两种网页爬虫技术实现跨域(nodejs+java)(解决'X-Frame-Options'问题)
一.方法介绍:
在自己的多次百度方法尝试过程中,主要有两种方法推荐如下
1.使用iframe标签嵌套,然后将iframe的src设置成外网的链接,这样的话就可以把别人的网站加载进来,里面的dom结构和数据什么的都随便你去取(页面中能看到的)。
2.通过nodejs爬虫技术实现(针对那些已经安装nodejs的可以去尝试,不然先安装nodejs)
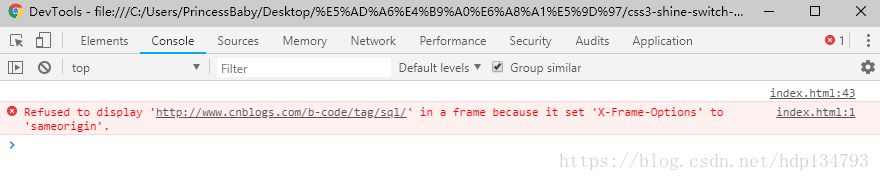
但是我个人更推荐nodejs来做,主要原因是现在很多网页都针对iframe引用网页做了拦截,所以当你使用iframe的时候就会发现存在这个问题。
Refused to display ‘http://www.xxx.com/’ in a frame because it set ‘X-Frame-Options’ to ‘sameorigin’.
也就是说很多网页通过设置’X-Frame-Options’来防止网页放在iframe中,这样的话就不能达到自己想要的效果。包括今后自己的网页都可以通过这方式来做限制。其次node爬虫相对其他语言(比如Python)性能更好,是服务器端的js且异步,爬网页数据更具优势。
二.Nodejs怎么去实现爬虫技术?
1.主要知识点介绍
Request模块:主要作用是用来请求网页的。
Cheerio模块:主要是分析页面中的dom结构的。
2.具体实现过程
A.nodejs项目的搭建,这个可以看我之前的博客,里面有相对详细的介绍。在一个空的项目文件夹下执行nmp init命令进行初始化node项目,这样的话在你创建的文件夹下会生成一个package.json文件
B.依赖版本的更新,针对文件中的新增下面一行
“dependencies”: { “cheerio”: “0.12.3”, “request”: “2.27.0” }
然后执行nmp update这样的话会自动从仓库将最新依赖版本进行更新
3.编写代码模块,新建一个index.js文件
代码如下(内含注释):
//定义有关页面请求模块和dom解析模块
var request = require('request');
var cheerio = require('cheerio');
/*var getNewsList=function(done) {
request('http://jwc.scu.edu.cn/jwc/frontPage.action', function (err, res) {
if (err) return console.error(err);
var $ = cheerio.load(res.body.toString());
});
};*/
var getNewsList=function(done) {
var news = new Array();
request('https://www.cnblogs.com/b-code/p/6178535.html', function (err, res) {
if (err) return console.error(err);
var t = setTimeout(function(){
//核心代码模块,通过cheerio来分析dom结构
var $ = cheerio.load(res.body.toString());
//解析获取的dom结构,从中获取你想要的数据或者dom结构
var table=$('body').children('div').eq(0).html();
console.log(table);
},1000)
});
};
getNewsList();
4.执行该js文件node index.js,这样的话在控制台会打印出你所需要的数据。
三.执行这个过程中遇到的问题
关于很多时候会出现关于cannot find module ‘xxx’系列的东西,解决方法基本都是nmp install xxx
四.思维拓展
我们如何通过java来实现从服务器上面捞数据(前提是知道捞取文件的路径)
代码如下:
@ResponseBody
@RequestMapping(value = "/getTxtdata")
public String getTxtdata(String urlstr){
//这个urlstr我是通过前端传递过来的,然后把读取到的数据string形式返回给前端
String returnstr = "no data";
URL myurl;
try {
myurl = new URL(urlstr);
URLConnection uc;
try {
uc = myurl.openConnection();
InputStreamReader isr=new InputStreamReader(uc.getInputStream());//获取服务器端字节流
BufferedReader br=new BufferedReader(isr);//读文件
String s=br.readLine();//读行
returnstr = s;
System.out.println(s);//输出
br.close();//关闭
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}//创建连接
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}//创建URL对象
return returnstr;
}
这样前后端数据进行交互,就可以在很大程度上面规避访问X-Frame-Options的问题啦
测试不易,喜欢的话关注下或者给点赞赏吧!
皮一下很开心,这个zfb二维码是认真的,实在土豪可以扫一扫扶贫,>=10元的将将代写表白情诗一首
(支付宝加好友(2393703536@qq.com)私发对象名字)

扶贫1元(备注城市)即上榜,看看有多少人
自己购买云服务,写了一套代码表示感谢,感恩我是认真的
http://www.bcodelove.top:8080/bcode/jsp/apphome/rewardlist/rewardlist.html

- HTML5和HLS协议两种技术完美结合解决移动端网页播放问题
- nodejs服务实现反向代理,解决本地开发接口请求跨域问题
- HTML5和HLS协议两种技术完美结合解决移动端网页播放问题
- java网页爬虫遇到的问题及解决方法
- 爬虫技术(2)--抓取网页java代码实现
- 同样一个问题的两种 java 实现代码 的比较
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决
- 解决ASP.NET AJAX在frame及iframe中跨域访问的问题
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决,文件操作
- 转:Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决,文件操作
- Java 编程技术中汉字问题的分析及解决
- Java 编程技术中汉字问题的分析及解决,文件操作
- Java 编程技术中汉字问题的分析及解决,文件操作