python读取json格式文件和用pandas读取excel文件
IT Xiao Ang Zai 9月30号

版本:python3.7
编程软件:sublime
一:python解析json数据
1.什么是json:
(1)JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
JSON在python中分别由list和dict组成。
(2)作用:主要用于字符串和python数据类型间进行转换。
(3)Json模块提供了四个功能:dumps、dump、loads、load
json dumps把数据类型转换成字符串 dump把数据类型转换成字符串并存储在文件中 loads把字符串转换成数据类型 load把文件打开从字符串转换成数据类型。
(4)优点:是可以在不同语言之间交换数据的。
缺点:json只能序列化最基本的数据类型。
2.python对json数据的基本操作:
python的json模块提供了一种简单的方式来编码和解码JSON数据。其中两个主要的函数是json.dumps()和json.loads()。json.dumps()函数是将一个python数据结构转换为JSON编码的字符串,json.loads()函数是将一个JSON编码的字符串转换回一个python数据结构。但如果你要处理的是文件,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据:
[code]import json
data = {'name':'IT Xiao Ang Zai','number':100,'age':19.5}
jsonStr = json.dumps(data) #python数据结构(一般为字典)转换为JSON编码的字符串
print(jsonStr)
print(type(json))
data2 = json.loads(jsonStr) #将一个JSON编码的字符串转换回一个python数据结构
print(data2)
print(type(data2))
#我们现在试着写入json类型数据
with open("my_data.json",'w') as f:
json.dump(data2,f)
#我们现在进行读入json类型数据
with open("my_data.json",'r') as g:
result_data = json.load(g)
print(result_data)
结果如下:
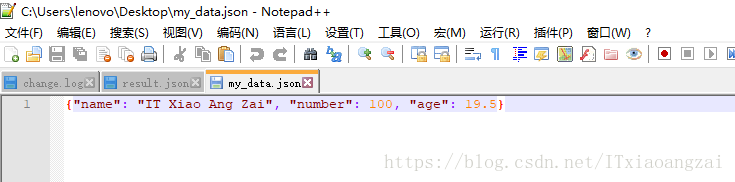

我们发现,当转换为一个json字符串的时候,它的类型为module,其实是一个字符串。而且我们要对文件进行操作的话,需要用到不加s的两个函数进行编码和解码json数据的操作。
其实只要把返回的json格式嵌套弄清楚,json还是比较简单的,其实之前网络爬虫中就介绍过json解析数据了。
3.注意事项
在读取文件时,要设置以utf-8解码模式读取文件,encoding参数必须设置,否则默认以gbk模式读取文件,当文件中包含中文时,会报错:
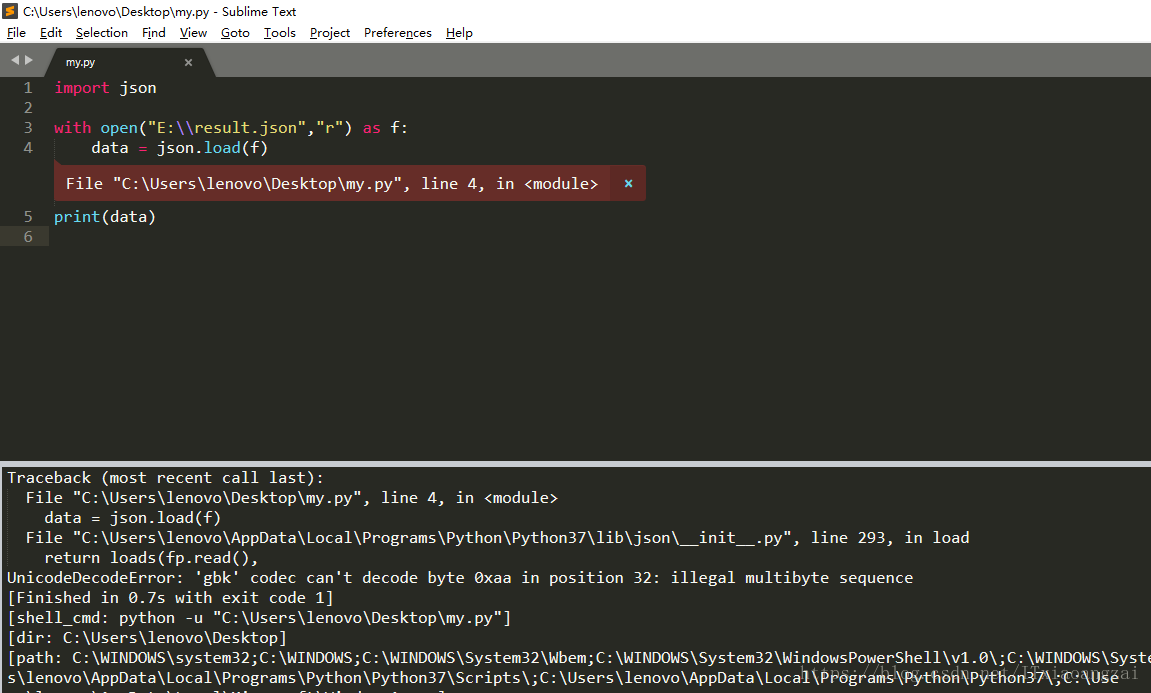
会出现错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 32: illegal multibyte sequence
此时需要设置encoding参数,以utf-8编码模式读取文件:
[code]import json
with open("E:\\result.json","r",encoding="utf-8") as f:
data = json.load(f)
print(data)
我们可以看到结果:

现在就读取正常了。
二:pandas模块读取excel文件
1.pandx简介:pandas是基于NumPy的为了解决数据分析任务而创建的工具。pandas模块提供了高效地操作大型数据集所需的工具,对于大批量的数据分析是很方便的。
2.读取excel文件
(1) 读取文件通过read_excel函数实现,除了pandas还需要安装第三方库xlrd。
[code]read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, parse_cols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, has_index_names=None, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
(2) 主要参数
io:excel文件,可以是文件路径、文件网址、file-like对象、xlrd workbook
sheetname:返回指定的sheet,参数可以是字符串(sheet名)、整型(sheet索引)、list(元素为字符串和整型,返回字典{'key':'sheet'})、none(返回字典,全部sheet)
header:指定数据表的表头,参数可以是int、list of ints,即为索引行数为表头; names:返回指定name的列,参数为array-like对象。
encoding:关键字参数,指定以何种编码读取
注:该函数返回pandas中的DataFrame或dict of DataFrame对象,利用DataFrame的相关操作即可读取相应的数据。
3.写入文件
(1) 写入文件通过pandas构造DataFrame,调用to_excel方法实现。
[code]DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
(2) 主要参数
excel_writer:写入的目标excel文件,可以是文件路径、ExcelWriter对象
sheet_name:被写入的sheet名称,string类型,默认为'sheet1'; na_rep:缺失值表示,string类型
header:是否写表头信息,布尔或list of string类型,默认为True
index:是否写行号,布尔类型,默认为True
encoding:指定写入编码,string类型
在下一篇文章中会向大家介绍一些实际操作,请大家及时关注,欢迎评论与交流。
阅读更多

- 【学习笔记】python读取json内容转换成excel格式
- 【Python】读取一个目录,将文件名称转换成 json 格式
- python读取和存储dict()与.json格式文件
- Python读取txt文件,将xxx=111,yyy=222转换为json或字典格式
- Python 把Excel文件导出为Json文件格式
- 读取五种格式的配置文件(xml(两种方式),txt,excel,csv,json)
- Python 读取写入 json 格式的文件
- python读取json文件转成excel
- python读取和存储dict()与.json格式文件
- 用python读取json格式内容并保存到excel中
- python.json/pygal.maps.world学习范例-读取json格式文件、生成世界地图
- 在python里面读取json格式文件
- python任务-从文件读取参数来发送json格式的post请求,再讲请求结果保存到文档里
- python中写入csv,excel显示、pandas读取csv文件的编码问题
- Python使用xlrd读取Excel格式文件的方法
- Python使用pandas读取Excel文件数据和预处理小案例
- Python使用xlrd读取Excel格式文件的方法
- Python 使用 xlrd 读取 Excel格式文件
- Python+pandas读取Excel文件并统计演员参演电影数量
- python读取excel格式的文件