用scrapy-redis爬去新浪-以及把数据存储到mysql\mongo
2018-07-17 09:47
525 查看
需求:爬取新浪网导航页([u]http://news.sina.com.cn/guide/[/u])所有下所有大类、小类、小类里的子链接,以及子链接页面的新闻内容。
准备工作:
a.安装redis(windows或者linux)
b.安装Redis Desktop Manager
c.scrapy-redis的安装以及scrapy的安装
d.安装mongo
e.安装mysql
进入mysina目录:cd mysina
创建spider爬到:scrapy genspider sina sina.com
执行运行项目脚本命令:scrapy crawl sina
1.item.py
2.spiders/sina_info.py
3.pipelines.py
4.settings.py
5.start.py
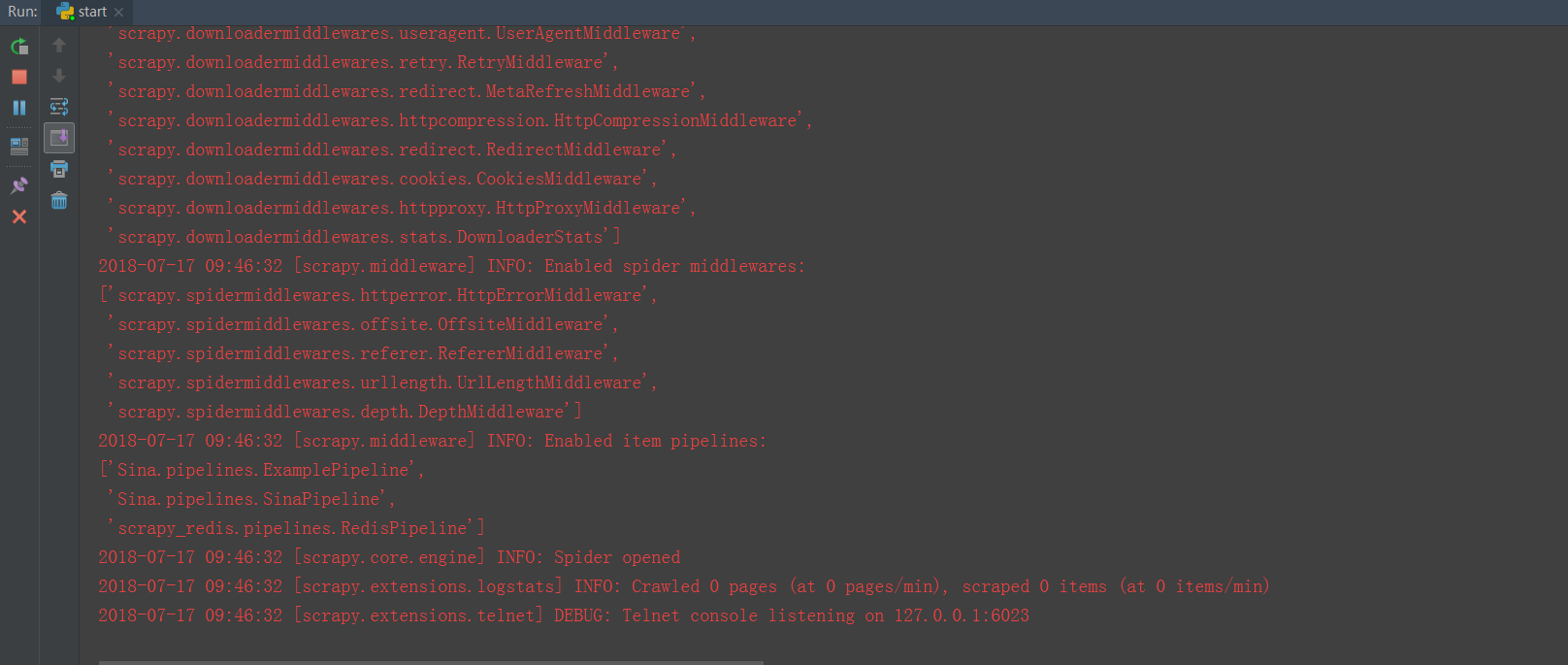
6.运行start.py,的效果图,等待指令。。。。。。
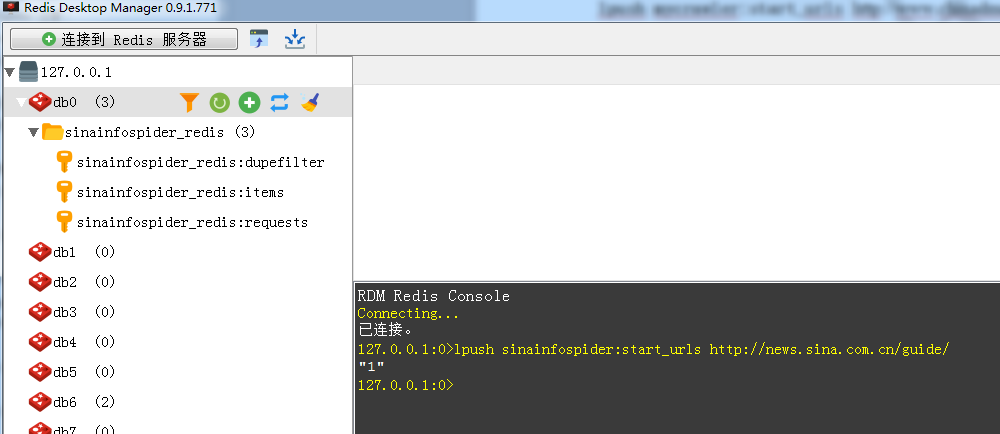
7.Redis Desktop Manager输入以下指令
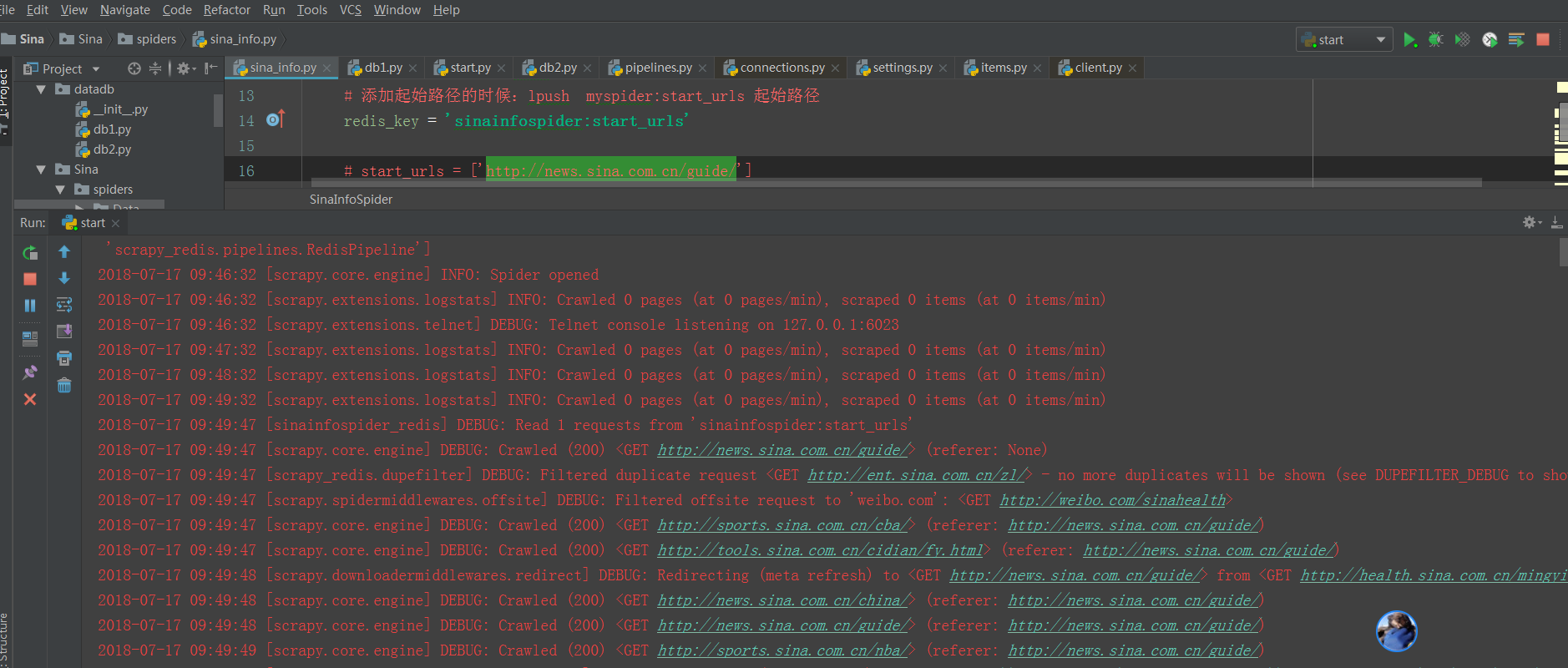
此时开始爬数据的效果图:
8.数据保存到mongo数据库
9.存到mysql数据库
准备工作:
a.安装redis(windows或者linux)
b.安装Redis Desktop Manager
c.scrapy-redis的安装以及scrapy的安装
d.安装mongo
e.安装mysql
[b][b]创建项目和相关配置[/b][/b]
创建项目命令:scrapy startproject mysina进入mysina目录:cd mysina
创建spider爬到:scrapy genspider sina sina.com
执行运行项目脚本命令:scrapy crawl sina
1.item.py
import scrapy class SinaItem(scrapy.Item): #大标题 parent_title = scrapy.Field() #大标题对应的链接 parent_url = scrapy.Field() #小标题 sub_title = scrapy.Field() #小标题的链接 sub_url = scrapy.Field() #大标题和小标题对应的目录 sub_file_name = scrapy.Field() #新闻相关内容 son_url = scrapy.Field() #帖子标题 head = scrapy.Field() #帖子的内容 content = scrapy.Field() #帖子最后存储的位置 son_path = scrapy.Field() spider = scrapy.Field() url = scrapy.Field() crawled = scrapy.Field()
2.spiders/sina_info.py
import scrapy,os
from scrapy_redis.spiders import RedisSpider
from Sina.items import SinaItem
class SinaInfoSpider(RedisSpider):
name = 'sinainfospider_redis'
allowed_domains = ['sina.com.cn']
# 添加起始路径的时候:lpush myspider:start_urls 起始路径
redis_key = 'sinainfospider:start_urls'
# start_urls = ['http://news.sina.com.cn/guide/']
def parse_detail(self,response):
"""解析帖子的数据"""
item = response.meta["item"]
#帖子链接
item["son_url"] = response.url
print("response.url===",response.url)
heads = response.xpath('//h1[@class="main-title"]/text()|//div[@class="blkContainerSblk"]/h1[@id="artibodyTitle"]/text()').extract()
head = "".join(heads)
#把节点转换成unicode编码
contents = response.xpath('//div[@class="article"]/p/text()|//div[@id="artibody"]/p/text()').extract()
content = "".join(contents)
item["content"] = content
item["head"] = head
# print("item=====",item)
yield item
#解析第二层的方法
def parse_second(self,response):
#得到帖子的链接
# print("parse_second--response.url====", response.url)
son_urls = response.xpath('//a/@href').extract()
item = response.meta["item"]
parent_url = item["parent_url"]
# print("item====",item)
for url in son_urls:
#判断当前的页面的链接是否属于对应的类别
if url.startswith(parent_url) and url.endswith(".shtml"):
#请求
yield scrapy.Request(url, callback=self.parse_detail, meta={"item": item})
def parse(self, response):
# print("response.url====",response.url)
#所以的大标题
parent_titles = response.xpath('//h3[@class="tit02"]/a/text()').extract()
# 大标题对应的所以的链接
parent_urls = response.xpath('//h3[@class="tit02"]/a/@href').extract()
#所有小标题
sub_titles = response.xpath('//ul[@class="list01"]/li/a/text()').extract()
#所以小标题对应的链接
sub_urls = response.xpath('//ul[@class="list01"]/li/a/@href').extract()
items = []
for i in range(len(parent_titles)):
#http://news.sina.com.cn/ 新闻
parent_url = parent_urls[i]
parent_title = parent_titles[i]
for j in range(len(sub_urls)):
#http://news.sina.com.cn/world/ 国际
sub_url = sub_urls[j]
sub_title = sub_titles[j]
#判断url前缀是否相同,相同就是属于,否则不属于
if sub_url.startswith(parent_url):
#装数据
#创建目录
sub_file_name = "./Data/"+parent_title+"/"+sub_title
if not os.path.exists(sub_file_name):
#不存在就创建
os.makedirs(sub_file_name)
item["parent_url"] = parent_url
item["parent_title"] = parent_title
item["sub_url"] = sub_url
item["sub_title"] = sub_title
item["sub_file_name"] = sub_file_name
items.append(item)
#把列表的数据取出
for item in items:
sub_url = item["sub_url"]
#meta={"item":item} 传递item引用SinaItem对象
yield scrapy.Request(sub_url,callback=self.parse_second,meta={"item":item})3.pipelines.py
from datetime import datetime
import json
class ExamplePipeline(object):
def process_item(self, item, spider):
# 当前爬取的时间
item["crawled"] = datetime.utcnow()
# 爬虫的名称
item["spider"] = spider.name + "_唠叨"
return item
class SinaPipeline(object):
def open_spider(self, spider):
self.file = open(spider.name + ".json", "w", encoding="utf-8")
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
print("item====", item)
sub_file_name = item["sub_file_name"]
print("sub_file_name==", sub_file_name)
content = item["content"]
if len(content) > 0:
file_name = item["son_url"]
# 切片,从右边查找,替换
file_name = file_name[7:file_name.rfind(".")].replace("/", "_")
# './Data/新闻/国内',
# './Data/新闻/国内/lslsllll.txt',
file_path = sub_file_name + "/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
item["son_path"] = file_path
return item4.settings.py
BOT_NAME = 'Sina'
SPIDER_MODULES = ['Sina.spiders']
NEWSPIDER_MODULE = 'Sina.spiders'
#模拟浏览器身份
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
#使用scrapy_redis自己的去重处理器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#使用scrapy_redis自己调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#爬虫可以暂停/开始, 从爬过的位置接着爬取
SCHEDULER_PERSIST = True
#不设置的话,默认使用的是SpiderPriorityQueue
#优先级队列
SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#普通队列
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#栈
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
# scrapy默认配置
'Sina.pipelines.ExamplePipeline': 300,
'Sina.pipelines.SinaPipeline': 301,
# 把数据默认添加到redis数据库中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 日志基本
LOG_LEVEL = 'DEBUG'
#配置redis数据库信息
#redis数据库主机---
REDIS_HOST = "127.0.0.1"
#redis端口
REDIS_PORT = 6379
#下载延迟1秒
# DOWNLOAD_DELAY = 15.start.py
from scrapy import cmdline
cmdline.execute("scrapy runspider sina_info.py".split())6.运行start.py,的效果图,等待指令。。。。。。
7.Redis Desktop Manager输入以下指令
此时开始爬数据的效果图:
8.数据保存到mongo数据库
import json, redis, pymongo
def main():
# 指定Redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定MongoDB数据库信息
mongocli = pymongo.MongoClient(host='localhost', port=27017)
# 创建数据库名
db = mongocli['sina']
# 创建表名
sheet = db['sina_items']
offset = 0
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["sinainfospider_redis:items"])
item = json.loads(data.decode("utf-8"))
sheet.insert(item)
offset += 1
print(offset)
try:
print("Processing: %s " % item)
except KeyError:
print("Error procesing: %s" % item)
if __name__ == '__main__':
main()
9.存到mysql数据库
import redis, json, time
from pymysql import connect
# redis数据库链接
redis_client = redis.StrictRedis(host="127.0.0.1", port=6379, db=0)
# mysql数据库链接
# mysql_client = connect(host="127.0.0.1", user="root", password="mysql", database="sina", port=3306, charset="uft8")
mysql_client = connect(host="127.0.0.1", user="root", password="mysql",
database="sina", port=3306, charset='utf8')
cursor = mysql_client.cursor()
i = 1
while True:
print(i)
time.sleep(1)
source, data = redis_client.blpop(["sinainfospider_redis:items"])
item = json.loads(data.decode())
print("source===========", source)
print("item===========", item)
sql = "insert into sina_items(parent_url,parent_title,sub_title,sub_url,sub_file_name,son_url,head,content,crawled,spider) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
params = [item["parent_url"], item["parent_title"], item["sub_title"], item["sub_url"], item["sub_file_name"],
item["son_url"], item["head"], item["content"], item["crawled"], item["spider"], ]
cursor.execute(sql, params)
mysql_client.commit()
i += 1

相关文章推荐
- python,scrapy爬虫sql之爬取数据存储到mysql的piplelines.py配置
- redis和mongo数据备份以及恢复
- Redis简介以及数据类型存储
- Redis简单介绍以及数据类型存储
- Redis简介以及数据类型存储
- Scrapy爬数据并存储到mysql中
- 使用Python3 xlrd pymysql 实现读取Excel数据读取以及mysql存储
- Scrapy爬数据并存储到mysql中
- 初学Redis数据库之基本数据存储以及获取
- mongo 数据导出到mysql 以及常用查询
- Mysql数据备份以及异地存储
- php表单动态数量的数据的提交以及mysql存储
- scrapy 数据存储mysql
- scrapy将数据存储到mysql中
- redis,mysql,memcache的区别与比较,redis两种数据存储持久化方式
- MySQL大数据的优化以及分解存储 推荐
- Mysql数据备份以及异地存储
- SpringMVC4+thymeleaf3的一个简单实例(篇五:页面和MySql的数据交互-展示以及存储)
- MySQL大数据的优化以及分解存储
- MySQL 存储过程和函数以及数据恢复和备份