mysql主从架构搭建+并行复制+MHA原理,搭建MHA,mha的手工,故障切换、修复
mysql主从架构搭建
主机环境
关闭防火墙跟selinux
两台版本、安装方式一致的数据库
配置搭建环境脚本《mysql项目需要的主机基础环境设置》
安装
rpm -ivh libev4-4.15-7.1.x86_64.rpm libev-devel-4.15-21.1.x86_64.rpm percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm
安装依赖包
yum install perl-DBD-mysql
主从架构+mha软件包
都关闭dns
vim /etc/ssh/sshd_config #useDNS yes 改为 useDNS no
修改主从的配置文件
主库配置:
binlog_format=row server-id=3306100 binlog_rows_query_log_events=on log-bin=server
从库配置:
read_only=1 server-id=3306101 binlog_format=row binlog_rows_query_log_events=on log-bin=slave
对主库进行复制
innobackupex --user=root --password=123 /backup/
得到
2018-07-17_14-42-41这个文件
然后应用这个文件
innobackupex --apply-log 2018-07-17_14-42-41/
然后关闭从库数据库,清空数据库
rm –rf * //因为这是实验,所以用rm -rf比较方便,但不推荐用这种方式,可以考虑把文件拷贝到别的地方!!!!很危险的操作!!!
在主库中通过scp传输 将刚才得到的文件传送到从库的/backup目录下/
scp -r 2018-07-17_14-05-15/ root@172.16.10.4:/backup/
回到从库进入到/backup/目录确认
然后执行恢复操作
innobackupex --move-back /backup/2018-07-13_14-05-15/
授权
chown -R mysql:mysql /var/lib/mysql
查看
var/lib/mysql/xtrabackup_info
确保
binlog_pos = filename 'server.000002', position '154'
参数有值
这样就知道主从关系了
在主库
创建从库复制的用户
grant replication slave on *.* to 'repl'@'%' identified by 'repl';
进入从库数据库设置主从关系(在从库上设置)
mysql> CHANGE MASTER TO MASTER_HOST='172.16.10.6', //主库的ip MASTER_USER='repl',MASTER_PASSWORD='repl', MASTER_PORT=3306, MASTER_LOG_FILE='server.000002',MASTER_LOG_POS=154, //来自上面查看 /var/lib/mysql/xtrabackup_info MASTER_CONNECT_RETRY=10; //重连次数
启动从库
mysql> start slave;
启动从库前后 线程对比
mysql> show processlist; +----+------+-----------+------+---------+------+----------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-----------+------+---------+------+----------+------------------+ | 3 | root | localhost | NULL | Query | 0 | starting | show processlist | +----+------+-----------+------+---------+------+----------+------------------+ 1 row in set (0.00 sec) mysql> start slave -> ; Query OK, 0 rows affected (0.01 sec)
mysql> show processlist; +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | 3 | root | localhost | NULL | Query | 0 | starting | show processlist | | 4 | system user | | NULL | Connect | 39 | Connecting to master | NULL | //连接io线程 | 5 | system user | | NULL | Connect | 39 | Slave has read all relay log; waiting for more updates | NULL | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ //SQL线程,日志应用线程 3 rows in set (0.00 sec) mysql> mysql> show slave status \G Slave_IO_State: Waiting for master to send event Slave_IO_Running: Yes Slave_SQL_Running: Yes 主库show processlist; mysql> show processlist; +----+------+-------------------+-------+-------------+------+---------------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+-------------------+-------+-------------+------+---------------------------------------------------------------+------------------+ | 4 | root | localhost | mysql | Query | 0 | starting | show processlist | | 5 | repl | 172.16.10.4:47768 | NULL | Binlog Dump | 465 | Master has sent all binlog to slave; waiting for more updates | NULL | +----+------+-------------------+-------+-------------+------+---------------------------------------------------------------+------------------+ 2 rows in set (0.00 sec)
多了一个Binlog Dump线程
主库 新建一个测试库跟测试表
mysql> create database zhucongfuzhiceshi1 character set =utf8; Query OK, 1 row affected (0.02 sec) mysql> use zhucongfuzhiceshi1; Database changed mysql> create table ceshi as select * from mysql.user; Query OK, 4 rows affected (0.08 sec) Records: 4 Duplicates: 0 Warnings: 0
到从库看一下是否有复制过来
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | zhucongfuzhiceshi1 | +--------------------+ 5 rows in set (0.00 sec)
mysql> use zhucongfuzhiceshi1; Database changed mysql> show tables; +------------------------------+ | Tables_in_zhucongfuzhiceshi1 | +------------------------------+ | ceshi | +------------------------------+ 1 row in set (0.00 sec) select * from ceshi1;
这就达到了一个主从同步的状态
再看一下
(查看主从应用的日志点跑到哪里了)
mysql> show slave status \G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.16.10.6 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: server.000003 Read_Master_Log_Pos: 4112 Relay_Log_File: jiqi4-relay-bin.000003 Relay_Log_Pos: 4319 Relay_Master_Log_File: server.000003 //当前应用到主库的文件位置 现在已经读到server.000003这个日志的4112点了
主从调整为并行复制
并行复制 要修改从库配置文件
并行参数:
slave_preserve_commit_order=1 log_slave_updates=1 slave_parallel_type=logical_clock slave_parallel_workers=4 开启4个线程 master_info_repository=TABLE 调优的值 原来是=file relay_log_info_repository=TABLE 调优的值 原来是=file relay_log_recovery=ON
mysql> show processlist; +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | 1 | system user | | NULL | Connect | 154 | Waiting for master to send event | NULL | | 2 | system user | | NULL | Connect | 154 | Slave has read all relay log; waiting for more updates | NULL | | 3 | system user | | NULL | Connect | 154 | Waiting for an event from Coordinator | NULL | | 4 | system user | | NULL | Connect | 154 | Waiting for an event from Coordinator | NULL | | 5 | system user | | NULL | Connect | 154 | Waiting for an event from Coordinator | NULL | | 6 | system user | | NULL | Connect | 154 | Waiting for an event from Coordinator | NULL | | 9 | root | localhost | NULL | Query | 0 | starting | show processlist | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ 7 rows in set (0.00 sec)
搭建成一主两从架构,并建立互信
先把主从并行复制的两行在配置文件中注释掉
#master_info_repository=TABLE #relay_log_info_repository=TABLE
准备一台新的机器,与主从复制的两台机器mysql版本一致且环境相同(
确保binlog版本相同)
配置新的机器与主库能够主从复制
在主库中show processlist中看到两个dump线程说明一注两从的环境已经搭建好了
三台机器
修改hosts文件
vim /etc/hosts
把三台主机都给备注上,都要备注
127.0 1b024 .0.1 localhost master localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.16.10.6 master 172.16.10.4 beizhu 172.16.10.7 jiankong
建立ssh互信 一台一台机器的来 rsa密钥 建立ssh互信 一台一台机器的来 rsa密钥 #ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: e1:cd:28:b0:b4:c3:4b:4b:4c:f6:4c:39:18:79:50:c6 root@master The key's randomart image is: +--[ RSA 2048]----+ | o=o | | .+E. | | *.+ . | | * B o = | | O + S o | | o + . | | o | | | | | +-----------------+ 将公钥追加到认证文件中 cat /root/.ssh/id_rsa.pub >> authorized_keys 修改权限 chmod 700 /root/.ssh chmod 600 /root/.ssh/authorized_keys 将公钥追传到另外两个机器上 #ssh-copy-id -i /root/.ssh/id_rsa.pub root@beizhu Warning: Permanently added 'beizhu,172.16.10.4' (RSA) to the list of known hosts. root@beizhu's password: Now try logging into the machine, with "ssh 'root@beizhu'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. #ssh-copy-id -i /root/.ssh/id_rsa.pub root@jiankong Warning: Permanently added 'jiankong,172.16.10.7' (RSA) to the list of known hosts. root@jiankong's password: Now try logging into the machine, with "ssh 'root@jiankong'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. 测试现在是不是免密了 [root@master ~]# ssh root@beizhu Warning: Permanently added 'beizhu,172.16.10.4' (RSA) to the list of known hosts. Last login: Mon Jul 16 14:00:18 2018 from 172.16.65.123 [root@beizhu ~]# exit logout Connection to beizhu closed. [root@master ~]# ssh root@jiankong Warning: Permanently added 'jiankong,172.16.10.7' (RSA) to the list of known hosts. Last login: Mon Jul 16 13:34:30 2018 from 172.16.65.123 [root@jiankong ~]# 没有提示输入密码 就可以直接登陆
这样master主机的免密登录另外两台登录做完了,然后做另外两台的
. . .
然后都完成了
在主库上建一个 监控用户 在master上创建监控用户,这样2个从上自动有该用户 mysql> grant all on *.* to 'mha_monitor'@'%' identified by 'mha_monitor'; Query OK, 0 rows affected, 1 warning (0.00 sec) 在另外两台机器上都能以这个用户登录 [root@beizhu mysql]# mysql -umha_monitor -pmha_monitor mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 5.7.21-log MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
配置MHA
在mha-manager即监控主机上执行: 1、创建mha的工作目录 mkdir -p /etc/masterha
在~家目录下建个目录把软件包考进去 mha4mysql-manager-0.55-0.el6.noarch.rpm perl-Mail-Sender-0.8.16-3.el6.noarch.rpm perl-MIME-Types-1.28-2.el6.noarch.rpm mha4mysql-node-0.54-0.el6.noarch.rpm perl-Mail-Sendmail-0.79-12.el6.noarch.rpm perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm perl-Config-Tiny-2.12-7.1.el6.noarch.rpm perl-MailTools-2.04-4.el6.noarch.rpm perl-Params-Validate-0.92-3.el6.x86_64.rpm perl-Email-Date-Format-1.002-5.el6.noarch.rpm perl-MIME-Lite-3.027-2.el6.noarch.rpm perl-TimeDate-1.16-13.el6.noarch.rpm perl-Log-Dispatch-2.27-1.el6.noarch.rpm perl-MIME-Lite-HTML-1.23-2.el6.noarch.rpm
yum 安装这些文件 yum localinstall ./*.rpm
改一下配置文件,这是自己编写的一个配置文件 vim /etc/masterha/app1.cnf
[root@jiankong ~]# cat /etc/masterha/app1.cnf [server default] manager_workdir=/var/log/masterha/app1 manager_log=/var/log/masterha/app1/manager.log master_binlog_dir=/var/lib/mysql #主库上binlog的位置 master_ip_failover_script=/usr/bin/master_ip_failover master_ip_online_change_script=/usr/bin/master_ip_online_change user=mha_monitor password=mha_monitor ping_interval=1 remote_workdir=/tmp repl_user=repl repl_password=repl ssh_user=root [server1] hostname=172.16.10.6 candidate_master=1 port=3306 [server2] hostname=172.16.10.4 candidate_master=1 check_repl_delay=0 port=3306 [server3] hostname=172.16.10.7 port=3306
在2个从节点(备主跟监控)设置relay_log_purge=0,不自动清除relay_log,
mysql> set global relay_log_purge=0; Query OK, 0 rows affected (0.00 sec)
主库关闭,从库开启
并设置到配置文件中,最好是这三台机器主从都给配置上
可以利用自带的purge_relay_log脚本实现定时任务自动清理relay log,此处不赘述
将mha的故障切换脚本和在线切换脚本放在/usr/bin下去:
master_ip_failover
master_ip_online_change
mha的故障切换脚本和在线切换脚本
给这两个脚本可执行权限
[root@jiankong bin]# chmod +x master_ip_failover [root@jiankong bin]# chmod +x master_ip_online_change
检查ssh配置:
masterha_check_ssh --conf=/etc/masterha/app1.cnf
最后显示
Mon Jul 16 19:45:18 2018 - [info] All SSH connection tests passed successfully.
在主库上配置vip vip的作用是当有应用连接数据库的时候,连接的是一个虚拟ip 作用是 当后端有故障切换的时候,对于应用来说切换是透明的,不需要修改任何东西 (啥意思 ,,??) 在主库上配置vip:ifconfig eth0:1 192.168.120.120/24
[root@master bin]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:3b:d7:0f brd ff:ff:ff:ff:ff:ff inet 172.16.10.6/16 brd 172.16.255.255 scope global eth1 inet6 fe80::20c:29ff:fe3b:d70f/64 scope link valid_lft forever preferred_lft forever
[root@master bin]# ifconfig eth1:1 172.16.10.9/16 [root@master bin]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:3b:d7:0f brd ff:ff:ff:ff:ff:ff inet 172.16.10.6/16 brd 172.16.255.255 scope global eth1 inet 172.16.10.9/16 brd 172.16.255.255 scope global secondary eth1:1 inet6 fe80::20c:29ff:fe3b:d70f/64 scope link valid_lft forever preferred_lft forever (如何删除虚拟ip:ip addr del 192.168.120.120/24 dev eth0)
[root@jiankong ~]# ifconfig eth1:1 172.16.10.8/16 在manager上编辑2个切换脚本内容,修改vip地址和vip设备名 检查read_only参数,主上一定是off,从上一定时on(该参数可动态全局修改)
[root@jiankong bin]# vim master_ip_failover my $vip = '172.16.10.9/16'; # Virtual IP 主库上设置的虚拟ip my $key = "1"; my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; beizhu的网口 my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down"; 主库的网口 my $exit_code = 0;
[root@jiankong bin]# vim master_ip_online_change vip=`echo '172.16.10.9/16'` # Virtual IP key=`echo '1'` stop_vip=`echo "ssh root@$orig_master_host /sbin/ifconfig eth1:$key down"` start_vip=`echo "ssh root@$new_master_host /sbin/ifconfig eth0:$key $vip"`
检查复制环境: masterha_check_repl --conf=/etc/masterha/app1.cnf MySQL Replication Health is OK. 检查manager节点的状态: masterha_check_status --conf=/etc/masterha/app1.cnf 开启manager监控: nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 & [root@jiankong bin]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 & [1] 4704 [root@jiankong bin]# masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:4704) is running(0:PING_OK), master:172.16.10.6
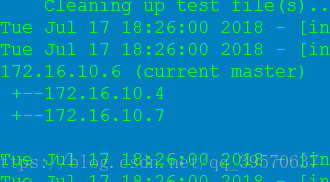
故障切换测试
直接在新的主库上进行failover,杀掉mysqld进程 这时候会自动完成故障切换,vip的漂移,但是manager进程会自动关闭 就是原来的 主库又重新变成了主库 mysql> show processlist; +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ | 31 | root | localhost | NULL | Query | 0 | starting | show processlist | | 53 | repl | jiankong:43568 | NULL | Binlog Dump | 6 | Master has sent all binlog to slave; waiting for more updates | NULL | +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ 2 rows in set (0.00 sec) master主机又变成了主库 beizhu主机从mha环境中剥离出来
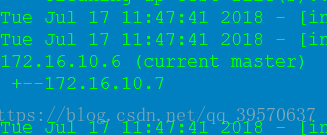
通过修复重新加入
旧主上默认不会自动指向新主,需要进行恢复操作:
通常情况下,旧主在修复完整后,可能想把旧主作为新主的slave,这时可以借助当时自动切换时刻的MHA日志来完成对旧主的修复。
手工在线测试
检查master_ip_online_change脚本中所有虚拟ip是否修改完成。
1、MHA里有2个角色,一个是manager节点,一个是node节点,要实现这个MHA,最好是不少于3台机器,一主2从,1台是主,一台当备用master,另一台从机当监控机,一旦主库宕机,备主开始充当主库提供服务,如果旧主上线也不会在成为master了,除非修复完整后强制做主库。
2、一旦发生切换,manager进程将会退出,无法进行再次测试,需要将故障数据库加入到MHA环境中。
在线切换步骤: 1、手工停掉mha监控 masterha_stop --conf=/etc/masterha/app1.cnf 2、执行在线切换 masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.16.10.4 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 改成备主的ip 让备主 切换成主
其中参数的意思:
–orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动。
–running_updates_limit=10000,故障切换时,候选 master 如果有延迟的话,mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为 s),但是切换的时间长短是由 recover 时 relay 日志的大小决定。
在备主和监控机上查看是否完成切换:show processlist;
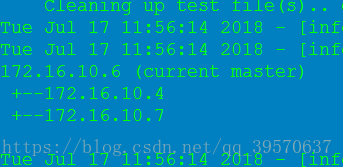
yes,yes From: 172.16.10.6 (current master) +--172.16.10.4 +--172.16.10.7 To: 172.16.10.4 (new master) +--172.16.10.7 +--172.16.10.6 Tue Jul 17 09:08:01 2018 - [info] Switching master to 172.16.10.4(172.16.10.4:3306) completed successfully.
这个时候看一下新的主库beizhu的状态
mysql> show processlist; +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ | 2 | root | localhost | NULL | Query | 0 | starting | show processlist | | 10 | repl | jiankong:52817 | NULL | Binlog Dump | 44 | Master has sent all binlog to slave; waiting for more updates | NULL | | 11 | repl | master:37647 | NULL | Binlog Dump | 44 | Master has sent all binlog to slave; waiting for more updates | NULL | +----+------+----------------+------+-------------+------+---------------------------------------------------------------+------------------+ 3 rows in set (0.00 sec)
跟新的从库master的状态
mysql> show processlist; +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | 31 | root | localhost | NULL | Query | 0 | starting | show processlist | | 41 | system user | | NULL | Connect | 138 | Waiting for master to send event | NULL | | 42 | system user | | NULL | Connect | 138 | Slave has read all relay log; waiting for more updates | NULL | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ 3 rows in set (0.00 sec)
这样主库上虚拟ip没了 虚拟ip到了beizhu上
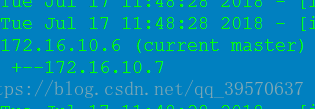
在jiankong上启动监控 nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 & masterha_check_status --conf=/etc/masterha/app1.cnf
修复
在manager上查看当时的change master 信息:
cat /var/log/masterha/app1/manager.log |grep -i “All other slaves should start”
Tue Jul 17 11:22:08 2018 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=’172.16.10.6’, MASTER_PORT=3306, MASTER_LOG_FILE=’server.000001’, MASTER_LOG_POS=154, MASTER_USER=’repl’, MASTER_PASSWORD=’xxx’;
可利用这个信息做beizhu(原主)的修复
在jiankong上检查监控状态(默认故障切换后关闭)
检查复制看到只有一个从
在beizhu上 mysql> CHANGE MASTER TO MASTER_HOST='172.16.10.6', MASTER_PORT=3306, MASTER_LOG_FILE='server.000001', MASTER_LOG_POS=154, MASTER_USER='repl', MASTER_PASSWORD='repl'; Query OK, 0 rows affected, 2 warnings (0.03 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
mysql> show processlist; +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | 2 | root | localhost | NULL | Query | 0 | starting | show processlist | | 3 | system user | | NULL | Connect | 8 | Waiting for master to send event | NULL | | 4 | system user | | NULL | Connect | 8 | Slave has read all relay log; waiting for more updates | NULL | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ 3 rows in set (0.00 sec)
再次检查复制看到还是只有一主一从
这是因为切换后故障的主机已经从配置文件中删除了
查看配置文件发现[server2]这一栏没有了,需要手动添加
或者是通过这个命令
masterha_conf_host –command=add –conf=/etc/masterha/app1.cnf –hostname=172.16.10.4 –block=server1 –params=”no_master=1;ignore_fail=1”
添加完成后检查复制环境,已经恢复到三台主机
MHA切换原理分析
MHA架构有MHA manager和MHA node组成,关系图如下:
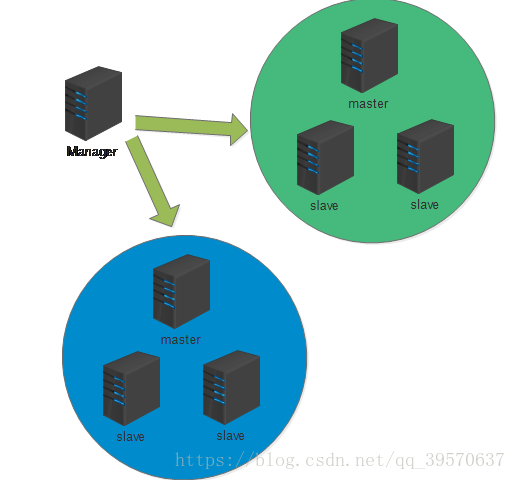
MHA manager介绍:
实际上,一个manager可以用力多个master-slave集群,通过运行工具可以实现master 主机的故障切换、手动故障切换、连接检查等等功能。
MHA node
部署在所有运行MySQL的服务器上,无论是master还是slave。主要作用有三个。
1).保存二进制日志
如果能够访问故障master,会拷贝master的二进制日志
2).应用差异中继日志
从拥有最新数据的slave上生成差异中继日志,然后应用差异日志。
3).清除中继日志
在不停止SQL线程的情况下删除中继日志
切换过程及原理:
1). 从宕机崩溃的Master保存二进制日志事件(binlogevent)
2). 识别含有最新更新的Slave
3). 应用差异的中继日志(relaylog)到其他Slave
4). 应用从Master保存的二进制日志事件
5). 提升一个Slave为新的Master
6). 使其他的Slave连接新的Master进行复制

- MHA故障切换和在线手工切换原理
- MHA故障切换和在线手工切换原理
- MHA故障切换和在线手工切换原理
- MySQL高可用方案MHA在线切换的步骤及原理
- 浅谈秒级故障切换!用MHA轻松实现MySQL高可用(三)
- centos下mysql高可用架构MHA搭建及测试故障转移 推荐
- 【MySQL】【高可用】基于MHA架构的MySQL高可用故障自动切换架构
- MYSQL之MHA实现VIP故障切换使用脚本(可用)
- 浅谈秒级故障切换!用MHA轻松实现MySQL高可用(一)
- 秒级故障切换!用MHA轻松实现MySQL高可用(二)
- 秒级故障切换!用MHA轻松实现MySQL高可用(三)
- Mysql高可用架构MHA搭建及测试故障转移
- 使用Innobackupex快速搭建(修复)MySQL主从架构
- 互联网金融MySQL高可用架构之-MHA故障切换
- Mysql主从架构的复制原理
- MySQL半同步复制的搭建和配置原理
- MySQL5.6基于MHA方式高可用搭建
- MySQL高可用方案:基于MHA实现的自动故障转移群集
- MySQL主从集群构建及故障切换
- MySQL-MHA搭建