HTTP请求头部+响应码
一、当在浏览器输入一个网址后,实际会发生什么?
回答之前,先摘一段《淘宝技术这十年》中的“你刚才在淘宝上买了一件东西”里的一段话,对我理解这个问题有启发。
你发现快过年了,于是想给你的女朋友买一件毛衣,你打开了 www.taobao.com,这时你的浏览器首先查询DNS服务器,将
www.taobao.com转换成IP地址。但是,你首先会发现,在不同的地区或者不同的网络下,转换后的IP地址很可能是不一样的,这首先涉及负载均衡的第一步,通过DNS解析域名时,将你的访问分配的不同的入口,同时尽可能的保证你所访问的入口时所有入口中较快的一个。
你通过这个入口成功的访问了www.taobao.com实际的入口IP地址,……经过一系列的复杂的逻辑运算和数据处理,用于给你看的淘宝首页HTML内容便生成了,浏览器下一步会加载页面中用到的CSS /JS/图片等样式、脚本和资源文件。
那么,输入网址后,实际发生了什么呢?过程如下:
1、输入网址。
2、浏览器查找域名的IP地址。
[code] 导航的第一步是通过访问的域名找出其IP地址。DNS查找过程如下:
- 浏览器缓存 – 浏览器会缓存DNS记录一段时间。 有趣的是,操作系统没有告诉浏览器储存DNS记录的时间,这样不同浏览器会储存个自固定的一个时间(2分钟到30分钟不等)。
- 系统缓存 – 如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
- 路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
- ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
3. 浏览器给web服务器发送一个HTTP请求
4. 网站服务的永久重定向响应
服务器给浏览器响应一个301永久重定向响应,为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?其中一个原因跟搜索引擎排名有关。如果一个页面有两个地址,就像http://www.igoro.com/
和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 浏览器跟踪重定向地址
[code] 现在,浏览器知道了要访问的正确地址,所以它会发送另一个获取请求。请求头部一般包括: Accept Accept-language Accept-Encoding Connection User-Agent Cookie Host
6. 服务器“处理”请求
[code]服务器接收到获取请求,然后处理并返回一个响应。
7. 服务器发回一个HTML响应
8. 浏览器开始显示HTML
9. 浏览器发送请求,以获取嵌入在HTML中的对象
在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。这些文件就包括CSS/JS/图片等资源,这些资源的地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等…
10. 浏览器发送异步(AJAX)请求
二、三次握手的过程
这个问题,最初接触,是在本科学习计算机网络的时候,当时学什么TCP/IP,各种层,但是,学的不如忘得快啊,很多东西,还是需要常常的使用和回顾才行。
如下图,建立连接要三次握手,释放连接要四次握手,下面具体介绍一下:
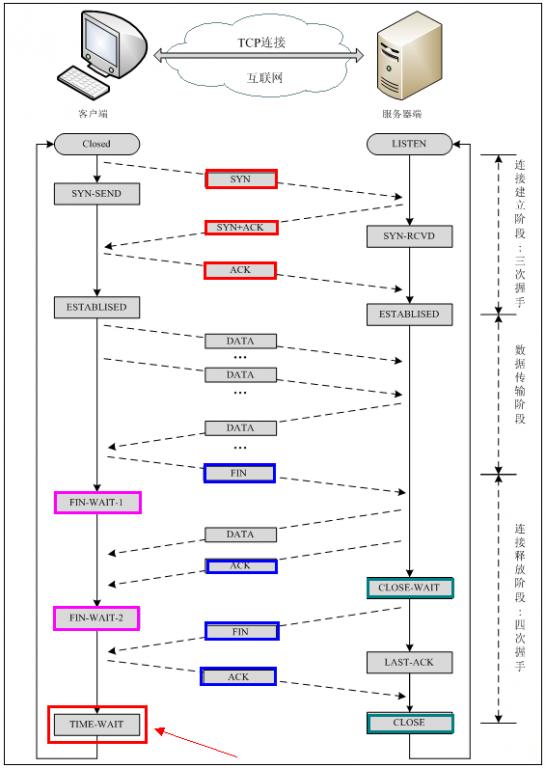
需要说明的信息:
ACK : TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
SYN(SYNchronization) : 在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN (finis):完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
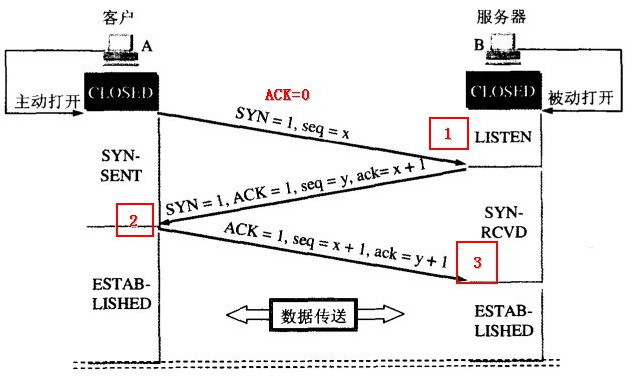
三次握手,两次确认。
首先由Client发出请求连接,即 SYN=1 ACK=0, TCP规定SYN=1时不能携带数据,但要消耗一个序号,因此声明自己的序号是 seq=x
然后 Server 进行回复确认,即 SYN=1 ACK=1 seq=y, ack=x+1,
再然后 Client 再进行一次确认,但不用SYN 了,这时即为 ACK=1, seq=x+1, ack=y+1.然后连接建立。为什么要进行三次握手,两次确认呢?我用我自己的理解来说。
考虑一种情况,A发送了一个连接请求,但是这个请求因为某种原因而滞留了,一直延误到连接释放后才到达B,而B收到连接请求后,就会发送确认信息,同意建立连接,如果不存在第三次握手的话,这个连接就成功了。而这是一个失效的连接请求,A不会向B发送数据,这样B的资源就会白白浪费了,因为B一直在等待A发送数据。
连接释放:四次握手
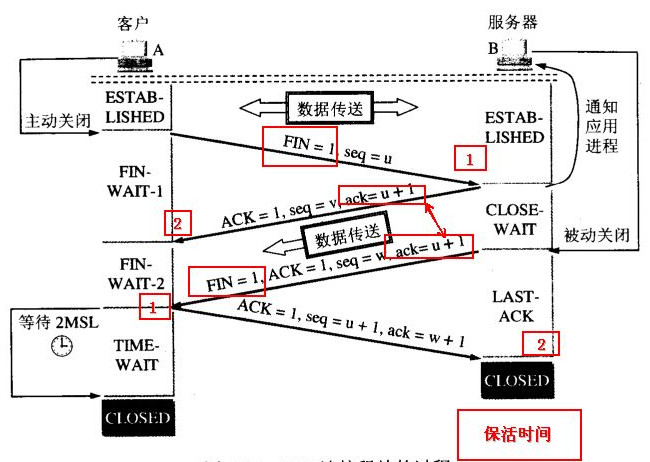
当客户A 没有东西要发送时就要释放 A 这边的连接,A会发送一个报文(没有数据),其中 FIN 设置为1, 服务器B收到后会给应用程序一个信,这时A那边的连接已经关闭,即A不再发送信息(但仍可接收信息)。 A收到B的确认后进入等待状态,等待B请求释放连接, B数据发送完成后就向A请求连接释放,也是用FIN=1 表示, 并且用 ack = u+1(如图), A收到后回复一个确认信息,并进入 TIME_WAIT 状态, 等待 2MSL 时间。
当客户端A没有数据要发送时,就要释放A的连接,A会发送一个FIN报文,然后主动关闭连接(不再发送信息但仍然可以接收信息)。服务器B收到FIN报文后,会给应用程序通信,并向A发送一个确认报文。A收到B的确认后进入等待状态,等待B请求释放连接。 B的数据发送完后,会向A发送FIN报文,请求释放连接。A收到后会回复一个确认信息,然后进入TIME_WAIT状态。
以上就是7次握手。
三、HTTP头部信息
说实话,这个部分是已经工作了的师姐让我面试前一定要准备一下的问题,说面试官会问道,所以就系统的学习了一下,现在总结如下:
[code] 通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。
登录到CSDN后,随便点了一个资源,看看HTTP头部信息:
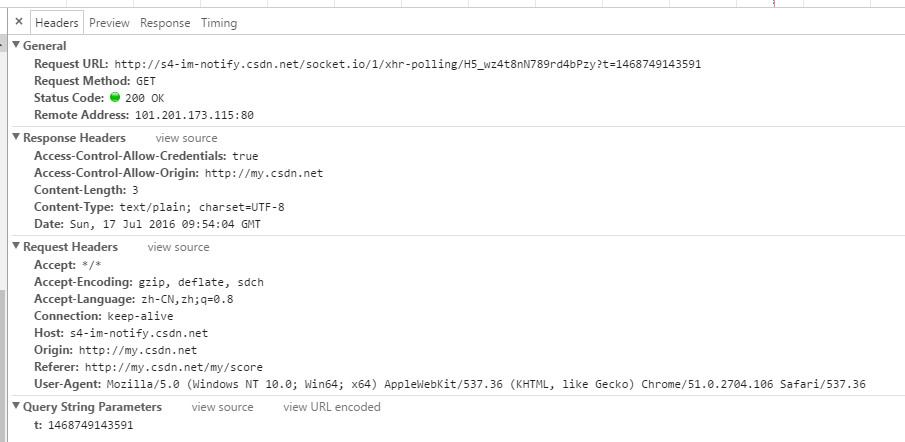
从上图可以看到,头部信息包括三部分:
1、通用头部
2、请求头部
3、响应头部
4、查询字符串参数
分别介绍:
1、通用头部
通用头域包含请求和响应消息都支持的头域。
[code]Request URL:请求的URL地址 Request Method: 请求方法,get/post/put/…… Status Code:状态码,200 为请求成功 Remote Address:路由地址
2、请求头部
[code] 1) Accept: 告诉WEB服务器自己接受什么介质类型,*/* 表示任何类型,type/* 表示该类型下的所有子类型; 2)Accept-Charset: 浏览器申明自己接收的字符集 Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法 (gzip,deflate) 3)Accept-Language: 浏览器申明自己接收的语言。语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等。 4)Authorization: 当客户端接收到来自WEB服务器的 WWW-Authenticate 响应时,该头部来回应自己的身份验证信息给WEB服务器。 5)Connection:表示是否需要持久连接。close(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,断开连接, 不要等待本次连接的后续请求了)。keep-alive(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待本次连接的后续请求)。 6)Referer:发送请求页面URL。浏览器向 WEB 服务器表明自己是从哪个 网页/URL 获得/点击 当前请求中的网址/URL。 7)User-Agent: 浏览器表明自己的身份(是哪种浏览器)。 8)Host: 发送请求页面所在域。 9)Cache-Control:浏览器应遵循的缓存机制。 no-cache(不要缓存的实体,要求现在从WEB服务器去取) max-age:(只接受 Age 值小于 max-age 值,并且没有过期的对象) max-stale:(可以接受过去的对象,但是过期时间必须小于 max-stale 值) min-fresh:(接受其新鲜生命期大于其当前 Age 跟 min-fresh 值之和的缓存对象) 10)Pramga:主要使用 Pramga: no-cache,相当于 Cache-Control: no-cache。 11)Range:浏览器(比如 Flashget 多线程下载时)告诉 WEB 服务器自己想取对象的哪部分。 12)Form:一种请求头标,给定控制用户代理的人工用户的电子邮件地址。 13)Cookie:这是最重要的请求头信息之一
以上仅列出了我见过的请求头部,欢迎指正和补充!
3、响应头部
[code] 1)Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间了。 2)Accept-Ranges:WEB服务器表明自己是否接受获取其某个实体的一部分(比如文件的一部分)的请求。bytes:表示接受,none:表示不接受。 3) Cache-Control:服务器应遵循的缓存机制。 public(可以用 Cached 内容回应任何用户) private(只能用缓存内容回应先前请求该内容的那个用户) no-cache(可以缓存,但是只有在跟WEB服务器验证了其有效后,才能返回给客户端) max-age:(本响应包含的对象的过期时间) ALL: no-store(不允许缓存) 4) Connection: 是否需要持久连接 close(连接已经关闭)。 keepalive(连接保持着,在等待本次连接的后续请求)。 Keep-Alive:如果浏览器请求保持连接,则该头部表明希望 WEB 服务器保持连接多长时间(秒)。例如:Keep-Alive:300 5)Content-Encoding:WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。 例如:Content-Encoding:gzip 6)Content-Language:WEB 服务器告诉浏览器自己响应的对象的语言。 7)Content-Length:WEB 服务器告诉浏览器自己响应的对象的长度。例如:Content-Length: 26012 8)Content-Range:WEB 服务器表明该响应包含的部分对象为整个对象的哪个部分。例如:Content-Range: bytes 21010-47021/47022 9)Content-Type:WEB 服务器告诉浏览器自己响应的对象的类型。例如:Content-Type:application/xml 10)Expired:WEB服务器表明该实体将在什么时候过期,对于过期了的对象,只有在跟WEB服务器验证了其有效性后,才能用来响应客户请求。 11) Last-Modified:WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动态页面的最后产生时间等等。 12) Location:WEB 服务器告诉浏览器,试图访问的对象已经被移到别的位置了,到该头部指定的位置去取。 13)Proxy-Authenticate: 代理服务器响应浏览器,要求其提供代理身份验证信息。 14)Server: WEB 服务器表明自己是什么软件及版本等信息。 15)Refresh:表示浏览器应该在多少时间之后刷新文档,以秒计。
http请求中的8种请求方法
1、opions 返回服务器针对特定资源所支持的HTML请求方法 或web服务器发送*测试服务器功能(允许客户端查看服务器性能)
2、Get 向特定资源发出请求(请求指定页面信息,并返回实体主体)
3、Post 向指定资源提交数据进行处理请求(提交表单、上传文件),又可能导致新的资源的建立或原有资源的修改
4、Put 向指定资源位置上上传其最新内容(从客户端向服务器传送的数据取代指定文档的内容)
5、Head 与服务器索与get请求一致的相应,响应体不会返回,获取包含在小消息头中的原信息(与get请求类似,返回的响应中没有具体内容,用于获取报头)
6、Delete 请求服务器删除request-URL所标示的资源*(请求服务器删除页面)
7、Trace 回显服务器收到的请求,用于测试和诊断
8、Connect HTTP/1.1协议中能够将连接改为管道方式的代理服务器
四、HTTP响应码
HTTP响应码响应码由三位十进制数字组成,它们出现在由HTTP服务器发送的响应的第一行。
响应码分五种类型,由它们的第一位数字表示:
1xx:信息,请求收到,继续处理
2xx:成功,行为被成功地接受、理解和采纳
3xx:重定向,为了完成请求,必须进一步执行的动作
4xx:客户端错误,请求包含语法错误或者请求无法实现
5xx:服务器错误,服务器不能实现一种明显无效的请求
具体含义如下:
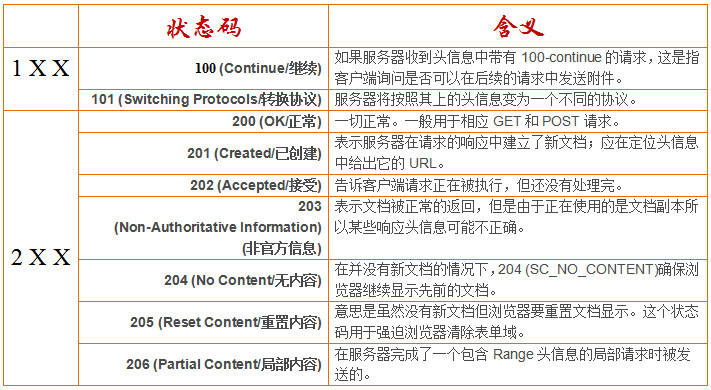


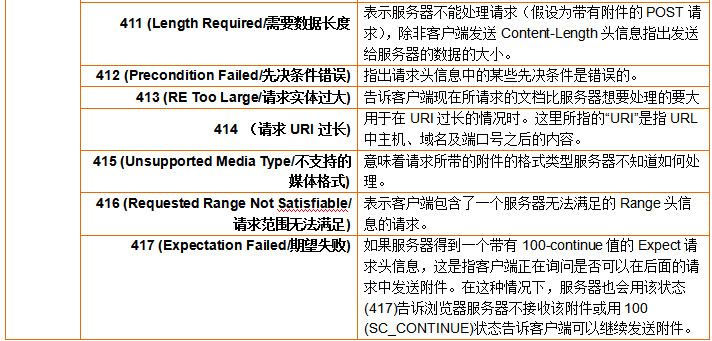
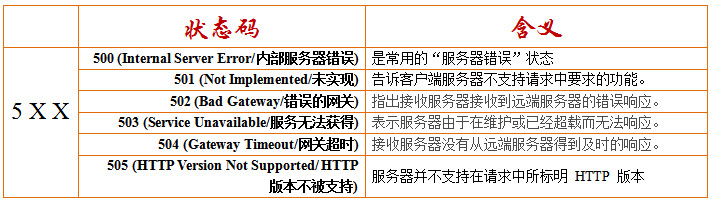

- nginx处理post请求(http响应头部的收发)
- 修改httpcore.jar的源码,查看Httpclient的http协议请求头部和响应头部
- HTTP请求头部+响应码
- HTTP请求方法及响应码详解(http get post head)
- 初识HTTP协议--请求与响应报文
- HTTP响应头信息和请求头信息详解
- angular学习笔记(二十五)-$http(3)-转换请求和响应格式
- Android Http请求头与响应头的学习
- 第一部分:HTTP协议之请求和响应
- Http消息头中常用的请求头和响应头
- HTTP请求头部Content-Type字段
- HTTP请求报文和HTTP响应报文
- HTTP请求响应机制与响应状态码
- android,retrofit,okhttp,日志拦截器,使用拦截器Interceptor统一打印请求与响应的json
- HTTP协议:pipeline,一个包里有多个请求,一个包里有多个响应
- Android Http请求头与响应头的学习
- HTTP 请求和响应格式
- HTTP请求以及HTTP响应
- http常见的请求头和响应头
- HTTP响应头和请求头信息对照表