python scrapy爬取腾讯招聘网站保存为csv文件,而且设定其表头顺序(csv默认是无序的)
要点:1.设定UA
2.创建csv_item_exporter.py 设定csv
3.settings.py设定好参数
4.begin启动程序
目标网址:http://hr.tencent.com/position.php?keywords=&tid=0&star
spider.py(主体很简单)
import os,io,sys,re
from scrapy.spider import Spider
from scrapy.selector import Selector
from lianxi.items import LianxiItem
from scrapy import Request
class LianxiSpider(Spider):
name = "lianxi"
allowed_domains = ["hr.tencent.com"]
start_urls = []
# 起始urls列表
for i in range(0,200,10): #爬取了20页
url='https://hr.tencent.com/position.php?&start='+str(i)+'#a'
start_urls.append(url)
def parse(self, response):
geduan=response.xpath('//table[@class="tablelist"]/tr[not(@class="h"or@class="f")]')
item=LianxiItem()
for zhiwei in geduan:
name=zhiwei.xpath('.//td[@class="l square"]//a//text()').extract()
item['name']="".join(name).strip()
genre=zhiwei.xpath('./td[2]/text()').extract()
item['genre']="".join(genre).strip()
number=zhiwei.xpath('./td[3]/text()').extract()
item['number'] = "".join(number).strip()
place=zhiwei.xpath('./td[4]/text()').extract()
item['place'] = "".join(place).strip()
time = zhiwei.xpath('./td[5]/text()').extract()
item['time'] = "".join(time ).strip()
yield item
items.py
import scrapy
class LianxiItem(scrapy.Item):
name = scrapy.Field() #招聘单位
genre = scrapy.Field() #招聘类型
number = scrapy.Field() #招聘人数
place = scrapy.Field() #招聘地点
time = scrapy.Field()
middlewares.py 设置了随机UA,可以下载fake_useragent模块
from fake_useragent import UserAgent #下载此模块才有
from scrapy import signals
import random
import logging
from scrapy.utils.response import response_status_message
logger = logging.getLogger(__name__)
class RandomUserAgent(object):
def __init__(self,):
self.agent=UserAgent() ##headers的模块
def process_request(self,request,spider):
request.headers.setdefault('User-agent',self.agent.random)##随机选择headers
@classmethod #文件默认
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
Pipelines.py 不写也没问题
class LianxiPipeline(object):
def process_item(self, item, spider):
print (item)
return item
重点来了!!!csv_item_exporter.py ,设置保存csv文件的顺序,跟spider.py同一个文件夹
from scrapy.conf import settings from scrapy.contrib.exporter import CsvItemExporter import io class MyProjectCsvItemExporter(CsvItemExporter): def __init__(self, *args, **kwargs): delimiter = settings.get('CSV_DELIMITER', ',') kwargs['delimiter'] = delimiter fields_to_export = settings.get('FIELDS_TO_EXPORT', []) if fields_to_export : kwargs['fields_to_export'] = fields_to_export super(MyProjectCsvItemExporter, self).__init__(*args, **kwargs)同时,settings.py 也要设置对应的csv参数
BOT_NAME = 'lianxi' SPIDER_MODULES = ['lianxi.spiders'] NEWSPIDER_MODULE = 'lianxi.spiders' ITEM_PIPELINES = { 'lianxi.pipelines.LianxiPipeline': 100, } DOWNLOADER_MIDDLEWARES = { 'lianxi.middlewares.RandomUserAgent': 20, 'doubanmovie.middlewares.RandomProxy':None, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':None, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':100, } RETRY_ENABLED = False DOWNLOAD_DELAY = 0.5 COOKIES_ENABLED = False ##########==========保存为csv文件设定表头顺序!! FEED_EXPORTERS = { 'csv': 'lianxi.spiders.csv_item_exporter.MyProjectCsvItemExporter', } FIELDS_TO_EXPORT = [ 'name', 'genre', 'number', 'place', 'time', ]
OK,最后设定begin.py,启动程序
from scrapy import cmdline
cmdline.execute("scrapy crawl lianxi -o info.csv -t csv".split())好了,结果如下
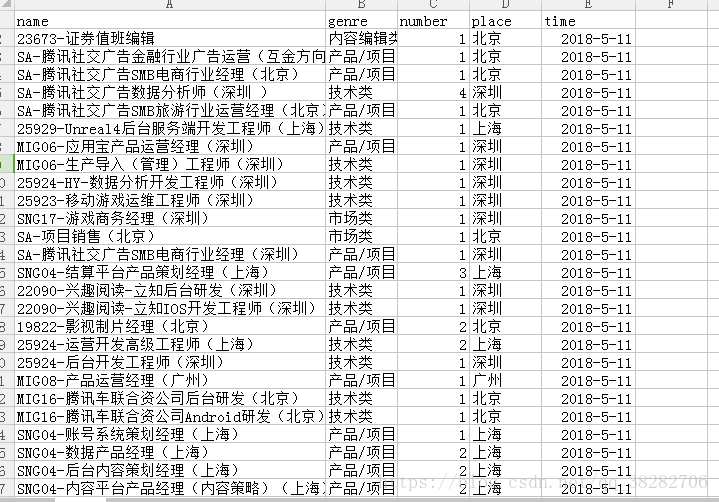

- python爬虫--scrapy爬取腾讯招聘网站
- python的pandas工具包,保存.csv文件时不要表头的实例
- scrapy用不同规则抓取多个网站(基于csv文件)以及向爬虫传递参数(参数可默认)
- python的pandas工具包,保存.csv文件时不要表头。
- 几行Python代码生成饭店营业额模拟数据并保存为CSV文件
- python爬虫2——beautifusoap4的使用讲解与腾讯招聘网站爬虫
- Python3使用csv模块csv.writer().writerow()保存csv文件,产生空行的问题
- Python 随机生成100行1000列的0~5之间的数据,并保存到csv文件
- 数据保存!!!Python 爬取网页数据后,三种保存格式---保存为txt文件、CSV文件和mysql数据库
- 使用python的pandas库读取csv文件保存至mysql数据库
- 单个爬虫文件使用scrapy保存为csv格式
- 解决python3.6下scrapy中xpath.extract()匹配出来的内容转成json与.csv文件没有编码(unicode)的问题
- Python数据处理-将数据保存为txt、csv等文件格式方法
- 使用Python和BeautifulSoup爬取历史上的今天网站并将描述及网址存储到csv文件中
- scrapy保存为csv文件 再将csv导入excel方法,及导入excel时出错:"自文本导入 包含的数据无法放置在一个工作表中"的坑
- Python3使用csv模块csv.writer().writerow()保存csv文件,产生空行的问题
- python通过串口读取GPS NMEA格式的数据,并保存为csv文件
- 利用python抓取搜狗关于数据分析的文章并保存到csv文件
- python3实战scrapy生成csv文件