Python-pandas-Series/DataFrame入门
2018-07-25 10:28
826 查看
练习知识点取自:
http://python.jobbole.com/89084/?utm_source=group.jobbole.com&utm_medium=relatedArticles
[code]>>> import pandas as pd
>>> import numpy as np
>>> series1 = pd.Series([1,2,3,4])
>>> print("series1:\n{}\n".format(series1))
series1:
0 1
1 2
2 3
3 4
dtype: int64
>>> #输出的最后一行是Series中数据的类型,这里的数据都是int64类型的。
>>> #数据在第二列输出,第一列是数据的索引,在pandas中称之为Index。
>>> series2 = pd.Series(['胡歌','霍建华','钟汉良','居老师'])
>>> print('series2:\n{}\n'.format(series2))
series2:
0 胡歌
1 霍建华
2 钟汉良
3 居老师
dtype: object
>>> series3 = pd.Series([3.14,7.0,4,888])
>>> print('series3:\n{}\n'.format(series3))
series3:
0 3.14
1 7.00
2 4.00
3 888.00
dtype: float64
>>> #我们可以分别打印出Series中的数据和索引:
>>> print('series2.values:{}\n'.format(series2.values))
series2.values:['胡歌' '霍建华' '钟汉良' '居老师']
>>> print('series3.values:{}\n'.format(series3.values))
series3.values:[ 3.14 7. 4. 888. ]
>>> print('series3.values:{}\n'.format(series1.values))
series3.values:[1 2 3 4]
>>> print('series1.index:{}\n'.format(series1.index))
series1.index:RangeIndex(start=0, stop=4, step=1)
>>> #索引未必一定需要是整数,可以是任何类型的数据,例如字符串。
>>> index2=['A','B','C','D']
>>> print('series2:\n{}\n'.format(series2))
series2:
0 胡歌
1 霍建华
2 钟汉良
3 居老师
dtype: object
>>> series2 = pd.Series(['胡歌','霍建华','钟汉良','居老师']),index=['A','B','C','D']
SyntaxError: can't assign to function call
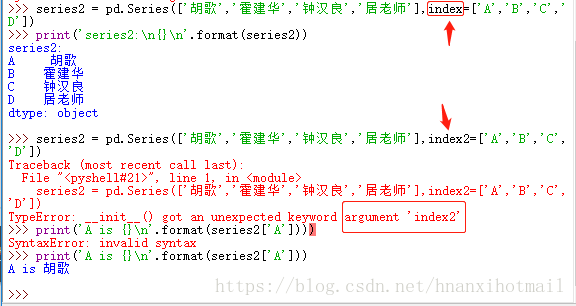
>>> series2 = pd.Series(['胡歌','霍建华','钟汉良','居老师'],index=['A','B','C','D'])
>>> print('series2:\n{}\n'.format(series2))
series2:
A 胡歌
B 霍建华
C 钟汉良
D 居老师
dtype: object
>>> series2 = pd.Series(['胡歌','霍建华','钟汉良','居老师'],index2=['A','B','C','D'])
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
series2 = pd.Series(['胡歌','霍建华','钟汉良','居老师'],index2=['A','B','C','D'])
TypeError: __init__() got an unexpected keyword argument 'index2'
>>> print('A is {}\n'.format(series2['A'])))
SyntaxError: invalid syntax
>>> print('A is {}\n'.format(series2['A']))
A is 胡歌
>>>


[code]>>> #--------------------------DataFrame-------------------------
>>> #创建一个4x4矩阵
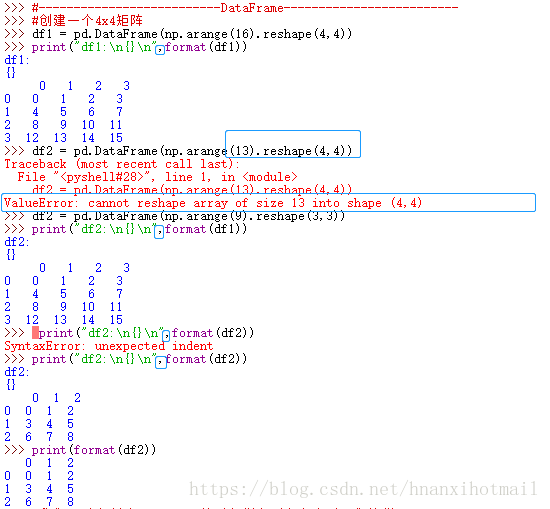
>>> df1 = pd.DataFrame(np.arange(16).reshape(4,4))
>>> print("df1:\n{}\n",format(df1))
df1:
{}
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
>>> df2 = pd.DataFrame(np.arange(13).reshape(4,4))
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
df2 = pd.DataFrame(np.arange(13).reshape(4,4))
ValueError: cannot reshape array of size 13 into shape (4,4)
>>> df2 = pd.DataFrame(np.arange(9).reshape(3,3))
>>> print("df2:\n{}\n",format(df1))
df2:
{}
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
>>> print("df2:\n{}\n",format(df2))
SyntaxError: unexpected indent
>>> print("df2:\n{}\n",format(df2))
df2:
{}
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
>>> print(format(df2))
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
[code]>>> #我们可以在创建DataFrame的时候指定列名和索引,像这样:
>>> df3=pd.DataFrame(np.arange(16).reshape(4,4),columns=['column1','column2','column3','column4'],index=['a','b','c','d'])
>>> print('df3:\n{}\n'.format(df3))
df3:
column1 column2 column3 column4
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
>>> print("df2:\n{}\n".format(df2))
df2:
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
>>> #可以直接指定列数据来创建DataFrame:
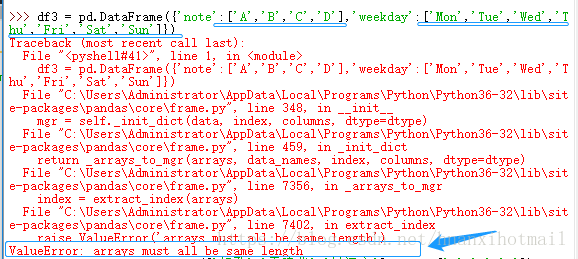
>>> df3 = pd.DataFrame({'note':['A','B','C','D','E','F','G'],'weekday':['Mon','Tue','Wed','Thu','Fri','Sat','Sun']})
>>> print('df3:\n{}\n'.format(df3))
df3:
note weekday
0 A Mon
1 B Tue
2 C Wed
3 D Thu
4 E Fri
5 F Sat
6 G Sun

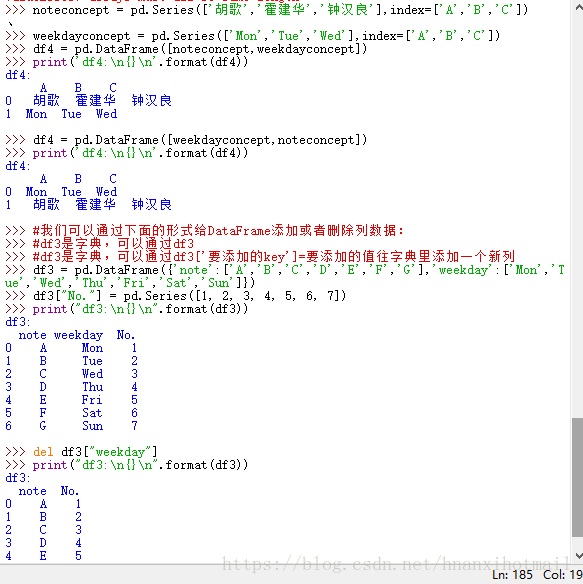
[code]>>> noteconcept = pd.Series(['胡歌','霍建华','钟汉良'],index=['A','B','C'])
、
>>> weekdayconcept = pd.Series(['Mon','Tue','Wed'],index=['A','B','C'])
>>> df4 = pd.DataFrame([noteconcept,weekdayconcept])
>>> print('df4:\n{}\n'.format(df4))
df4:
A B C
0 胡歌 霍建华 钟汉良
1 Mon Tue Wed
>>> df4 = pd.DataFrame([weekdayconcept,noteconcept])
>>> print('df4:\n{}\n'.format(df4))
df4:
A B C
0 Mon Tue Wed
1 胡歌 霍建华 钟汉良
>>> #我们可以通过下面的形式给DataFrame添加或者删除列数据:
>>> #df3是字典,可以通过df3
>>> #df3是字典,可以通过df3['要添加的key']=要添加的值往字典里添加一个新列
>>> df3 = pd.DataFrame({'note':['A','B','C','D','E','F','G'],'weekday':['Mon','Tue','Wed','Thu','Fri','Sat','Sun']})
>>> df3["No."] = pd.Series([1, 2, 3, 4, 5, 6, 7])
>>> print("df3:\n{}\n".format(df3))
df3:
note weekday No.
0 A Mon 1
1 B Tue 2
2 C Wed 3
3 D Thu 4
4 E Fri 5
5 F Sat 6
6 G Sun 7
>>> del df3["weekday"]
>>> print("df3:\n{}\n".format(df3))
df3:
note No.
0 A 1
1 B 2
2 C 3
3 D 4
4 E 5
5 F 6
6 G 7
格式!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
[code]>>> print("df:\n{}\n".format(pd.isna(df)))
df:
0 1 2 3
0 False True False False
1 False True True False
2 False True True False
3 False True False False
>>> #通过pandas.isna函数来确认哪些值是无效
>>> #True表示是无效值
>>> #可以通过pandas.DataFrame.dropna函数抛弃无效值:
>>> print('df.dropna():\n{}\n'.format(df.dropna()))
df.dropna():
Empty DataFrame
Columns: [0, 1, 2, 3]
Index: []
>>> #对于原先的结构,当无效值全部被抛弃之后,将不再是一个有效的DataFrame,因此这行代码输出如上
>>> #也可以选择抛弃整列都是无效值的那一列:
>>> #注:axis=1表示列的轴。how可以取值’any’或者’all’,默认是前者
>>> print("df.dropna(axis=1, how='all'):\n{}\n".format(df.dropna(axis=1, how='all')))
df.dropna(axis=1, how='all'):
0 2 3
0 1.0 3.0 4.0
1 5.0 NaN 8.0
2 9.0 NaN 12.0
3 13.0 15.0 16.0

[code]
>>> #---------------------------替换无效值---------------------------
>>> #通过fillna函数将无效值替换成为有效值:
>>> print("df.fillna(0):\n{}\n".format(df.fillna(0)))
df.fillna(0):
0 1 2 3
0 1.0 0.0 3.0 4.0
1 5.0 0.0 0.0 8.0
2 9.0 0.0 0.0 12.0
3 13.0 0.0 15.0 16.0
>>> print("df.fillna(-1):\n{}\n".format(df.fillna(-1)))
df.fillna(-1):
0 1 2 3
0 1.0 -1.0 3.0 4.0
1 5.0 -1.0 -1.0 8.0
2 9.0 -1.0 -1.0 12.0
3 13.0 -1.0 15.0 16.0
>>> print("df.fillna('无效'):\n{}\n".format(df.fillna('无效')))
df.fillna('无效'):
0 1 2 3
0 1.0 无效 3 4.0
1 5.0 无效 无效 8.0
2 9.0 无效 无效 12.0
3 13.0 无效 15 16.0
>>> #可以指定不同的数据来进行填充,为了便于操作,在填充之前,我们可以先通过'rename'方法修改行和列的名称
>>> df.rename(index={0: 'index1', 1: 'index2', 2: 'index3', 3: 'index4'},
columns={0: 'col1', 1: 'col2', 2: 'col3', 3: 'col4'},
inplace=True)
>>> df.fillna(value={'col2': 222}, inplace=True)
>>> df.fillna(value={'col3': 777}, inplace=True)
>>> print("df:\n{}\n".format(df))
df:
col1 col2 col3 col4
index1 1.0 222.0 3.0 4.0
index2 5.0 222.0 777.0 8.0
index3 9.0 222.0 777.0 12.0
index4 13.0 222.0 15.0 16.0
[code]>>> #-----------------------------处理字符串---------------------------------
>>> #Series的str字段包含了一系列的函数用来处理字符串。并且,这些函数会自动处理无效值。
>>> s1 = pd.Series([' 1', '2 ', ' 3 ', '4', '5'])#PS:空格
>>> print("s1.str.rstrip():\n{}\n".format(s1.str.lstrip()))
s1.str.rstrip():
0 1
1 2
2 3
3 4
4 5
dtype: object
>>> print("s1.str.strip():\n{}\n".format(s1.str.strip()))
s1.str.strip():
0 1
1 2
2 3
3 4
4 5
dtype: object
>>> print("s1.str.isdigit():\n{}\n".format(s1.str.isdigit()))
s1.str.isdigit():
0 False
1 False
2 False
3 True
4 True
dtype: bool
>>> #下面是另外一些示例,展示了对于字符串大写,小写以及字符串长度的处理
>>> s2 = pd.Series(['Stairway to Heaven', 'Eruption', 'Freebird',
'Comfortably Numb', 'All Along the Watchtower'])
>>> print("s2.str.lower():\n{}\n".format(s2.str.lower()))
s2.str.lower():
0 stairway to heaven
1 eruption
2 freebird
3 comfortably numb
4 all along the watchtower
dtype: object
>>> print("s2.str.upper():\n{}\n".format(s2.str.upper()))
s2.str.upper():
0 STAIRWAY TO HEAVEN
1 ERUPTION
2 FREEBIRD
3 COMFORTABLY NUMB
4 ALL ALONG THE WATCHTOWER
dtype: object
>>> print("s2.str.len():\n{}\n".format(s2.str.len()))
s2.str.len():
0 18
1 8
2 8
3 16
4 24
dtype: int64
阅读更多

相关文章推荐
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
- Python Pandas常用数据结构Series和DataFrame的相关操作
- python pandas中series与dataframe数据类型属性及操作基础
- python-pandas-Series和DataFrame数据结构构建
- python-pandas-Series和DataFrame的基本功能
- 数据结构之--series,DataFrame.use python and pandas for data mining
- Pandas数据分析工具入门(Series&Dataframe)
- python之pandas的基本使用-series和dataframe(1)
- Python_pandas 两种主要的数据类型(Series、DataFrame)
- python Dataframe pandas 将数据分割成时间跨度相等的数据块
- python 数据处理学习pandas之DataFrame(二)
- pandas Series DataFrame 丢弃指定轴上的项(三)
- python在pandas.DataFrame添加一行
- 用python做数据分析4|pandas库介绍之DataFrame基本操作 by 是蓝先生
- Python 数据处理扩展包: pandas 模块的DataFrame介绍(创建和基本操作)
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- Python pandas.DataFrame调整列顺序及修改index名
- python pandas.DataFrame选取、修改数据最好用.loc,.iloc,.ix
- python:pandas模块中的DataFrame结构及常用操作
- python pandas.DataFrame选取、修改数据最好用.loc,.iloc,.ix