Spark HA集群模式的搭建和运行原理
HA出现的原因:
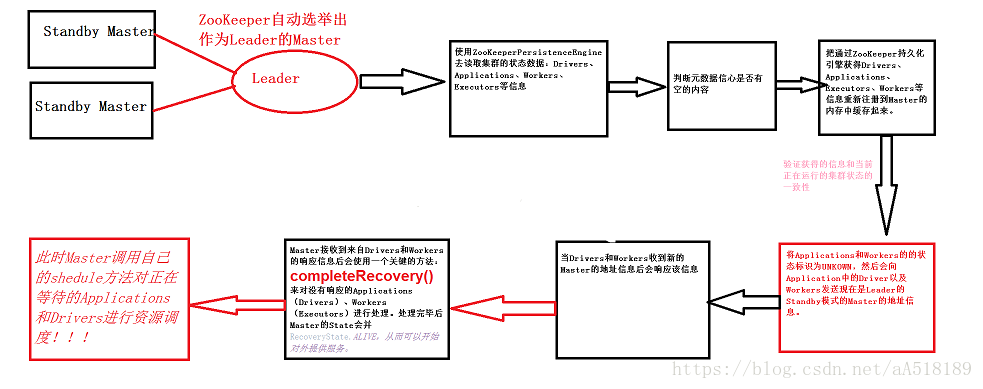
Master-Slave模型很容易出现单节点故障的问题。所以为了应用这个问题,解决办法是通过Zookeeper来解决,在实际开发的时候一般都是三台,一个active,两个standby,当一个active挂掉后,Zookeeper会根据自己的选举机制,从standby的Master选举出来一个作为leader。这个leader从standby模式变成active模式的话,做的最重要的事:是从Zookeeper中获取整个集群的状态信息,恢复整个集群的Worker,Driver,Application,这样才能接管整个集群的工作,而只有它成功完成之后,leader的Master才可以恢复成active的Master,才可以对外继续提供服务(作业的提交和资源的申请请求。),当active的master挂掉以后,standby的master变成active的master之前我们是不可以向集群提交新的程序。但是在Zookeeper切换期间,在这个时间集群的运行时正常的,例如,一个程序依然可以正常运行。因为程序在运行之前已经向Master申请资源了,Driver与我们所有worker分配的executors进行通信,这个过程一般不需要master参与,除非executor有故障。Master是粗粒度分配,粗粒度的好处当Master出故障以后,可以让Worker和executor交互完成计算。
HA模式下的Spark结构图
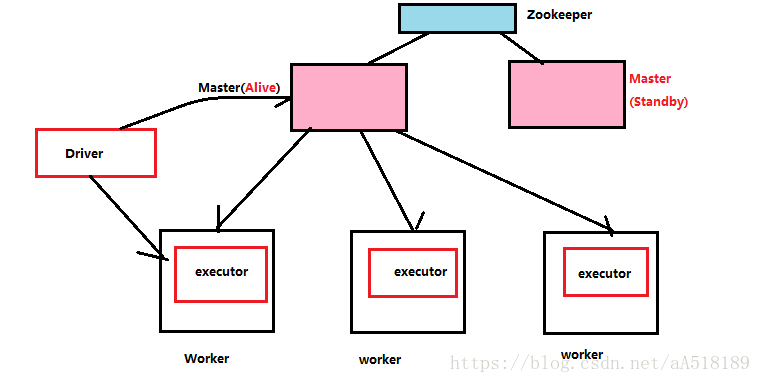
HA模式的搭建
首先要搭建好zookeeper集群,这里不再讲了,在我的这篇文章中有具体的讲解https://blog.csdn.net/aa518189/article/details/80144319点击打开链接
注意一点HA模式针对的是spark的Standalone模式
第一步 进入Spark的conf文件夹 修改spark-env.sh 文件:
在spark-env.sh中配置Zookeeper信息,注意此时的Master_IP是master就不需要了,因为zookeeper中配置了
添加:
export SPARK_DAEMON_JAVA_OPTS="Dspark.deploy.recoveryMode=ZOOKEEPERDspark.deploy.zookeeper.url=wangzhihua1:2181,wangzhihua2:2181,wangzhihua3:2181 -Dspark.deploy.zookeeper.dir=/spark"
其中 -Dspark.deploy.zookeeper.url=hdp-01:2181,hdp-02:2181,hdp-03:2181是你的zookeeper集群所在的机器

配置文件分发给其他机器
[root@hdp-01 conf]# for i in 2 3 4;do scp spark-env.sh hdp-0$i:$PWD ;done
root@hdp-01 conf]# start-all.sh
注意 在sbin或bin目录下要加上 ./
再在hdp-02上启动一个master:
[root@hdp-02 bin]# start-master.sh
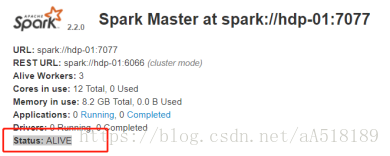

1.1. spark任务如何连接到HA集群:
[root@hdp-02 bin]# spark-shell --master spark://hdp-01:7077,hdp-02:7077
验证HA:
杀死hdp-01上的master
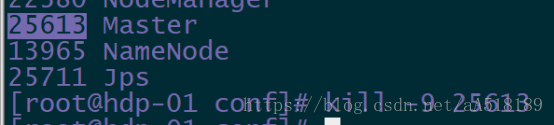
· Status: RECOVERING
·

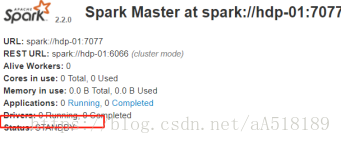
目前hdp-02 已经可以切换为alive状态。
当再次启动hdp-01上的master,只能是standby状态
zoopkeeper在HA中的作用?
假设Active Master故障后,是不是另外两台StandBy模式的机器要重新选出一个Leader来作为新的Active Master?如果要切换成Active 级别的Master是不是要恢复状态?到哪里去恢复集群的状态呢?
集群的元数据都是在Zookeeper中保存的,所以需要到Zookeeper中恢复集群状态。
Zookeeper中包含的有哪些内容?
=>所有的Worker、Driver、Application。
Driver代表了正在运行的程序。Application是应用程序本身。这些信息都会交给Zookeeper。
当Active Master故障,Zookeeper会利用选举机制,重新选举出一个Leader,这个Leader从StandBy模式切换为Active模式的话,做的最重要的事就是从zookeeper中获取集群的状态信息恢复集群的Worker、Driver、Application。这样才能接管集群的工作。只有它恢复完成后,此时被选为Leader的Master才会从StandBy到Recovering再到Active,只有到了Active级别才能继续提供服务,接受新的作业请求。
就是说在Active Master故障后到新的Master恢复完成前不能向集群提交新的程序。此时集群运行正常。就是说Master切换的过程不会影响程序运行。
Master切换时会不会影响application?
不会,因为程序运行前已经向master申请过资源了。申请过后就是Driver与Executors之间的通信,这个过程一般不需要Master参与,除非executor有故障。
这就是粗粒度,好处是一次性分配资源好后,不需要再关心资源的分配,而在作业运行过程中可以让driver和executors交互,完成作业或程序运行。
弊端:假设有一百万个任务,如果只有一个任务没有完成,那么其他所有资源都会闲置,其他任务会等待,造成浪费。
细粒度是需要资源时再分配资源。使用完资源后立即释放。
细粒度的弊端:任务启动慢,而且没法复用,通信麻烦。
正常情况下都是用粗粒度。

- Spark自带的集群模式(Standalone),Spark/Spark-ha集群搭建
- HDFS集群搭建,高可用双机热备模式(HA)自动切换,hdfs+zookeeper+journalnode,步骤分步原理详解(适合初学者)
- Spark1.6.1集群环境搭建——Standalone模式HA
- spark0.9.1集群模式运行graphx测试程序(LiveJournalPageRank,新增Connected Components)
- spark集群搭建与集群上运行wordcount程序
- 第31课:集群运行模式下的Spark Streaming调试和难点解决实战经验分享
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
- 每天一点进步:Spark运行模式和原理
- Spark学习笔记(30)集群运行模式下的Spark Streaming调试
- Spark集群基于Zookeeper的HA搭建部署
- Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的
- Spark HA 集群搭建【1、基于文件系统的手动HA 2、基于zk的自动HA】
- 第30课:集群运行模式下的Spark Streaming日志和Web监控台实战演示彻底解密
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount示例(1)
- 3 视频里weekend05、06、07的可靠性 + HA原理、分析、机制 + weekend01、02、03、04、05、06、07的分布式集群搭建
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount(2)
- 在spark开发环境中使用Standalone模式调试集群运行
- Local模式下开发第一个Spark程序并运行于集群环境
- Hadoop HA 模式下运行spark 程序
- Spark on YARN集群模式作业运行全过程分析