(一)solr 7.31版本window系统全程安装搭建,涵盖项目用到的大部分配置,常用查询,solr多条件查询、排序,配置数据库,定时同步,全量与增量更新,使用solrJ在java程序进行增删改查
前言:由于项目最近在做淘宝客商品信息查询这一块,做搜索引擎,离不开全文搜索服务器,我这里选择了solr。solr的好处可以自行百科,这里主要是讲解技术。这篇文章主要讲解window的安装和使用。若大家感兴趣或者项目用到,希望你能跟着我的步骤进行下去,如果遇到问题,可以后续看下我在最底下的问题讲解,或者留言。
注意:7.3.1版本是需要jdk1.8以上的,我这边的数据库是Oracle数据库,建议用Oracle数据库。
朋友:如果你在配置过程中,配置不了,或者感觉漏掉了哪些内容,可以添加:

我把我配置的文件,分享在群里,这样大伙也有个参考!
One:搭建solr服务器前,一定要看下我要讲解的步骤(考试重点,圈起来 ^_^):
1–下载运行
2–创建核心core
3–添加中文分词器
4–配置managed-schema 设置其中文分词器
5–导入3个jar包到web-inf下的lib
6–配置solrconfig.xml,配置内容是数据库文件所在位置
7–同级目录下,创建data-config.xml文件 里面内容主要是数据库账号密码,还有全量、增量更新相关的sql信息
8–配置完后,要记得配置managed-schema中的数据库列和名称的映射关系
9–solrJ在java上的操作了。
一、下载运行solr:
下载地址:http://lucene.apache.org/solr/
直接点击右上角的download,跳到如下页面:

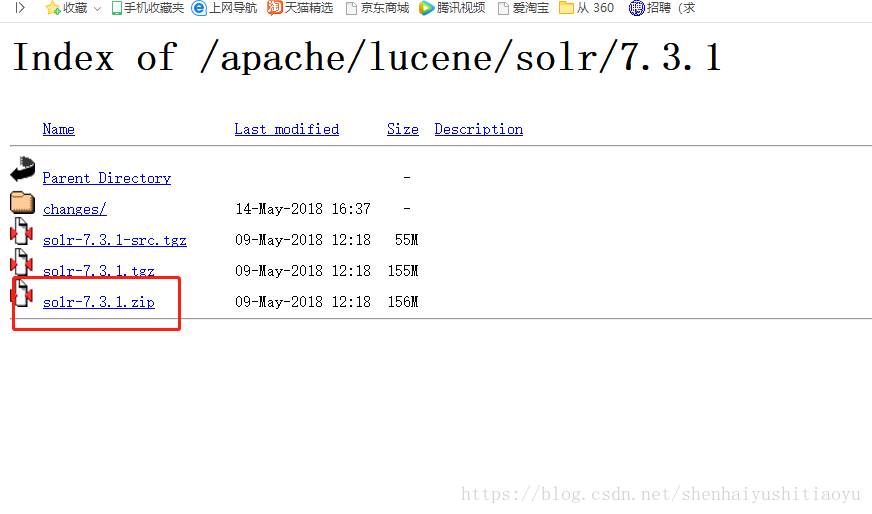
推荐下载最新版的7.3.1.zip版本的。因为本教程就是用7.3.1的。
下载后放到E盘(放在哪个盘都行,推荐跟我放在E盘,这样后续有相关路径就比较好参考了)然后解压,解压后进入solr的bin目录,在空白处shift+鼠标右键,进入dos窗口:
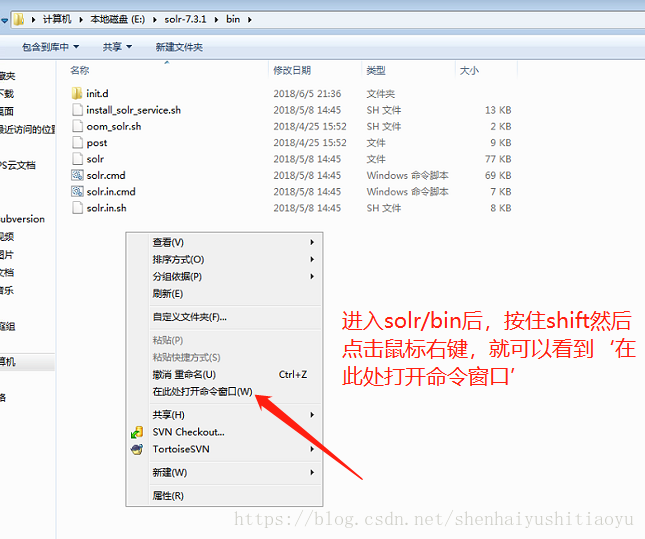
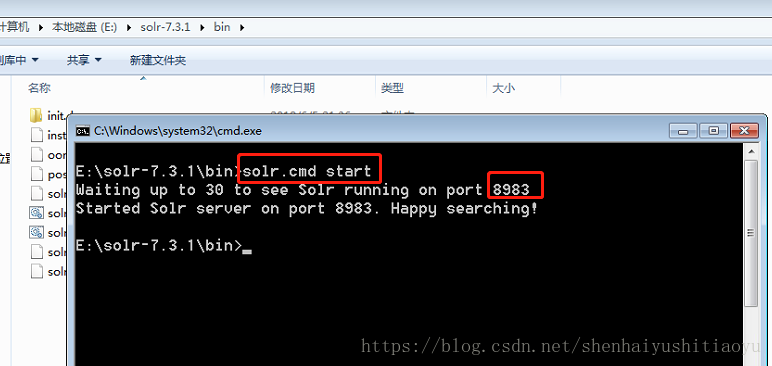
输入solr.cmd start 然后敲回车,就可以启动solr了。默认端口为:8983
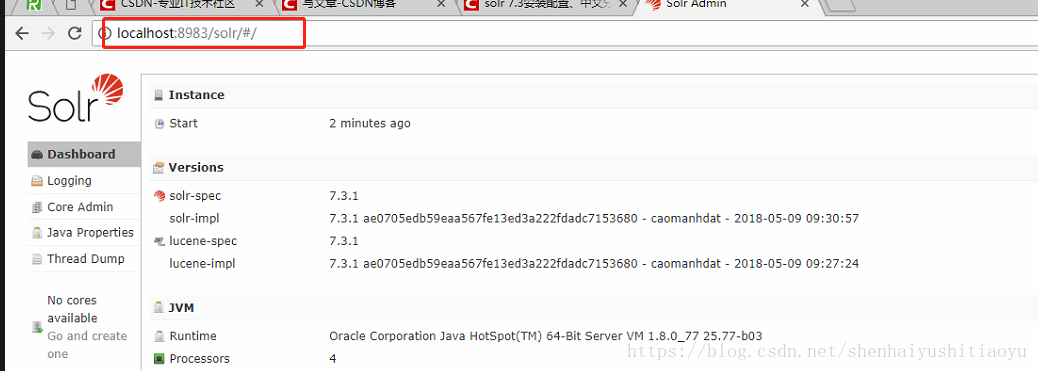
在浏览器输入localhost:8983/solr,就可以看到solr已经启动了
二、创建核心core:所谓的core,其实就是类似于在一个大酒店里,开一个房间,用来堆放东西的情景。也就是说,创建core就是在solr服务器中开辟一个小小的存储空间,用来放数据的。如果还不明白,不必要弄清楚,等你熟悉了回过头想一下就知道了。请继续往下跟我进行操作:
1.在刚刚打开的窗口,输入 solr.cmd create -c myCore
此处注意:myCore是自己自定义的,你也可以叫youCore xxCore 或者就叫Tom都行。我这里用myCore 建议跟我一样做:
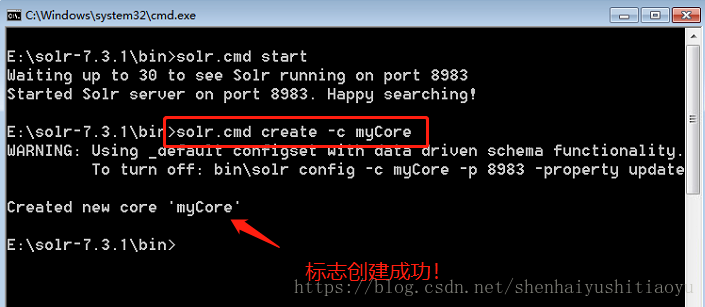
创建好了后,刷新页面,在图中下拉框就可以看到你创建的Core了。如果看不到,在dos窗口输入 solr.cmd -p 8983 restart 重启solr即可
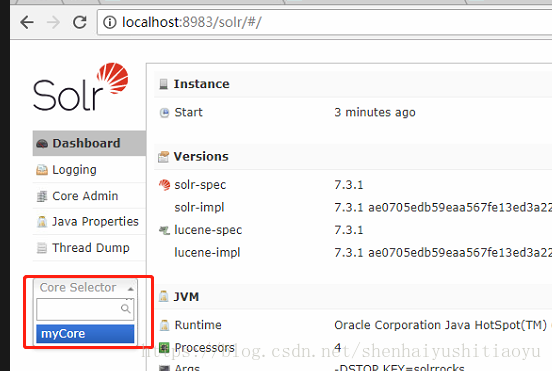
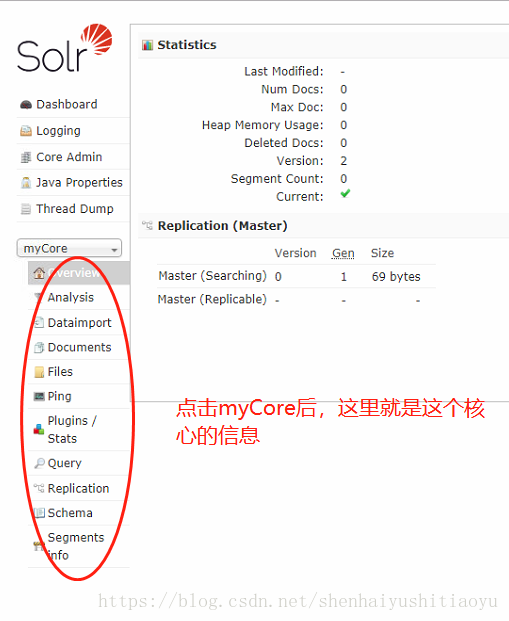
点击myCore 就可以看到如下信息:这些信息包含了分词器,还有数据导入,数据查询等功能。
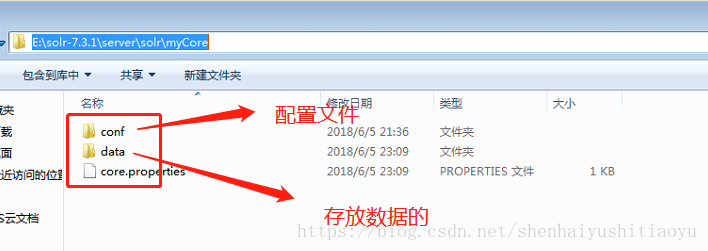
同时,你还可以进入E:\solr-7.3.1\server\solr\myCore 看到你创建的core 该文件夹中有conf文件夹,用来放置该core的配置文件,包括数据库信息,数据查询语句,均可以在这些配置文件中进行操作,后续会讲解,请跟我继续往下:
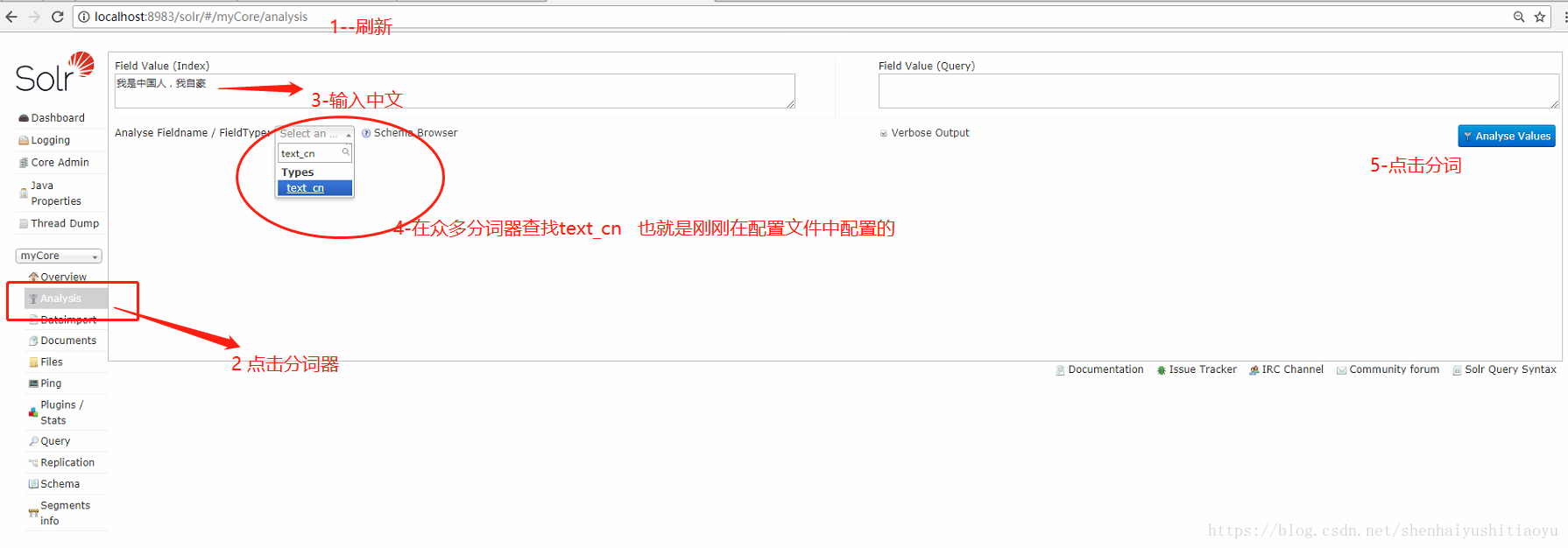
三、前两步启动solr和创建core后,这一步配置中文分词器:
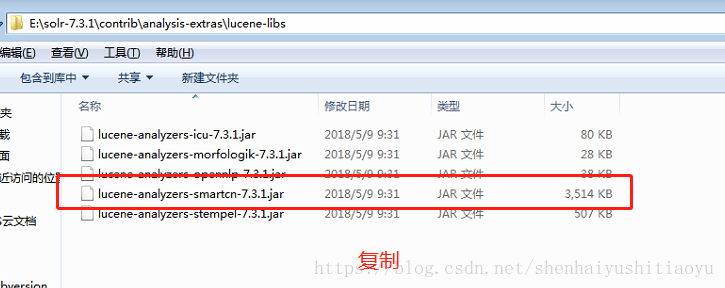
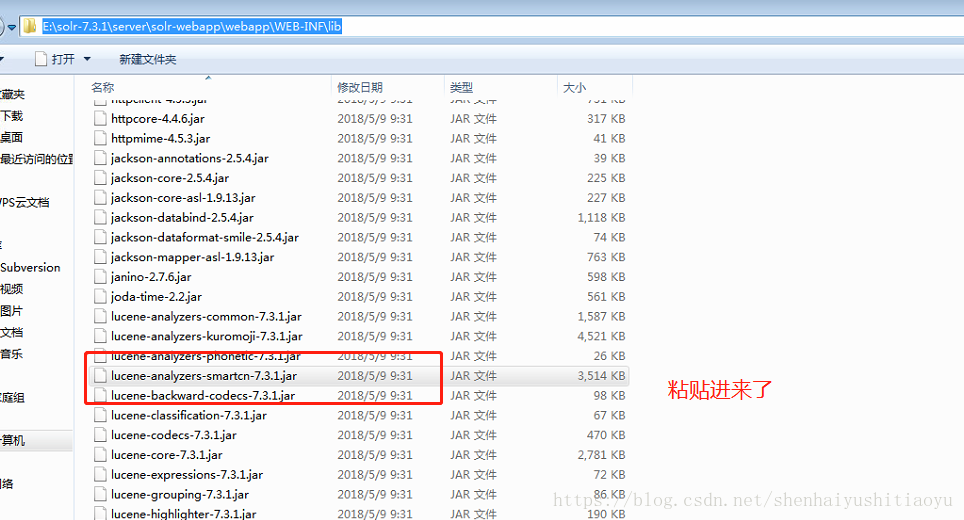
- 添加中文分词插件:solr 7.3.1中自带中文分词插件,将solr-7.3.1\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.3.1.jar 复制到 solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib 目录中
- 配置中文分词,修改 solr-7.3.1\server\solr\myCore**【这个myCore是刚刚创建的core名称】**\conf\managed-schema文件,添加中文分词
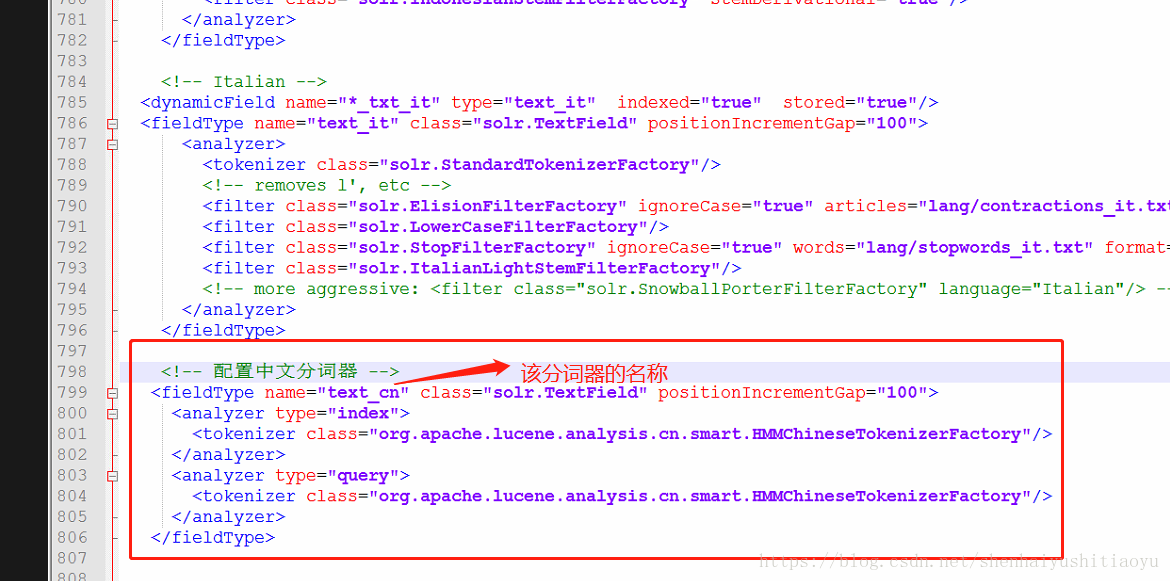
打开这个文件后,搜索 Italian,在Italian下添加我们的中文配置(复制粘贴即可):
<!-- 配置中文分词器--> <fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
dos窗口输入solr.cmd -p 8983 restart 重启solr服务器 如果这条命令报错,直接关闭窗口,重新启动solr即可。
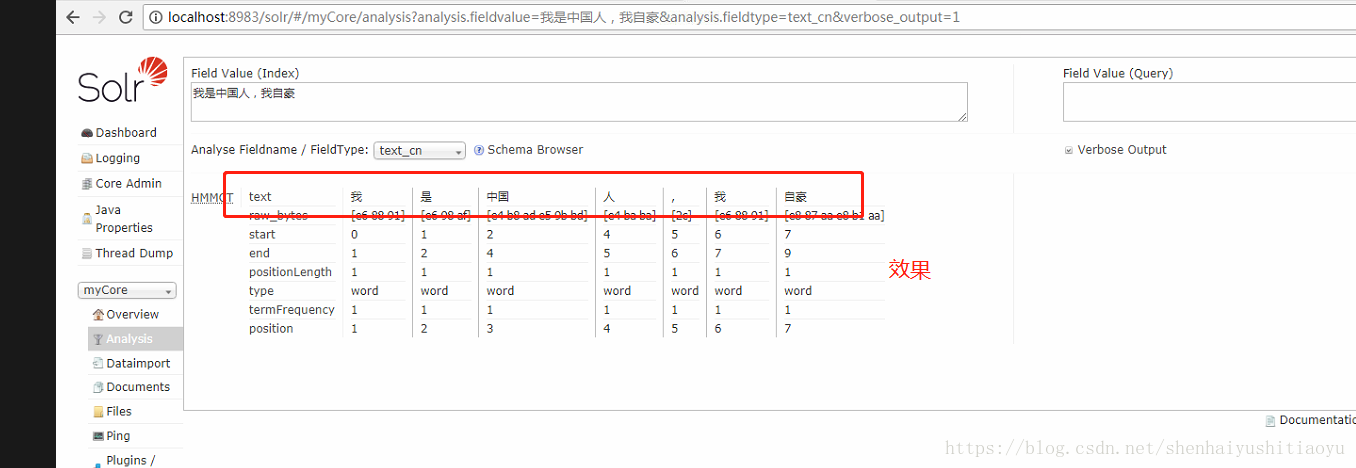
刷新solr地址,测试solr中文分词器是否正确:
4.出现如下分词效果证明配置成功!
四、数据操作。 前面几步 基本配置好solr以及中文分词器了,但solr的主要核心还是数据,所以第四步骤开始,讲解如何通过配置文件的方式,获取数据库的数据,并导入solr。第四点主要内容:a-连接数据库 b-设置数据库列名和solr数据名称的对应关系 c-设置全量和增量更新的SQL语句
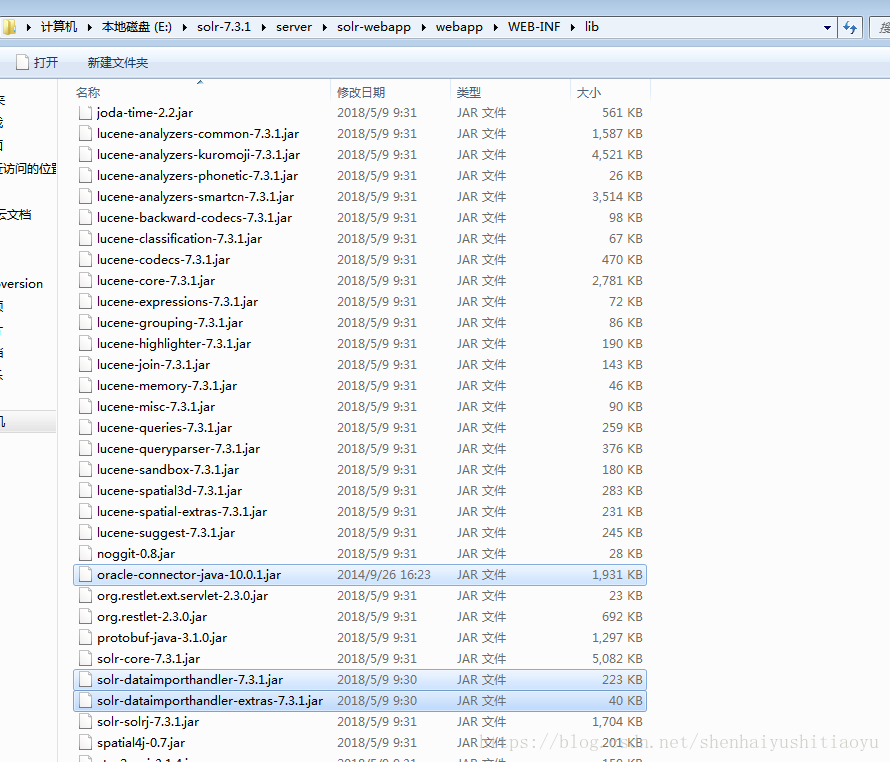
首先:想要通过配置文件连接数据库,就要有数据库驱动,我这里用的是Oracle。相关文件我放在群里,到时候去下载即可。除了数据库驱动,还需要solr自带的两个jar文件,这两个jar文件主要是用来把数据库数据导入solr服务器的,都在该目录下:
E:\solr-7.3.1\dist
名称分别为:
solr-dataimporthandler-7.3.1.jar
solr-dataimporthandler-extras-7.3.1.jar
同时,在群或网上下载 :
一共三个jar包,都复制粘贴到 E:\solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib
其次:
进入E:\solr-7.3.1\server\solr\myCore\conf 找到solrconfig.xml 文件,打开,
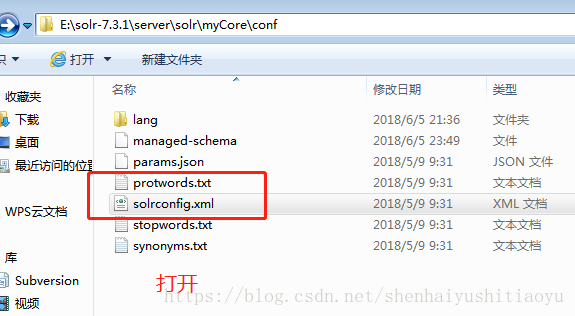
复制以下代码到该文件下:
<!--数据库配置 --> <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
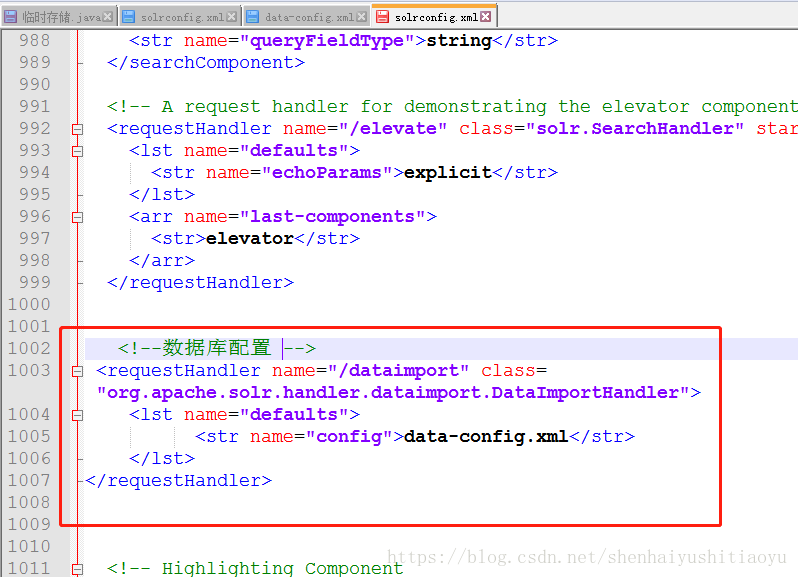
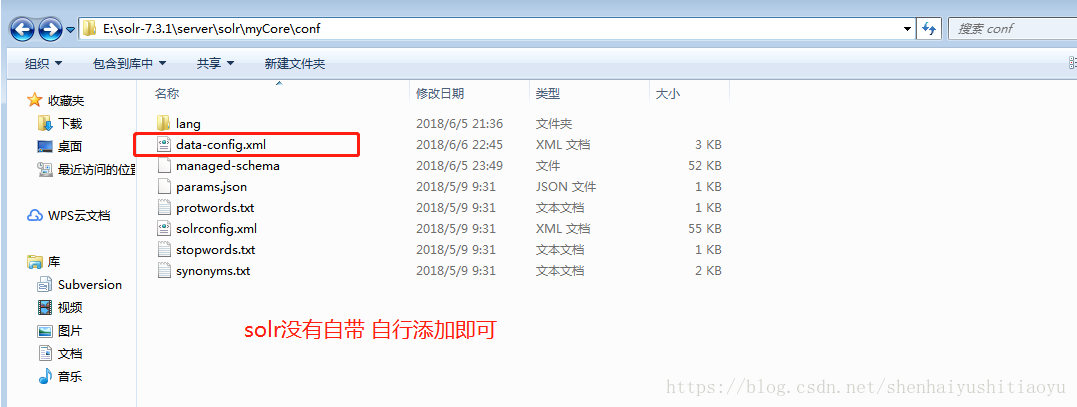
保存后,在同级目录下,创建data-config.xml文件,该文件主要是配置数据库和配置SQL语句的:
该文件内容如下:
<dataConfig>
<!--JdbcDataSource这个名称建议不要变!-->
<dataSource type="JdbcDataSource"
driver="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@//localhost:1521/orcl"
user="root"
password="root"/>
<document>
<!-- 设置全量导入商品库-->
<entity dataSource="JdbcDataSource" name="import170data"
query="SELECT T.ID,T.TITLE,T.PIC,T.ORG_PRICE,T.PRICE,T.IS_TMALL,T.SALES_NUM,T.COMMISSION_JIHUA,T.COMMISSION_QUEQIAO,T.COMMISSION,T.TB_GOODS_ID,T.QUAN_PRICE,T.CREATE_TIME,T.CID FROM T_TBK_GOODS T "
pk="ID" deltaQuery="SELECT T.id FROM T_TBK_GOODS T WHERE T.CREATE_TIME > (SELECT TO_DATE('${dataimporter.import170data.last_index_time}','yyyy/MM/dd HH24:mi:ss') +8/24 next_hour from dual) OR T.UPDATE_TIME > (SELECT TO_DATE('${dataimporter.import170data.last_index_time}','yyyy/MM/dd HH24:mi:ss') +8/24 next_hour from dual)"
deltaImportQuery="SELECT T.ID,T.TITLE,T.PIC,T.ORG_PRICE,T.PRICE,T.IS_TMALL,T.SALES_NUM,T.COMMISSION_JIHUA,T.COMMISSION_QUEQIAO,T.COMMISSION,T.TB_GOODS_ID,T.QUAN_PRICE FROM T_TBK_GOODS T WHERE T.ID='${dih.delta.ID}'"
deletedPkQuery="SELECT ID FROM T_TBK_GOODS WHERE QUAN_TIME < SYSDATE"
>
<field column="ID" name="id"></field>
<field column="TITLE" name="goodsTitle"></field>
<field column="PIC" name="pic"></field>
<field column="ORG_PRICE" name="orgPrice"></field>
<field column="IS_TMALL" name="isTmall"></field>
<field column="SALES_NUM" name="salesNum"></field>
<field column="COMMISSION_JIHUA" name="commissionJihua"></field>
<field column="COMMISSION_QUEQIAO" name="commissionQueqiao"></field>
<field column="COMMISSION" name="commission"></field>
<field column="TB_GOODS_ID" name="tbGoodsId"></field>
<field column="PRICE" name="price"></field>
<field column="QUAN_PRICE" name="quanPrice"></field>
<field column="CREATE_TIME" name="creatTime"></field>
<field column="CID" name="cId"></field>
</entity>
</document>
</dataConfig>
稍微解释下:
标签内的内容,需要根据自己的数据库进行配置就行了。
entity dataSource=”JdbcDataSource” 的‘’dataSource‘’属性,跟dataSource type=”JdbcDataSource” 的type属性对应。
query:query的语句,是全量导入的语句 也就是后续再页面上点击全量导入时,执行的是该语句;
deltaQuery:deltaQuery是查询增量id的语句,该语句需要制定一个id,该id一般是指主键,通常与managed-schema文件中的 id对应起来,该语句的作用是,查询到solr服务器和数据库不一致的数据,进行增量操作。我这里是用数据库数据创建的时间,和上次导入的时间进行对比,如果数据库有新的时间,那么就认为该id是新插入数据库的,这样后续增量更新到solr服务器就可以达到同步的状态了。
deltaImportQuery:增量导入语句,该语句会根据deltaQuery查询到id值,将数据库的数据更新到solr的。
deletedPkQuery:deletedPkQuery语句是删除语句,solr会根据该语句查询到的id值,把solr服务器的响应数据进行删除!
“dataimporter.import170data.lastindextime”:该参数是指最近一次把数据库数据导入到solr服务器的时间。import170data是entity的名,只有一个entity时,该名可以删除。dataimporter.import170data.lastindextime”:该参数是指最近一次把数据库数据导入到solr服务器的时间。import170data是entity的名,只有一个entity时,该名可以删除。{dih.delta.ID} 这个是索引。直接用即可。
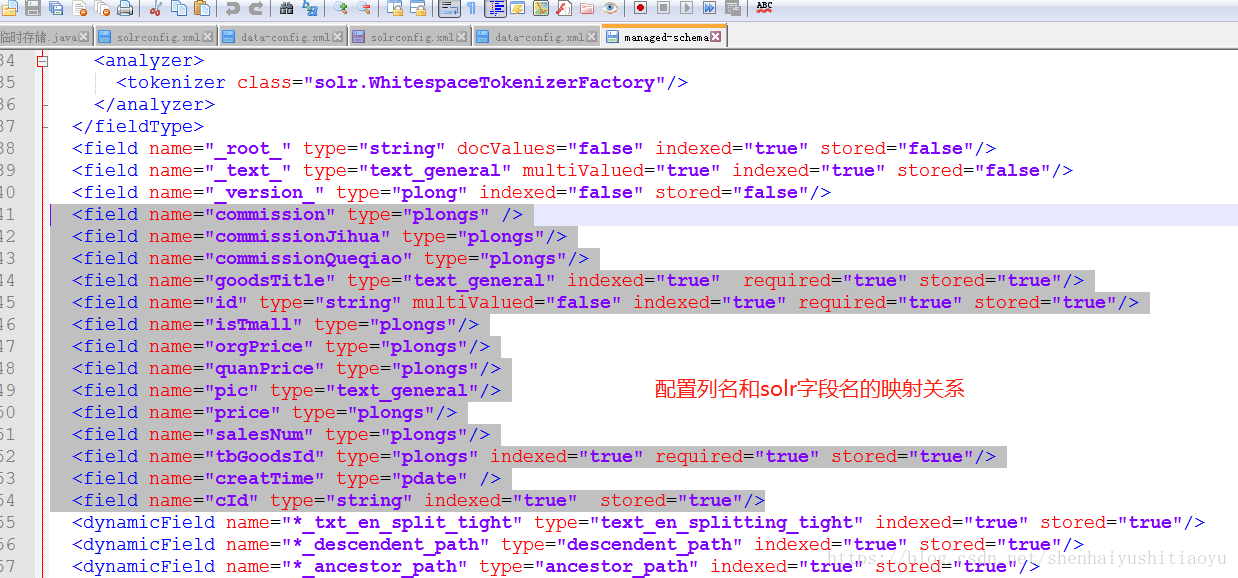
五、配置managed-schema中的数据库列和名称的映射关系。
将下列代码复制到managed-schema中:
<field name="commission" type="plongs" /> <field name="commissionJihua" type="plongs"/> <field name="commissionQueqiao" type="plongs"/> <field name="goodsTitle" type="text_general" indexed="true" required="true" stored="true"/> <field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/> <field name="isTmall" type="plongs"/> <field name="orgPrice" type="plongs"/> <field name="quanPrice" type="plongs"/> <field name="pic" type="text_general"/> <field name="price" type="plongs"/> <field name="salesNum" type="plongs"/> <field name="tbGoodsId" type="plongs" indexed="true" required="true" stored="true"/> <field name="creatTime" type="pdate" /> <field name="cId" type="string" indexed="true" stored="true"/>
六、至此,相关配置已经处理完成啦!下面开始导入数据:
去solr-7.3.1/bin下启动solr:
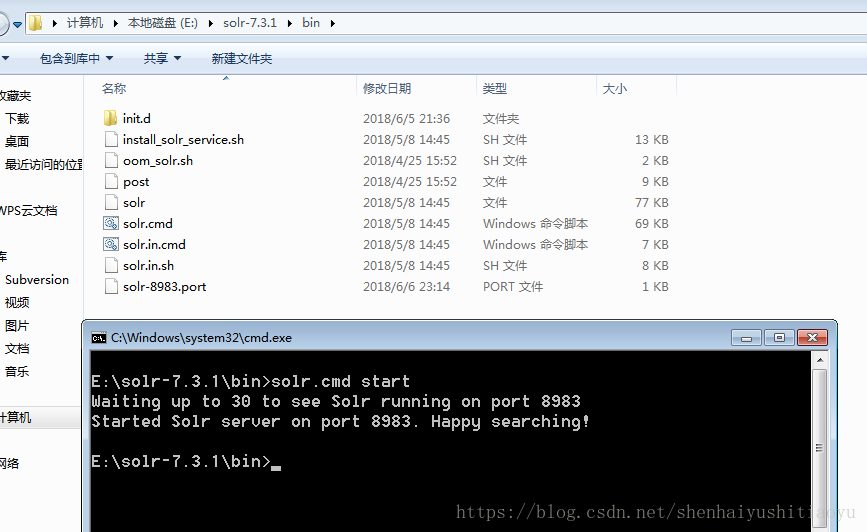
在浏览器输入 localhost:8983/solr 进入后,找到自己的core 然后根据下图进行数据导入:
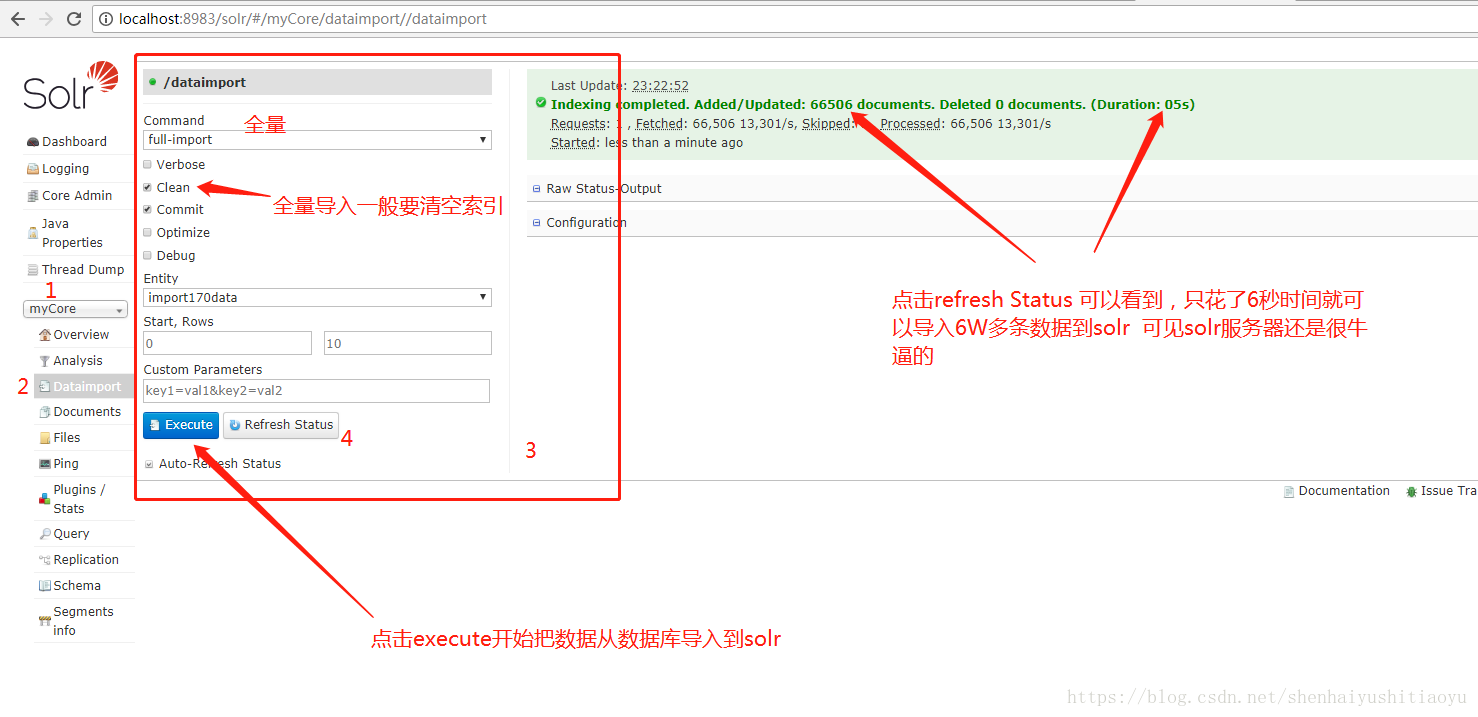
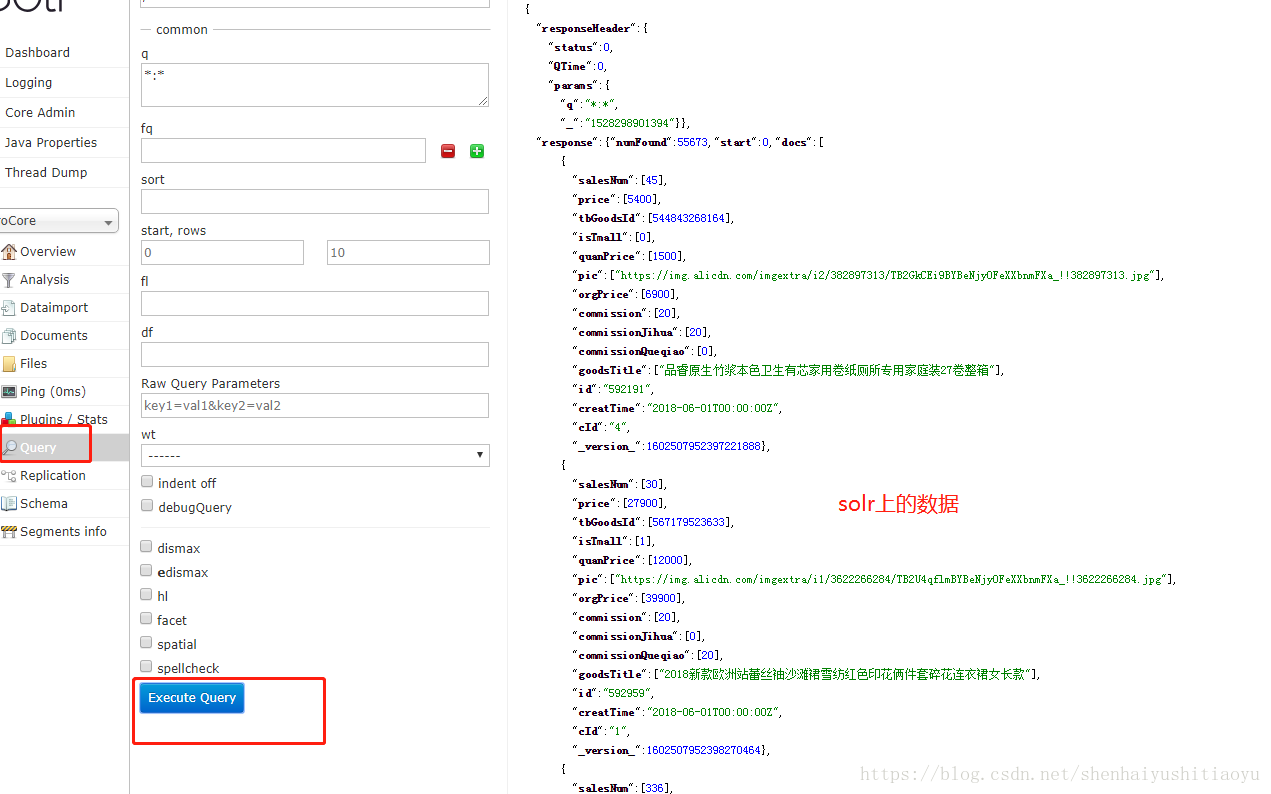
点击左边的query 就可以查询看看是否有数据导入了
增量导入:
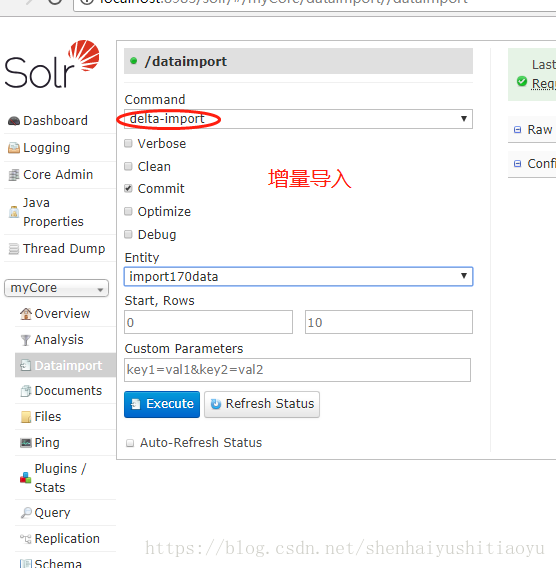
至此,solr服务器的安装,数据库配置,全量,增量更新已经处理完成。接下来的文章,会讲解用solrJ 在java代码中,进行定时同步,还有增删改查的。
如果有文件找不到或者有问题的朋友,可以加我创建的solr技术群。后续我们还会搭建cloud集群 将会第一时间发在群里。

本文允许转载。
阅读更多
- solr 7+tomcat 8 + mysql实现solr 7基本使用(安装、集成中文分词器、定时同步数据库数据以及项目集成)
- solr 7+tomcat 8 + mysql实现solr 7基本使用(安装、集成中文分词器、定时同步数据库数据以及项目集成)
- Solr5.5版本搭建与配置增量更新索引
- java使用solrJ进行增删查改,排序
- 项目记录:solr4.2 在tomcat7 的两种(singlecore + multicore) 配置安装 及solrj 的初步使用
- 使用Java对数据库进行基本的查询和更新操作
- JAVAWEB开发之Solr的入门——Solr的简介以及简单配置和使用、solrJ的使用、Solr数据同步插件
- 框架 day80 涛涛商城项目-redis安装单机版solr,搭建搜索服务层,solrJ使用
- Solr定时全量更新索引(不使用solr配置方式)
- linux基础简介 系统安装 常用命令 系统命令 软件管理 搭建Java服务器并进行远程管理
- 用SVN进行版本控制和项目管理的安装配置和使用方法
- 企业级搜索应用服务器Solr4.10.4部署开发详解(3)- Solr使用-使用java客户端solrj进行增删改查开发
- solr 配置自动同步数据库数据(全量,增量)
- Windows7(32位)下SVN进行版本控制和项目管理的安装配置和使用方法简述
- XMPP框架 微信项目开发之XMPP配置(二)——安装配置客户端(Adium)和配置系统自带的信息程序,并对聊天进行测试
- solr5.5配置定时全量、增量同步索引mysql数据
- Java操作Hbase进行建表、删表以及对数据进行增删改查,条件查询
- JavaCrazyer Java操作Hbase进行建表、删表以及对数据进行增删改查,条件查询
- MySQL5.5.23数据库免安装版本在Windows系统上配置启动
- Java操作Hbase进行建表、删表以及对数据进行增删改查,条件查询