MDNet -- 学习用于视觉跟踪的多域卷积神经网络
摘要
作者提出了一种新颖的视觉跟踪算法,基于一个来自有区别训练的CNN的表示(representation)。算法中使用大量跟踪视频的ground-truth来对CNN进行预训练,以获得通用的目标表示。
网络由共享层和特定域的层的多分支组成,其中域对应于独立的训练等级,并且每个分支负责一个二分类去识别每个域中的目标。我们针对每个域迭代地训练网络来获得共享层中的通用目标表示。
当跟踪一个新的视频序列中的目标时,我们将通过结合预训练CNN中的共享层与一个新的(在线更新的)二分类层来构建新的网络。在线跟踪(online tracking)是通过评估之前帧目标周围(附近)随机采样得到的候选窗口实现的。
与现有跟踪基准中的最新方法相比,所提出的算法表现出优异的性能。
一、Introduction
最近,CNN被应用于各种计算机视觉任务,如图像分类,语义分割,物体检测等等。 CNN的这种巨大成功主要归因于其在表现视觉数据方面的出色表现。 然而,视觉跟踪受这些流行趋势的影响较小,因为很难为视频处理收集大量训练数据,而专门用于视觉跟踪的训练算法尚不可用,并且基于低级手工的特征方法在实践中仍然很好用。
最近的一些跟踪算法已经通过迁移在大规模分类数据集(如ImageNet)上预训练的CNN的方法解决了数据不足的问题。尽管这些方法可能足以获得通用特征表示,但由于分类和跟踪问题的基本不一致,比如预测对象类别标签与定位任意类别的目标,所以在跟踪方面的有效性是有限的。
为了在视觉跟踪任务中充分利用CNN的表示力(representation power),需要对它们在视觉追踪的大规模数据上进行专门的训练,并且这些数据中涵盖目标和背景组合的各种变化。然而,在具有完全不同特征的视频序列上学习统一的特征表示真的具有挑战性。更加值得注意的是,单个序列中涉及不同类别的目标,其类别标签,移动模式和外观都不尽相同,并且跟踪算法受特殊序列挑战,包括遮挡,变形,光照条件变化,运动模糊等。这使得CNN的训练更加困难,因为同一类型的对象可能在一个视频序列中为目标而在另一个序列中却是背景。
由于这些序列之间的差异和不一致性,我们认为基于标准分类任务的普通学习方法是不合适的,另一种为了得到更好的跟踪特征表示而捕获序列无关信息(approach to capture sequence-independent information )的方法应该被采纳。
受此启发,作者提出了一种被称为多域网络(MDNet)的新型CNN体系结构,用于从多个注释视频序列中学习目标的共享表示(shared representation)以进行跟踪,其中每个视频被视为一个单独的域。 提出的这种网络在末端具有用于每个独立特定域二分类的分支,并且共享从前面层中的所有序列中捕获的用来学习通用表示特征的共同信息。 MDNet中的每个域在分别进行迭代训练,共享层在每次迭代中更新。 通过采用这种策略,我们将领域独立信息与领域特定信息分开,并学习用于视觉跟踪的通用特征表示。 MDNet结构的另一个有趣的方面是,我们设计的CNN与分类任务的网络相比,例如AlexNet 和VGG网络,层数更少。
我们还提出了一个有效的在线跟踪框架,该框架基于MDNet获得的特征表示。
当给出一个测试序列时,所有在训练阶段使用的二元分类层的现有分支被删除,并构造一个新的单分支来计算测试序列中的目标分数。 然后在跟踪过程中对共享层内的新分类层和完全连接层进行微调,以适应新的域。 在线更新是为了模拟目标的长期和短期外观变化以分别提高鲁棒性和适应性,并将有效且高效的硬性负面挖掘技术(an effective and efficient hard negative mining technique)纳入学习过程。
本文算法由多领域表示学习和在线视觉追踪组成。主要工作和贡献如下:
•提出了一个基于CNN的多域学习框架,将领域独立信息与领域特定信息分开,以有效捕获共享表示。
•框架已成功应用于视觉跟踪,其中通过多域学习预训练的CNN在新序列中根据上下文在线更新,以自适应地学习领域特定信息。
•广泛实验证明本文跟踪算法与两项公共基准测试中的最新技术相比具有出色表现:对象跟踪基准(Object Tracking Benchmark)和VOT2014。
本文的其余部分安排如下: 第2部分中首先回顾的相关工作,第3节中讨论多领域视觉跟踪学习方法,第4节介绍在线学习和跟踪算法,第5节演示两个跟踪基准数据集的实验结果。
二、相关工作
2.1 视觉跟踪算法
视觉跟踪是计算机视觉中的一个基本问题,并且已经积极研究了数十年。
大多数跟踪算法都属于生成或判别方法。 生成方法使用生成模型描述目标外观,并搜索最适合模型的目标区域。 已经提出了各种生成目标外观建模算法,包括稀疏表示,密度估计和增量子空间学习。
判别方法的目标是建立一个区分目标对象和背景的模型。 这些跟踪算法通常基于多实例学习,P-N学习,在线增强,结构化输出SVM 等学习分类器。
近年来,由于其计算效率和竞争性能,相关滤波器已经在视觉跟踪领域受到关注。 Bolme等人提出了一种快速相关跟踪器,其最小输出和平方误差(MOSSE)滤波器,以每秒数百帧的速度运行。 Henriques等人使用循环制定核化相关滤波器(KCF)矩阵,并在傅立叶域中有效地结合了多通道特征。随后研究了几种KCF跟踪器的变体以改善跟踪性能。例如,DSST 学习单独的滤波器进行翻译和缩放,MUSTer使用受心理记忆模型启发的短期和长期记忆存储。虽然这些方法在受限的环境中令人满意,但它们有其固有的局限性,即它们会借助于低级别的手工特征,这些特征在包括光照变化,遮挡,变形等动态情况下易受影响。
2.2 CNN
CNN在广泛的计算机视觉应用中展示了其杰出的特征表达能力。 Krizhevsky等人。通过使用大规模数据集和高效的GPU实现训练深度CNN,在图像分类方面带来显着的性能改进。R-CNN通过对大型辅助数据集进行预训练并对目标数据集进行微调,将CNN应用于训练数据稀缺的对象检测任务。尽管CNN取得了巨大的成功,但迄今为止仅提出了有限数量的使用CNN表示的跟踪算法。
基于CNN的早期跟踪算法只能处理预定义的目标对象类,例如人类,因为CNN在跟踪之前被离线训练而在之后被修复。尽管[28]提出了一种基于CNN池的在线学习方法,但缺乏培训深度网络的训练数据,与基于手工特征的方法相比,其准确性并不是特别好。最近的一些方法[39,20]将预处理的CNNs转移到为图像分类而构建的大规模数据集上,但由于分类和跟踪任务之间的根本区别,表示可能不是非常有效。
我们的算法与现有方法相反,利用大规模视觉跟踪数据来预训练CNN并获得有效的表示。
2.3 多域学习(Multi-Domain Learning)
本文的深层CNN预练练方法属于多域学习,它指的是一种学习方法,其中训练数据来源于多个领域,领域信息被纳入学习过程。
多领域学习在自然语言处理(例如,具有多个产品的情感分类和具有多个用户的垃圾邮件过滤)中很流行,并且已经提出了各种方法。 在计算机视觉领域中,只有少数领域适应方法讨论了多领域学习。例如,Duan等人引入了用于视频概念检测的SVM的域加权组合,并且Hoffman等人 提出了一个混合变换模型的对象分类。
三、MultiDomain Network(MDNet)
本节介绍CNN体系结构和多域学习方法,以获取视频跟踪的领域独立表示(domain-independent representations)。
3.1 网络结构 Network Architecture
网络的体系结构如图1所示。它输入107×107大小的RGB,并具有五个隐藏层,包括三个卷积层(conv1-3)和两个全连接层(fc4-5)。另外,网络最后对于K个域(K个训练序列)对应的全连接层具有K个分支(fc6.1-fc6.K)。卷积层与VGG-M网络的相应部分相同,除了特征图尺寸是由输入尺寸调整的。接下来的两个完全连接的层具有512维输出,并且与ReLU和Dropout结合。每个K分支包含一个具有softmax交叉熵损失的二分类层,它负责区分每个域(训练视频)中的目标和背景。 注意:我们将fc6.1 -fc6.K称为域特定层(domain-specific),将之前的所有层称为共享层(shared layers)。
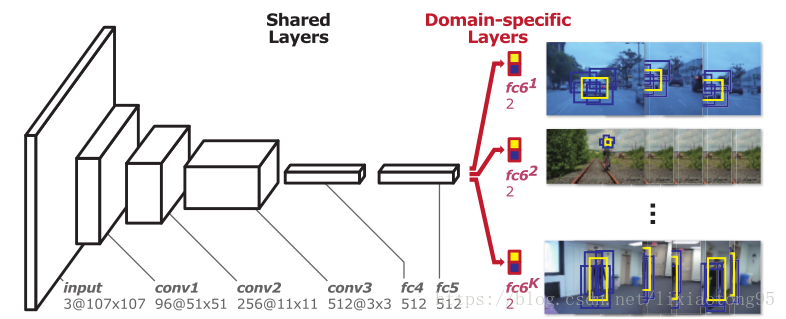
图1. MDNet 网络结构图
MDNet网络架构远远小于典型图像识别任务中常用的网络架构,如AlexNet 和VGG-Nets。
作者认为由于以下原因,这种简单的架构更适合视觉追踪:
第一,视觉追踪旨在区分目标和背景两个类别,这需要比一般视觉识别问题(例如具有1000个类别的ImageNet分类)少得多的模型复杂度。
第二,深度CNN对于精确目标定位的效果较差,因为随着网络的深入,空间信息往往会被稀释。
第三,由于视觉跟踪中的目标通常很小,因此希望缩小输入大小,这自然会降低网络的深度。(?缩小输入减低分辨率会不会损失空间信息量? 小目标和大目标分别处理?)
第四,一个较小的网络在视觉追踪问题上明显更有效率,在线训练和测试是在线进行的。当我们测试更大的网络时,算法不太准确,并且变得更慢。
3.2 学习算法 Learning Algorithm
学习算法的目标是训练一个多域CNN可以在任意域中辨别目标和背景,这不是直接的,因为来自不同域的训练数据对目标和背景有不同的概念。不过,对于所有域中的目标表示仍然存在一些常见描述属性,例如对照明变化的鲁棒性,运动模糊,尺度变化等。为了提取满足这些公共属性的有用特征,我们通过结合多领域学习框架将领域独立信息与领域特定信息分开。
CNN通过随机梯度下降(SGD)方法进行训练,其中每个域都在每个迭代中专门处理。
在第k次迭代中,网络基于一个由第(k mod K )(k除以K取余数)个序列的训练样本组成的minibatch更新,其中仅启用第(k mod K)的单个分支fc6。一直重复,直到网络收敛或达到预定义的迭代次数。
PS:第一次迭代,用来自sequence1(训练集中的视频序列)的一个minibatch训练网络进行更新;
第二次迭代,用来自sequence2 的一个minibatch训练网络进行更新;
.
.
第k次迭代,用来自sequence(k mod K)的一个minibatch训练网络进行更新;
通过这个学习过程,独立于领域的信息在共享层中建模,从中获得有用的通用特征表示。
四、Online Tracking using MDNet
当我们完成了上节中描述的多领域学习,领域特定层的多个分支(fc6.1-fc6.K)就会被替换为单个分支(fc6),以用于新的测试序列。 然后我们同时在线调整共享网络中的新特定域层和全连接层。
4.1 Tracking Control and Network Update 跟踪控制和网络更新
通过长期和短期的更新,我们考虑视觉追踪中的两个互补方面,鲁棒性和适应性。
使用长期收集的正样本,进行定期长期更新,而每当检测到潜在的跟踪失败/故障时(当估计目标被分类为背景时),则使用短期内采集的正样本实施更新。
在这两种情况下,我们都使用在短期观察到的负样本,因为旧的负样本往往对当前帧来说是冗余的或不相关的。
Note that we maintain a single network during tracking, where these two kinds of updates are performed depending on how fast the target appearance changes.
注意,我们在跟踪期间保持单个网络,这两种更新根据目标外观变化的速度被执行。
为了估计每帧中的目标状态,使用网络对前一个目标状态周围采样的N个目标候选者x1,...,xN进行评估,我们从网络中获得它们的正分数f +(x i)和负分数f - (x i),通过找到具有最大正分数的候选者给出最优目标状态x * 即:
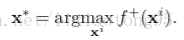
4.2 Hard Minibatch Mining (困难小批次样本挖掘)
大多数负样本在跟踪检测方法中通常是不重要的或冗余的,而只有少数背景干扰的负样本在训练分类器时是有效的。因此,普通的SGD方法(训练样本均匀地贡献于学习)容易遭受漂移(drift?)问题,因为背景干扰负样本是不够的。这个问题的一个流行解决方案是硬性负样本挖掘(还是困难负样本挖掘?),训练程序和测试程序交替识别困难负样本,通常检测结果是假阳性(false positives),我们采用这个想法来进行在线学习。
我们将困难负样本挖掘步骤在小批量(minibatch)选择中进行。在我们学习过程的每一次迭代中,每个minibatch包含M+个正数和Mh - 个困难负样本。 通过测试M - 个(远多于Mh-个)负样本并选择具有最高阳性分数(positive scores)的Mh-个样本作为困难负样本。
随着学习的进行网络的辨别能力越来越好,小批量中的分类变得更加具有挑战性(图2所示)。该方法检验预定数量的样本,并有效识别关键负样本,而不需要像标准的困难负样本挖掘技术中那样明确地运行检测器来找出假阳性样本(false positives)。

图2
4.3 Bounding Box Regression 边界框回归
由于基于CNN的高级特征抽象和我们的数据增强策略(在目标周围对多个正示例采样)网络有时无法找到精确包围目标的边框。我们应用在目标检测中很普遍的边界框回归技术来提高目标定位精度。由给出的测试序列的第一帧,我们使用目标位置附近样本的conv3特征训练一个简单的线性回归模型,来预测目标的精确位置。在随后的帧中,如果待评估的样本可靠(f +(x *)> 0.5)我们便利用回归模型评估方程式

由于边界框回归器仅在第一帧中进行训练并且在线更新十分耗费时间考虑到,回归模型的增量学习风险可能帮助不大,所以使用了相同的公式和参数。
4.4 Implementation Details 实施细节
跟踪算法的总体过程如下。
----------------------------------------------------------------------------------------------------------------------
在线跟踪算法:
输入:预训练好的CNN卷积权重{w1,w2,...w5}(五个卷积层)
初始目标状态x1
输出:预测的之后帧中的目标状态xt*
1. 随机初始化最后一层权重w6 (特定域的新分支二分类器);
2.训练边界框回归模型
3.绘制正样本S1+和负样本S1-
4.用S1+和S1-更新{w4,w5,w6}
5. Ts ← {1} and Tl ← {1} PS: Ts和Tl分别是短周期(τs = 20)和长周期(τl = 100)的帧索引集。
6. repeat
7. 绘制目标候选样本
8. 根据公式
9.

10. 直到序列结束
------------------------------------------------------------------------------------------------------------------------
目标候选区域生成:
为了在每帧生成候选目标,我们在平移和尺度维上绘制N(N= 256)个样本,
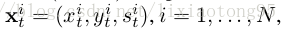
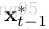
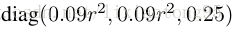
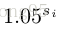
训练数据:
对离线多领域学习,我们从每帧中收集50个正样本和200个负样本,其中正负样本分别与gt边界框具有≥0.7和≤0.5的IoU重叠比率。 同样,对于在线学习,我们收集St+(= 50)正样本和St-(= 200)负样本分别与估计的目标边界框重叠比≥0.7和≤0.3,除了S1+= 500,S1-= 5000。对于边界框回归,我们使用1000个训练样本。
网络学习:
对于具有K个训练序列的多域学习,训练网络进行100K迭代,卷积层的学习率为0.0001,全连接层的学习率为0.001。在测试序列的初始化框架中,训练全连接的层进行30次迭代,其中fc4-5的学习率为0.0001,fc6的学习率为0.001。对于在线更新,我们训练全连接的层进行10次迭代,学习速率比初始帧中的快3倍。动量和重量衰减总是分别设定为0.9和0.0005。每个小批量包含M+(= 32)个正样本和从M-(= 1024)个负样本中选出的M h -(= 96)个困难负样本。
五、Experiment 实验结果(见论文,略)
5.1 Evaluation on OTB
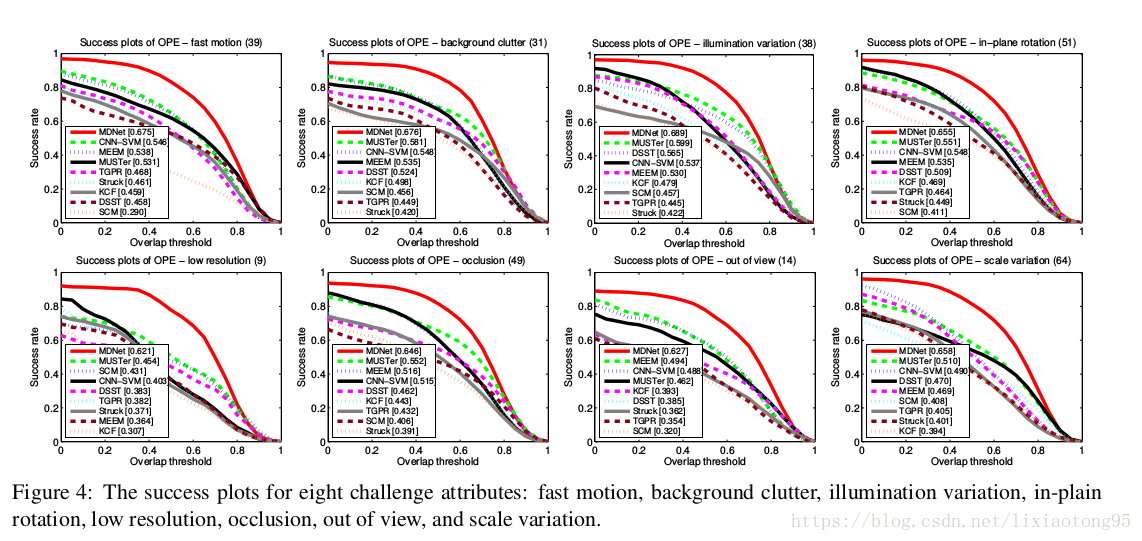
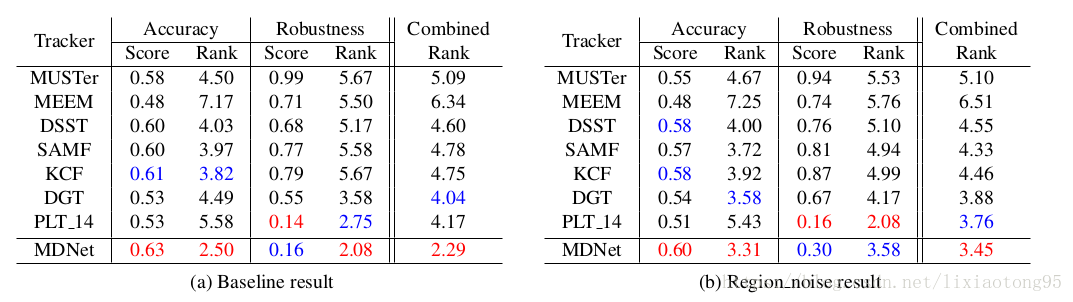
5.2 Evaluation on VOT2014 Dataset
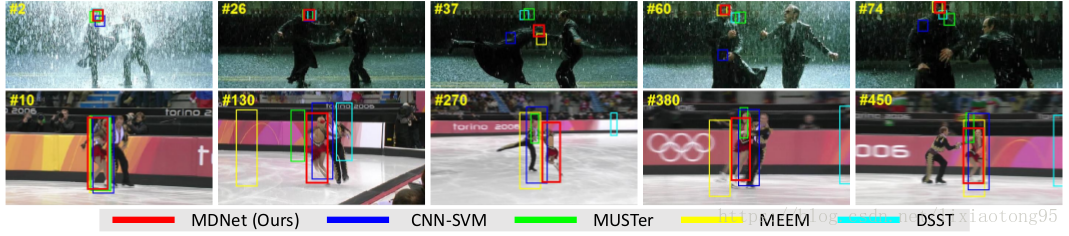
部分跟踪结果展示

六、Conclusion 总结
作者提出了一种新的基于CNN的多领域学习框架中的跟踪算法,它被称为MDNet。 这种跟踪算法通过预训练学习独立于域的表示,并在跟踪期间通过在线学习获取特定领域的信息。与设计用于图像分类任务的网络相比,所提出的网络具有简单的架构。
整个网络预训脱机,包括一个特定域特定层的全连接层在线调整。 与最先进的跟踪算法相比,在两个大型公共跟踪基准OTB和VOT2014中取得了出色表现。
阅读更多

- 【神经网络与深度学习】【计算机视觉】SPPNet-引入空间金字塔池化改进RCNN
- 【论文学习】神经光流网络——用卷积网络实现光流预测(FlowNet: Learning Optical Flow with Convolutional Networks)
- MDNet(multi domain CNN用于视觉跟踪)--源代码详解--mdnet_features_fcX.m
- 【计算机视觉】【神经网络与深度学习】深度学习在图像超分辨率重建中的应用
- 深度学习算法之卷积神经网络简介
- 深度学习算法之卷积神经网络简介
- 深度学习之卷积神经网络
- 深度学习之卷积神经网络总结
- 深度学习(四)卷积神经网络入门学习(1)
- 【神经网络与深度学习】卷积与反卷积
- 深度学习与自然语言处理之四:卷积神经网络模型(CNN)
- CNN学习笔记(二)卷积神经网络经典结构
- 学习笔记TF052:卷积网络,神经网络发展,AlexNet的TensorFlow实现
- Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.1
- 【计算机视觉】【神经网络与深度学习】论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 深度学习算法之卷积神经网络简介
- 深度学习与自然语言处理之四:卷积神经网络模型(CNN)
- [原]Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.3
- 深度学习算法之卷积神经网络简介
- 学习笔记TF052:卷积网络,神经网络发展,AlexNet的TensorFlow实现