scrapy爬虫框架简单实例
2018-10-06 17:36
330 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ACanswer/article/details/82952327
声明:初学scrapy,总结学习内容。
目录
一、安装scrapy
[code]pip install scrapy
二、创建工程
[code]scrapy startproject mySpider #创建scrapy工程 cd mySpider #进入工程目录 scrapy genspider itcast "www.itcast.cn" #创建爬虫(spider名不能与project名相同)
三、编写代码
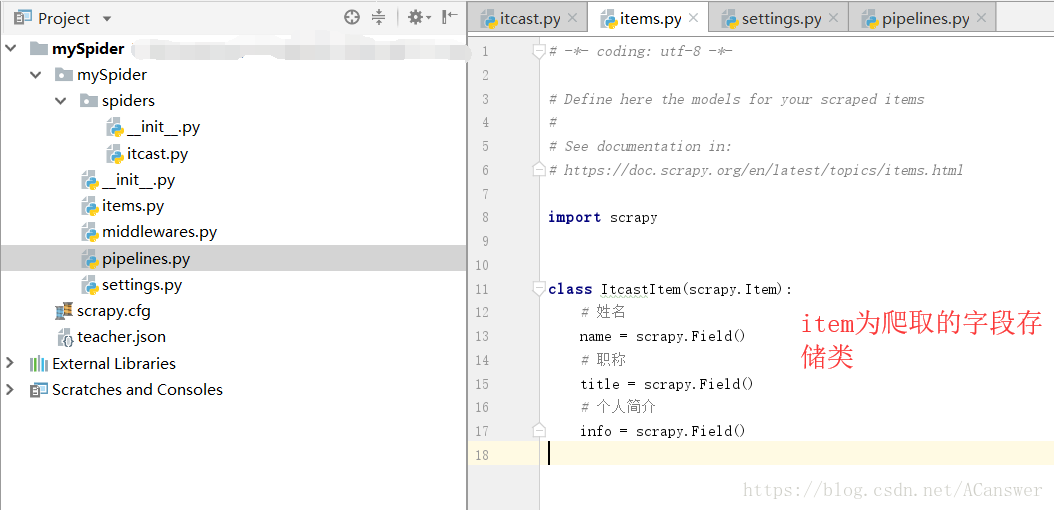
3.1 item文件编写
items用于存储字段的定义。即爬取的内容存与item类中。
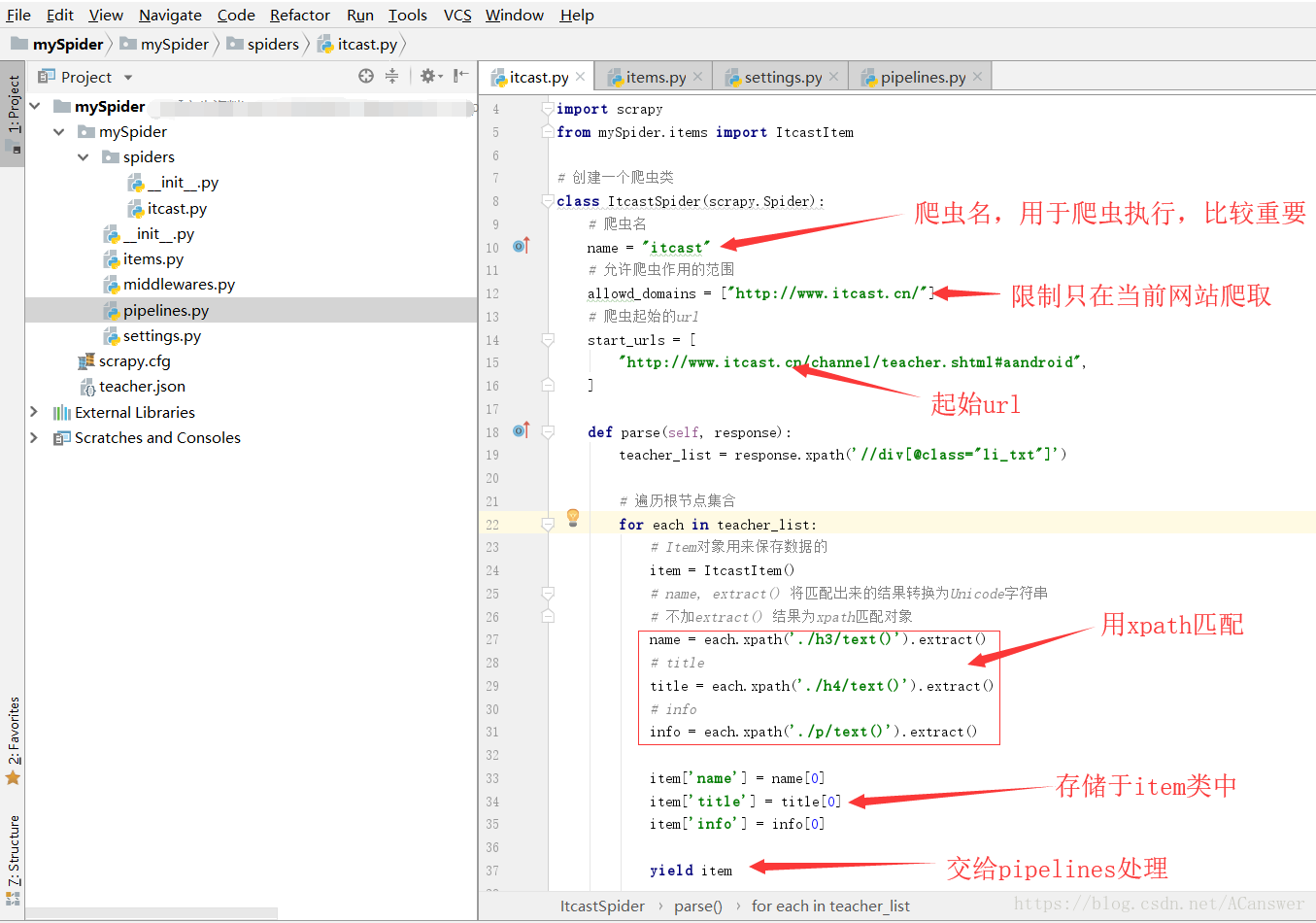
3.1 spider文件编写
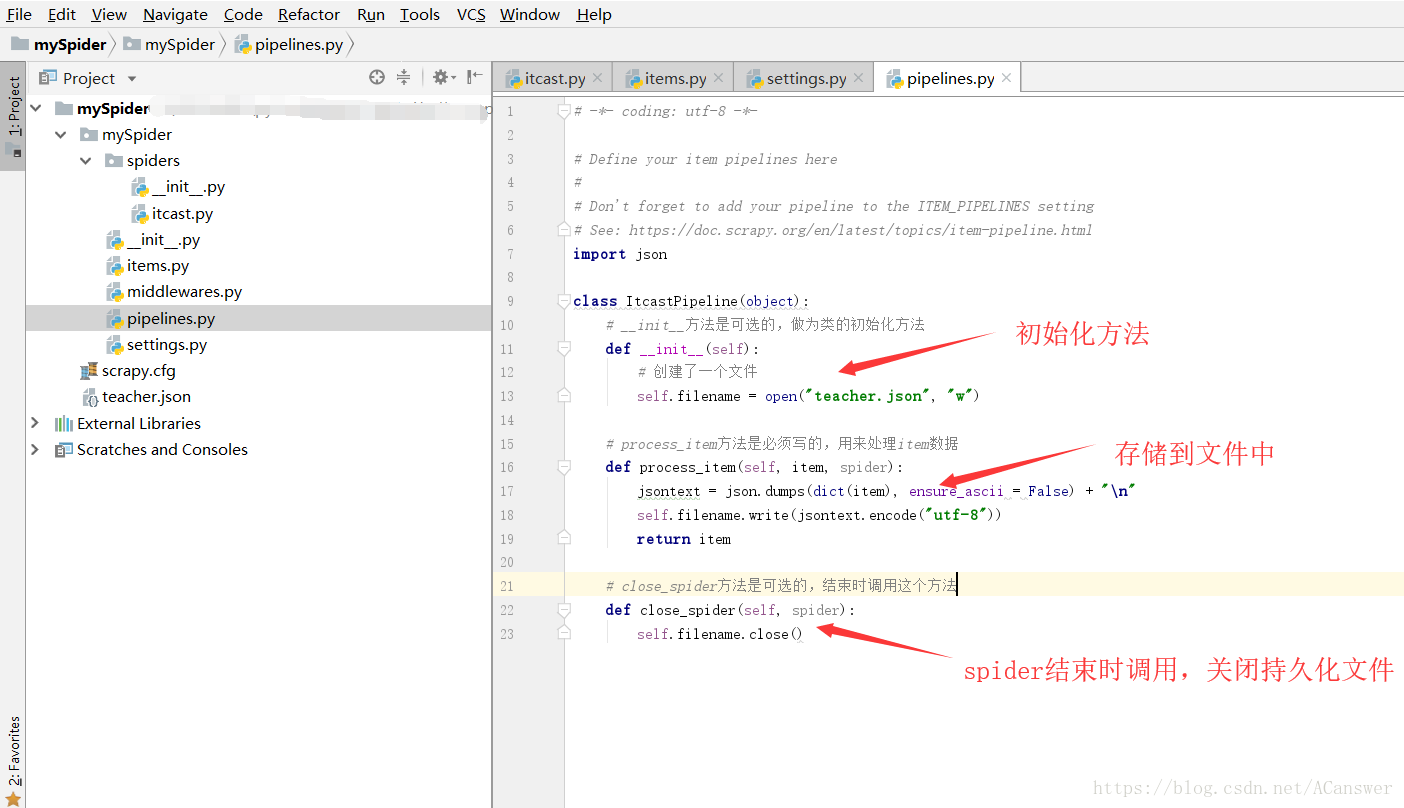
3.2 pipeline文件编写
pipeline文件用于存储到文件中。
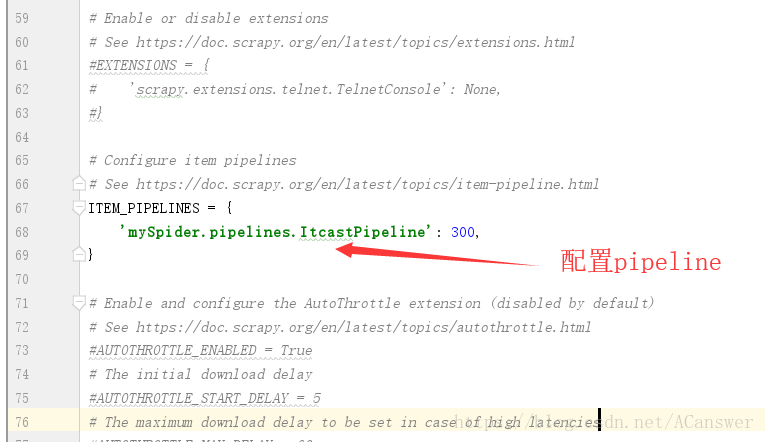
3.3 setting文件修改
其他配置暂且不用修改,只修改pipeline配置。
四、测试
[code]scrapy crawl itcast #运行爬虫

相关文章推荐
- 使用Python的Scrapy框架编写web爬虫的简单示例
- [Python]使用Scrapy爬虫框架简单爬取图片并保存本地
- scrapy爬虫框架实例二
- Python爬虫框架Scrapy实例代码
- python爬虫框架scrapy实例详解
- Python之Scrapy爬虫框架安装及简单使用
- scrapy爬虫框架入门实例
- Scrapy框架学习(三)----基于Scrapy框架实现的简单爬虫案例
- Python的Scrapy爬虫框架简单学习笔记
- Python爬虫框架Scrapy实例
- scrapy爬虫框架学习入门教程及实例
- Python爬虫框架Scrapy实例
- Python爬虫 --- 2.3 Scrapy 框架的简单使用
- 爬虫 scrapy 框架学习 1. Scrapy框架业务逻辑的理解 + 简单爬虫案例示范
- scrapy框架爬虫,爬取腾讯职业实例
- python爬虫框架scrapy实例详解
- scrapy爬虫框架实例一,爬取自己博客
- scrapy爬虫框架入门实例(一)
- 运维学python之爬虫高级篇(二)用Scrapy框架实现简单爬虫
- python爬虫框架scrapy实例详解