Windows10下使用Caffe训练神经网络步骤一
一、生成Caffe数据库
1、准备数据
参考链接中的作者提供了一些图片,共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。编号分别以3,4,5,6,7开头,各为一类。其中每类选出20张用作测试,其余80张用作训练。因此最终训练图片400张,测试图片100张,共5类。我在caffe根目录下的examples文件夹里新建了test_A文件夹,并将图片集放入其中。即,训练图片目录:examples/test_A/train,测试图片目录: examples/test_A/val 备注:总的图片500张,序号300-799;val文件夹下面试300-319,400-419,500-519,600-619,700-719共计100张;其余在train文件夹下
2、生成图片文件列表清单
在生成数据库之前,需要生成图片文件列表清单,一般为.txt文件。我创建.py脚本文件来执行这一步,具体代码create_txt.py如下(代码只是随便写的,可以优化):就是在上述目录下面新建train.txt和val.txt文件上生成标签的代码:
# -*- coding: UTF-8 -*-
# Date:2018.07.05
import os
import re
path_train = train文件夹绝对目录
path_val = val文件夹绝对目录
if not os.path.exists(path_train):
print("path_train not exist!!!")
os._exit()
else:
print("path_train exist!!!")
if not os.path.exists(path_val):
print("path_val not exist!!!")
os._exit()
else:
print("path_val exist!!!")
file_train = open(train.txt文件绝对目录,'wt')
file_val = open(val.txt文件绝对目录,'wt')
file_train.truncate()#截断文件
file_val.truncate()
pa = r".+(?=\.)"
pattern = re.compile(pa)
print "now,creating train.txt..."
for filename in os.listdir(path_train):
# print filename
# abspath = os.path.join(path_train,filename);
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0] == '3':
train_lable = '0'
elif str_label[0] == '4':
train_lable = '1'
elif str_label[0] == '5':
train_lable = '2'
elif str_label[0] == '6':
train_lable = '3'
elif str_label[0] == '7':
train_lable = '4'
else:
print "error data!!!"
os._exit()
# print abspath,train_lable.group()
file_train.write(filename + ' ' + train_lable + '\n')
print "train.txt created!!!"
print "-----------------------------------"
print "now,creating val.txt..."
for filename in os.listdir(path_val):
# print filename
# abspath = os.path.join(path_val,filename);
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0] == '3':
val_lable = '0'
elif str_label[0] == '4':
val_lable = '1'
elif str_label[0] == '5':
val_lable = '2'
elif str_label[0] == '6':
val_lable = '3'
elif str_label[0] == '7':
val_lable = '4'
else:
print "error data!!!"
os._exit()
# print abspath,train_lable.group()
file_val.write(filename + ' ' + val_lable + '\n')
print "val.txt created!!!"
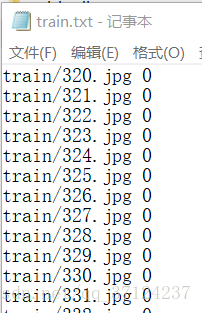
print "function over!!!"[p]点开train.txt和val.txt就会发现生成好了
3、生成lmdb数据库
在cmd中进入caffe根目录,分别执行以下 指令:[/p]win+R 操作打开运行面板,输入cmd,回车
在cmd下打开caffe根目录,作者的是caffe-master
输入:
Build\x64\Release\convert_imageset.exe --shuffle --resize_height=256 --resize_width=256 examples\test_A\ examples\test_A\val.txt examples\test_A\val_lmdb
然后回车就会发现上述目录下多了val_lmdb文件夹
再输入:
Build\x64\Release\convert_imageset.exe --shuffle --resize_height=256 --resize_width=256 examples\test_A\ examples\test_A\train.txt examples\test_A\train_lmdb
然后回车就会发现上述目录下多了train_lmdb文件夹
4、生成均值文件
图片减去均值再训练,会提高训练速度和精度。因此,一般都会有这个操作。caffe程序提供了一个计算均值的文件compute_image_mean.cpp,我们直接使用就可以。
输入Build\x64\Release\compute_image_mean.exe examples\test_A\train_lmdb examples\test_A\mean.binaryproto
回车就会发现test_A文件夹下面就有了mean.binaryproto文件
阅读更多

- Windows10下使用Caffe训练神经网络步骤二
- 【神经网络与深度学习】Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
- 【深度学习】笔记6:使用caffe中的CIFAR10网络模型和自己的图片数据训练自己的模型(步骤详解)
- Windows10下使用Caffe训练神经网络(含数据库的生成方法)
- 深度学习之五:使用GPU加速神经网络的训练
- 【神经网络与深度学习】基于Windows+Caffe的Minst和CIFAR—10训练过程说明
- 使用caffe-future完成FCN网络的训练
- TensotFlow 应用实例:08-使用tensorboard可视化神经网络结构和训练结果
- 新版Matlab中神经网络训练函数Newff的使用方法
- 使用反向传播算法训练多层神经网络(图示)
- 基于MNIST数据集使用TensorFlow训练一个包含一个隐含层的全连接神经网络
- 使用mvnc运行caffe神经网络的坑
- Caffe学习——使用自己的数据(非图像)训练网络
- 【神经网络与深度学习】在Windows8.1上用VS2013编译Caffe并训练和分类自己的图片
- 【神经网络与深度学习】Caffe源码中各种依赖库的作用及简单使用
- 使用Caffe训练适合自己样本集的AlexNet网络模型,并对其进行分类
- 使用反向传播算法(back propagation)训练多层神经网络
- 完全云端运行:使用谷歌CoLaboratory训练神经网络
- 关于python 在神经网络训练图像数据预处理时使用的transpose
- 利用caffe训练网络的步骤