kotlin实战教程之lambda编程
前言
ambda即lambda表达式,简称lambda。本质上是可以传递给其它函数的一小段代码。有了lambda,可以轻松地把通用代码结构抽取成库函数。lambda最常见的用途是和集合一起配合。kotlin甚至还拥有带接收者的lambda,这是一种特殊的lambda。
本文是对<<kotlin实战>>中 “lambda编程”一章的总结,主要记录了一些我认为比较重要的点
在kotlin中常见的lambda用法主要由以下几种:
- 与集合一起使用
- lambda可以与任意java库一起使用
- 带接收者的lambda,比如with和apply
lambda表达式的基本语法
下面是一个lambda表达式的基本语法:
{ x:Int, y:Int -> x + y }
lambda表达式始终用花括号包围,实参并没有用括号括起来。箭头把实参列表和lambda的函数体隔开
lambda作为函数的参数传递
可以把lambda表达式存储在一个变量中,把这个变量当做普通函数对待,也可以直接写作函数参数,比如有一个intOperator函数, 这个函数接收两个int参数,和一个函数。
fun intOperator(o1: Int, o2: Int, run: (a: Int, b: Int) -> Int) {
run(o1, o2)
}
val sumLambda = { x: Int, y: Int -> x + y }
intOperator(1, 2, sumLambda)
intOperator(1, 2, {x:Int, y:Int -> x + y})
上面可以看到,我们直接把lambda当做一个函数传递个intOperator()作为参数。
如果lambda表达式是函数调用的最后一个实参,它可以放到括号外边:
intOperator(1, 2) { x: Int, y: Int -> x + y }
如果lambda表达式是函数的唯一实参时,还可以去掉调用代码中的空括号对
比如下面这个例子
fun myPrint(lambda: () -> Unit) {
lambda()
}
myPrint{
print("a")
}
省略lambda参数类型并使用默认参数名称
在kotlin中如果lambda参数的类型可以被推导出来,我们就不需要显示声明它,比如我们常用的库函数 map:
listOf("1", "2", "3").map{
//
}
在这个代码中使用了默认参数使用it代替。在kotlin中,如果当前上下文期望的是只有一个参数的lambda且这个参数的类型可以推断出来,就会生成这个名称。
允许在lambda内部访问非final变量甚至修改他们
在java中我们是知道的:匿名内部类不能访问非final变量,但在kotlin中可以:
fun main(args: Array<String>) {
var count = 0
listOf("1", "2", "3").forEach{
count++
}
print(count)
}
其实对于kotlin来说,如果在lambad中引用非final变量,它的值会被封装起来,并且会和lambda代码一块存储。
当然对于异步代码或者事件响应回调这个是无效的。
成员引用
在上面我们知道可以直接把lambda当做函数的参数传递给一个函数,但是如果当做参数传递的代码已经被定义成了函数那怎么办呢?
在kotlin中可以使用::把函数转换成一个值,从而传递给函数。这里比如有一个Person类,他有一个say函数,我们可以这样获得这个函数的引用:
val sayQuote = Person::say
这种表达式叫做成员引用,对于顶层函数可以直接 ::say,来获得这个函数的引用。
常用的库函数
对于集合,kotlin提供了丰富的库函数便于我们使用,对于这些函数这里我们只介绍一些关键点。
filter与map
filter函数会遍历集合并选出应用给定lambda后会返回true的那些元素, 需要注意的是,返回的是一个新的集合
val newList = listOf(1, 2, 3, 4).filter{ it % 2 == 0}
map函数对集合中的每一个元素应用给定的函数并把结果收集到一个新集合中
val newList = listOf(1, 2, 3, 4).map{ it.toSting() }
all、any、count、find
- all与any用来检查集合中的所有元素是否都符合某个条件, all表示全部 && any表示至少有一个
- count函数检查有多少个元素满足判断式
- find函数返回第一个符合条件的元素
count 与 size
在一些情况下使用count要高效于size, 比如统计集合中有多少个偶数:
listOf(1, 2, 3, 4, 5).count({it % 2 == 0})
listOf(1, 2, 3, 4, 5).filter({it % 2 == 0}).size
上面两种做法都可以实现这个需求,不过filter会创建一个新的集合,而 count方法只会跟踪匹配元素的数量,不关心元素本身。
其他还有 groupBy/flatMap/flatten,这里不细讲了。
惰性集合操作 : 序列
在说什么是惰性集合操作之前,我们先来看一下非惰性集合操作map与filter, 以获取姓名为A开头的人的名字为例:
peoples.map{it.name}.filter{it.startWith("A")}
我们要知道filter和map都会返回一个列表来保存结果,如果peoples这个集合元素非常多的话,那产生的这个中间集合就非常大,并且这个链式调用会非常低效。
为了解决这个问题kotlin引入了 惰性集合:序列, 序列中的元素的求值是惰性的,不需要创建集合来保存中间结果,我们可以使用序列来解决上面的问题:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
序列的操作
序列的操作分为两类:中间和末端操作, 以上面那个例子为例:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
map、filter都是中间操作,toList为末端操作。一次中间操作返回的是另一个序列,这个新序列知道如何变换原始序列中的元素,而一次末端操作返回的是一个结果,这个结果可能是集合、元素、数字等。
序列中中间操作的计算都是由末端操作触发的。
我们可以使用扩展函数asSequence把任意集合转换成序列,调用toList来做反向转换
我们来对比一下上面两种方法:
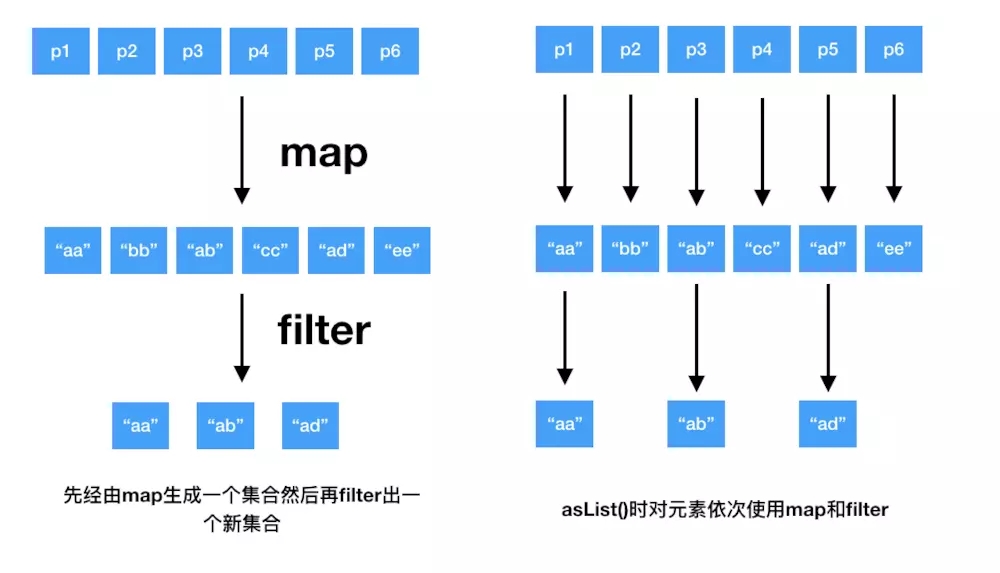
惰性集合.png
可以看到,使用序列会明显比直接使用map和filter来完成这个任务效率更高
- 对原集合只会进行一次遍历
- 只会生成一个结果集合
- 对于混合有any这种集合操作,序列可以明显提高性能。
注意对于混合map/filter,这种操作时,如果被操作集合比较小,是不需要使用序列的。至于序列如何手动创建,这里不做细究
kotlin与Java函数式接口
函数式接口是指带有一个抽象方法的接口,在java api中比如Runnable、Callable等
我们在实际使用kotlin时,可能大部分API还是java API,但是kotlin的lambda可以无缝地和javaAPI互操作,比如给一个button设置onclick事件:
button.setOnClickListener{ //... }
这个操作在java8之前我们不得不通过创建一个匿名内部类来实现。
lambda表达式的可重用性
比如有一个函数postponeComputation(),接收一个函数,并循环执行这个函数指定次数:
postponeComputation(1000, object:Runnable{
override fun run(){
print(42)
}
})
当你显示声明这个参数对象时,每次调用都会创建一个新的实例,而使用lambda情况不同:如果lambda没有访问任何来自自定义它的函数的变量,相应的匿名类实例可以在多次调用中重用:
postponeComputation(1000, { print(42) })
但是如果lambda从包围它的作用域中捕捉了变量,每次调用就不再可能重用同一个实例了。 至于为什么将会在 Lambda的实现细节的讲到。
Lambda的实现细节
在kotlin中,每个函数式接口的lambda都会被编译成一个匿名类(除内联lambda)。如果lambda捕捉了变量,每个被捕捉的变量会在匿名内部类中有对应的字段,而且每次调用这个lambda都会创建一个这个匿名内部类的实例。如果没有捕捉变量,就会创建一个单例的类。
编译后的匿名内部类的名称由lambda声明所在的函数名称加上后缀衍生出来的,比如下面这个lambda:
class Person{
fun test(){
a.setRunnable({
print("a")
})
}
}
这个lambda会被编译成:
class Person$1:Runnable{
override fun run(){
print("a")
}
}
lambda与函数式接口的转换
有些时候我们需要函数式接口的实例,比如一个方法返回的是一个函数式接口,这时候就不能直接返回一个lambda了:
fun getRunnable():Runnable{}
这时候如果直接这样写就会报错 : fun getRunnable() = { } ,这是因为编译器不会智能转换,不过kotlin提供了 函数式接口构造方法来使操作更方便:
fun getRunnable() = Runnable{ }
Runnable{}是编译器生成的方法,等同于使用匿名对象的方式。
带接收者的lambda: with 与 apply
这两个函数式kotlin标准库中的函数。带接受者是指:在lambda函数体可以调用一个不同对象的方法,而且无须借助任何额外限定符。
with
with是一个接收两个参数的函数,一个参数是 被接收者, 它会被传给第二个参数 lambda表达式 , 在lambda表达式着呢个我们可以不用任何限定符直接访问这个值的方法和属性
fun alphabet():String{
val stringBuilder = StringBuilder()
return with(stringBuilder){
for(letter in 'A'..'Z'){
append(letter) //也可以使用this.append()
}
toString()
}
}
with的返回值是执行了lambda代码的结果
apply
apply与with的唯一区别是它始终返回接收者对象。上面的函数我们可以这样改写:
fun alphabet() = StringBuilder().apply{
for(letter in 'A'..'Z'){
append(letter) //也可以使用this.append()
}
}.toString()
内联函数:消除Lambda带来的运行时开销
上面我们已经知道,lambda表达式会被正常地编译成匿名类,这表示每调用一次lambda表达式,一个额外的类就会被创建,为了解决这个运行时性能的开销,kotlin提供了inline修饰符,如果使用inline
修饰符标记一个函数,在函数被使用的时候编译器并不会生成函数调用的代码,而是使用函数实现的真实代码替换每一次的函数调用。
先来举一个例子:
inline fun test(action:()->T){
action()
}
fun foo(){
test{
print("a")
}
}
foo()实际会被编译为下面的代码:
fun foo_(){
print("a")
}
从上面这个例子可以看出,作为参数的lambda表达式会被直接替换到最终生成的代码中,而不是被包含在一个实现了函数接口的匿名类中。
注意如果lambda参数在某个地方被保存起来,以便后面可以继续使用,这种lambda表达式将不会被内联,因为必须要有一个包含这些代码的对象存在
内联的集合操作
kotlin标准库中的map、filter等大部分函数都是内联函数,因此使用标准库函数不需要担心性能开销。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
您可能感兴趣的文章:

- kotlin极简教程 高阶函数 函数式编程章节节选
- ASP.Net教程系列:多线程编程实战(二)
- vue2.0实战案例之高级教程-老孟编程
- 第4章 kotlin代码执行过程《Kotin 编程思想·实战》
- Struts模块化编程经典实战教程(一)
- Kotlin最简单的入门教程——神秘的Lambda
- ASP.Net教程系列:多线程编程实战(一)
- 第5章 Kotlin语言基础 《Kotin 编程思想·实战》
- Struts模块化编程经典实战教程(二)
- C#多线程编程实例实战教程
- VC网络编程实战视频教程
- Kotlin编程之高阶函数,Lambda表达式,匿名函数
- 第6章 扩展函数与属性 《Kotlin 项目实战教程》
- Lambda表达式实战视频教程
- 第9章 Kotlin与Java互操作(Interoperability) 《Kotin 编程思想·实战》
- 嵌入式ARM系统实战开发(编程模型、指令系统、程序设计、混合编程、驱动开发)视频教程
- ASP.Net教程系列:多线程编程实战(一)
- C#写字板问题一二 —— C#+WinForm编程趣味入门实战-天轰穿.NET4趣味编程视频教程
- 第12章 使用Kotlin开发Web应用《Kotin 编程思想·实战》
- 老男孩教育Linux Shell高级编程实战视频教程完整14部分