型的使用场景
- Redis常用数据类型介绍、使用场景及其操作命令
- redis 五种数据类型的使用场景
- redis 五种数据类型的使用场景
- Redis数据类型及使用场景
- redis 五种数据类型的使用场景
- 为什么使用Redis 使用Redis有什么缺点 单线程的Redis为什么这么快 Redis的数据类型,以及每种数据类型的使用场景 Redis的过期策略以
- redis 五种数据类型的使用场景
- redis 五种数据类型的使用场景
- redis 五种数据类型的使用场景
- redis 五种数据类型的使用场景
- redis 五种数据类型的使用场景
- Redis数据类型及使用场景