第八章| 3. MyAQL数据库|Navicat工具与pymysql模块 | 内置功能 | 索引原理
1、Navicat工具与pymysql模块
在生产环境中操作MySQL数据库还是推荐使用命令行工具mysql,但在我们自己开发测试时,可以使用可视化工具Navicat,以图形界面的形式操作MySQL数据库[/code]
掌握: #1. 测试+链接数据库 #2. 新建库 #3. 新建表,新增字段+类型+约束 #4. 设计表:外键 #5. 新建查询 #6. 备份库/表 #注意: 批量加注释:ctrl+?键 批量去注释:ctrl+shift+?键
之前我们都是通过MySQL自带的命令行客户端工具mysql来操作数据库,那如何在python程序中操作数据库呢?这就用到了pymysql模块,该模块本质就是一个套接字客户端软件,使用前需要事先安装
pip3 install pymysql
准备账号、表
用cmd授权一个账号
C:\Users\Administrator>mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 12 Server version: 5.6.39 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> grant all on *.* to 'root'@'%' identified by '123'; Query OK, 0 rows affected (0.07 sec) mysql> flush privileges; Query OK, 0 rows affected (0.12 sec)
查看IP地址:
在管理员权限下运行cmd,输入ipconfig
IPv4 地址 . . . . . . . . . . . . : 192.168.1.123
import pymysql
user=input('user>>: ').strip()
pwd=input('password>>: ').strip()
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿到游标
cursor=conn.cursor()
# 执行sql语句
# sql='select * from userinfo where user = "%s" and pwd="%s"' %(user,pwd)
# print(sql)
sql='select * from userinfo where user = %s and pwd=%s'
rows=cursor.execute(sql,(user,pwd)) #提交给游标执行 execute这个接口拿到的是2 rows in set (0.00 sec) 2那个行数,如果值不为0说明就输对了
cursor.close()
conn.close()
# 进行判断
if rows:
print('登录成功')
else:
print('登录失败')
mysql语句中 -- xfjl ,--+空格后边的都给你注释掉了
import pymysql
user=input('user>>: ').strip()
pwd=input('password>>: ').strip()
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿到游标
cursor=conn.cursor()
# 执行sql语句
sql='select * from userinfo where user = "%s" and pwd="%s"' %(user,pwd)
print(sql)
rows=cursor.execute(sql)
#sql='select * from userinfo where user = %s and pwd=%s'
#由execute作为拼接,不用你自己去拼接了,在拼接过程中给你过滤掉这种非法操作
#rows=cursor.execute(sql,(user,pwd)) #提交给游标执行 execute这个接口拿到的是2 rows in set (0.00 sec) 2那个行数,如果值不为0说明就输对了
cursor.close()
conn.close()
# 进行判断
if rows:
print('登录成功')
else:
print('登录失败')
打印: #两种执行的错误
user>>: egon" -- xxxhhhh
password>>:
select * from userinfo where user = "egon" -- xxxhhhh" and pwd=""
登录成功
user>>: xxxx" or 1=1 -- hhhhhaaa
password>>:
select * from userinfo where user = "xxxx" or 1=1 -- hhhhhaaa" and pwd=""
登录成功
改正:
import pymysql
user=input('user>>: ').strip()
pwd=input('password>>: ').strip()
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿到游标
cursor=conn.cursor()
# 执行sql语句
# sql='select * from userinfo where user = "%s" and pwd="%s"' %(user,pwd)
# print(sql)
# rows=cursor.execute(sql)
sql='select * from userinfo where user = %s and pwd=%s'
#由execute作为拼接,不用你自己去拼接了,在拼接过程中给你过滤掉这种非法操作
rows=cursor.execute(sql,(user,pwd)) #提交给游标执行 execute这个接口拿到的是2 rows in set (0.00 sec) 2那个行数,如果值不为0说明就输对了
cursor.close()
conn.close()
# 进行判断
if rows:
print('登录成功')
else:
print('登录失败')
增加
import pymysql
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿游标
cursor=conn.cursor()
# 执行sql
# 增、删、改 对数据的变动
sql='insert into userinfo(user,pwd) values(%s,%s)'
rows=cursor.execute(sql,('wxx','123'))
print(rows)
conn.commit() #必须加上这个
# 关闭
cursor.close()
conn.close()
打印:
1
#1、增删改
import pymysql
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿游标
cursor=conn.cursor()
# 执行sql
# 增、删、改 对数据的变动
sql='insert into userinfo(user,pwd) values(%s,%s)'
# rows=cursor.execute(sql,('wxx','123'))
# print(rows)
rows=cursor.executemany(sql,[('yxx','123'),('egon1','111'),('egon2','2222')]) #可以插入多条
print(rows)
conn.commit() #必须加上这个
# 关闭
cursor.close()
conn.close()
打印
3
#2、查询
import pymysql
# # 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
# 拿游标
cursor=conn.cursor(pymysql.cursors.DictCursor) #基于字典形式的游标,不加括号内的是以元组形式
# 执行sql
# 查询
rows=cursor.execute('select * from userinfo;') #把字符串send给服务端,在服务端把这个sql语句执行下,然后把结果丢给客户端
print(rows)
# print(cursor.fetchone()) #代表取一行
# print(cursor.fetchone())
# print(cursor.fetchone())
# print(cursor.fetchone())
# print(cursor.fetchone())
# print(cursor.fetchone())
# print(cursor.fetchone())
#print(cursor.fetchmany(2)) #指定取的个数,以列表的形式
#print(cursor.fetchall()) #拿出所有,列表的形式
# print(cursor.fetchall())
cursor.scroll(3,mode='absolute') #移动光标 相对绝对位置移动,从头数3个开始取出来1个,结果是第4个
#print(cursor.fetchone())
cursor.scroll(2,mode='relative') # 相对当前位置移动 往后跳2位
print(cursor.fetchone())
# 关闭
cursor.close()
conn.close()
打印:
6
{'id': 6, 'user': 'egon2', 'pwd': '2222'}
import pymysql
#
# # 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db10',
charset='utf8'
)
#
# # 拿游标
cursor=conn.cursor()
sql='insert into userinfo(user,pwd) values(%s,%s)'
rows=cursor.executemany(sql,[('egon3','123'),('egon4','111'),('egon5','2222')])
print(cursor.lastrowid) #插入之前光标走到哪里了
#
conn.commit() #必须加上这个
# 关闭
cursor.close()
conn.close()
打印:
7
涉及数据库的操作的,先要编写好数据,然后基于pymysql模块帮我把sql语句提交给mysql服户端,执行完之后把结果再返回到应用程序中再做进一步的处理;将应用程序的开发与数据库的开发结合
2、mysql内置函数功能
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的sql了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的sql过分依赖数据库中的视图,即强耦合,那就意味着扩展sql极为不便,因此并不推荐使用
视图 只有表结构frm,没有数据,因为是查出来的虚拟表;不用重复写,但是不建议使用,如果有好多个视图,要找到所有的视图给它修改很麻烦;
mysql> use db7; Database changed mysql> select * from course; +-----+--------+------------+ | cid | cname | teacher_id | +-----+--------+------------+ | 1 | 生物 | 1 | | 2 | 物理 | 2 | | 3 | 体育 | 3 | | 4 | 美术 | 2 | +-----+--------+------------+ 4 rows in set (0.00 sec) mysql> select * from teacher; +-----+-----------------+ | tid | tname | +-----+-----------------+ | 1 | 张磊老师 | | 2 | 李平老师 | | 3 | 刘海燕老师 | | 4 | 朱云海老师 | | 5 | alex | +-----+-----------------+ 5 rows in set (0.00 sec) mysql> select * from course inner join teacher on course.teacher_id=teacher.tid; +-----+--------+------------+-----+-----------------+ | cid | cname | teacher_id | tid | tname | +-----+--------+------------+-----+-----------------+ | 1 | 生物 | 1 | 1 | 张磊老师 | | 2 | 物理 | 2 | 2 | 李平老师 | | 4 | 美术 | 2 | 2 | 李平老师 | | 3 | 体育 | 3 | 3 | 刘海燕老师 | +-----+--------+------------+-----+-----------------+ 4 rows in set (0.10 sec) mysql> create view course2teacher as select * from course inner join teacher on course.teacher_id=teacher.tid; Query OK, 0 rows affected (0.20 sec) mysql> show tables; +----------------+ | Tables_in_db7 | +----------------+ | course | | course2teacher | | teacher | +----------------+ 3 rows in set (0.00 sec) mysql>
触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
mysql> create database db11;
Query OK, 1 row affected (0.00 sec)
mysql> use db11;
Database changed
mysql> CREATE TABLE cmd (
-> id INT PRIMARY KEY auto_increment,
-> USER CHAR (32),
-> priv CHAR (10),
-> cmd CHAR (64),
-> sub_time datetime, #提交时间
-> success enum ('yes', 'no') #0代表执行失败
-> );
Query OK, 0 rows affected (0.77 sec)
mysql>
mysql> CREATE TABLE errlog (
-> id INT PRIMARY KEY auto_increment,
-> err_cmd CHAR (64),
-> err_time datetime
-> );
Query OK, 0 rows affected (0.68 sec)
#创建触发器
mysql> delimiter //
mysql> CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW
-> BEGIN
-> IF NEW.success = 'no' THEN #等值判断只有一个等号
-> INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号
-> END IF ; #必须加分号
-> END//
Query OK, 0 rows affected (0.34 sec)
mysql> delimiter ;
mysql>
mysql>
mysql>#往cmd中插入记录,触动触发器,根据IF条件决定是否插入错误日志
mysql> INSERT INTO cmd (
-> USER,
-> priv,
-> cmd,
-> sub_time,
-> success
-> )
-> VALUES
-> ('egon','0755','ls -l /etc',NOW(),'yes'),
-> ('egon','0755','cat /etc/passwd',NOW(),'no'),
-> ('egon','0755','useradd xxx',NOW(),'no'),
-> ('egon','0755','ps aux',NOW(),'yes');
Query OK, 4 rows affected (0.43 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from cmd; +----+------+------+-----------------+---------------------+---------+
| id | USER | priv | cmd | sub_time | success |
+----+------+------+-----------------+---------------------+---------+
| 1 | egon | 0755 | ls -l /etc | 2018-04-28 18:26:33 | yes |
| 2 | egon | 0755 | cat /etc/passwd | 2018-04-28 18:26:33 | no |
| 3 | egon | 0755 | useradd xxx | 2018-04-28 18:26:33 | no |
| 4 | egon | 0755 | ps aux | 2018-04-28 18:26:33 | yes |
+----+------+------+-----------------+---------------------+---------+
4 rows in set (0.00 sec)
mysql> select * from errlog; #查询错误日志发现有两条
+----+-----------------+---------------------+
| id | err_cmd | err_time |
+----+-----------------+---------------------+
| 1 | cat /etc/passwd | 2018-04-28 18:26:33 |
| 2 | useradd xxx | 2018-04-28 18:26:33 |
+----+-----------------+---------------------+
2 rows in set (0.00 sec)
存储过程
把mysql处理好的数据给封装好,一个接口名,应用程序可以直接调用接口,这个接口就叫储存过程。是mysql内置功能的一系列总和;
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
使用存储过程的优点:
1. 用于替代程序写的SQL语句,实现程序与sql解耦 2. 基于网络传输,传别名的数据量小,而直接传sql数据量大
使用存储过程的缺点:
1. 程序员扩展功能不方便
程序与数据库结合使用的三种方式:
#方式一: MySQL:存储过程 程序:调用存储过程 #方式二: MySQL: 程序:纯SQL语句 #方式三: MySQL: 程序:类和对象,即ORM(本质还是纯SQL语句)
创建简单的存储过程:
#1、无参存储过程 delimiter // create procedure p1() BEGIN select * from db7.teacher; END // delimiter ;
mysql> use db7; Database changed mysql> delimiter // mysql> create procedure p1() -> BEGIN -> select * from db7.teacher; -> END // Query OK, 0 rows affected (0.21 sec) mysql> delimiter ; mysql> mysql> mysql> show create procedure p1; +-----------+--------------------------------------------+-----------------------------------------------------------------------------------------+----------------------+----------------------+------ --------------+ | Procedure | sql_mode | Create Procedure | character_set_client | collation_connection | Datab ase Collation | +-----------+--------------------------------------------+-----------------------------------------------------------------------------------------+----------------------+----------------------+------ --------------+ | p1 | STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION | CREATE DEFINER=`root`@`localhost` PROCEDURE `p1`() BEGIN select * from db7.teacher; END | utf8 | utf8_general_ci | utf8_general_ci | +-----------+--------------------------------------------+-----------------------------------------------------------------------------------------+----------------------+----------------------+------ --------------+ 1 row in set (0.00 sec)
# MySQL中调用 call p1();
mysql> call p1(); +-----+-----------------+ | tid | tname | +-----+-----------------+ | 1 | 张磊老师 | | 2 | 李平老师 | | 3 | 刘海燕老师 | | 4 | 朱云海老师 | | 5 | alex | +-----+-----------------+ 5 rows in set (0.00 sec) Query OK, 0 rows affected (0.01 sec)
# Python中调用
cursor.callproc('p1') #调用存储过程
import pymysql
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db7',
charset='utf8'
)
# 拿游标
cursor=conn.cursor()
# 执行sql
cursor.callproc('p1') #只是执行
print(cursor.fetchall())
打印
((1, '张磊老师'), (2, '李平老师'), (3, '刘海燕老师'), (4, '朱云海老师'), (5, 'alex'))
#2、有参存储过程 #在mysql中参数必须指定类型,是用来接收值的还是返回值的
对于存储过程,可以接收参数,其参数有三类: #in 仅用于传入参数用 #out 仅用于返回值用 #inout 既可以传入又可以当作返回值
delimiter //
create procedure p2(in n1 int,in n2 int,out res int) #当存储过程p1执行完了,就把res当做返回值返回了这就是out的作用,只有out的值才能被返回
BEGIN
select * from db7.teacher where tid > n1 and tid < n2;
set res = 1;
END //
delimiter ;
# MySQL中调用
set @x=0 #初始值等于零
call p2(2,4,@x);
select @x;查看结果
# Python中调用
cursor.callproc('p2',(2,4,0))# @_p2_0=2,@_p2_1=4,@_p2_2=0
cursor.execute('select @_p3_2')
cursor.fetchone()
mysql> delimiter // mysql> create procedure p2(in n1 int, in n2 int, out res int) -> BEGIN -> select * from db7.teacher where tid > n1 and tid < n2; -> set res = 1; -> END // Query OK, 0 rows affected (0.06 sec) mysql> delimiter ; mysql> set @x=0; Query OK, 0 rows affected (0.00 sec) mysql> call p2(2,4,@x); +-----+-----------------+ | tid | tname | +-----+-----------------+ | 3 | 刘海燕老师 | +-----+-----------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.01 sec) mysql> select @x; +------+ | @x | +------+ | 1 | +------+ 1 row in set (0.00 sec)
import pymysql
# 建立链接
conn=pymysql.connect(
host='192.168.1.123',
port=3306,
user='root',
password='123',
db='db7',
charset='utf8'
)
# 拿游标
cursor=conn.cursor()
#
cursor.execute('select @_p2_2')
print(cursor.fetchone())
# 关闭
cursor.close()
conn.close()
打印
(1, )
应用程序与数据库结合使用 方式一: (很少用,部门之间沟通效率不高;优点很好解开了耦合,效率最高) Python:调用存储过程 MySQL:编写存储过程 方式二: Python:编写纯生SQL (可维护性好,都是开发人员写的,) MySQL: 方式三: Python:ORM->纯生SQL (开发效率高,可维护性高,用类,ORM框架) MySQL:
事务
同时成功同时失败;
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
mysql> create table user(
-> id int primary key auto_increment,
-> name char(32),
-> balance int
-> );
Query OK, 0 rows affected (1.98 sec)
mysql>
mysql> insert into user(name,balance)
-> values
-> ('wsb',1000),
-> ('egon',1000),
-> ('ysb',1000);
Query OK, 3 rows affected (0.50 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 1000 |
| 2 | egon | 1000 |
| 3 | ysb | 1000 |
+----+------+---------+
3 rows in set (0.00 sec)
#原子操作
mysql> start transaction;
Query OK, 0 rows affected (0.05 sec)
mysql> update user set balance=900 where name='wsb'; #买支付100元
Query OK, 1 row affected (0.11 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update user set balance=1010 where name='egon'; #中介拿走10元
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update user set balance=1090 where name='ysb'; #卖家拿到90元
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 900 |
| 2 | egon | 1010 |
| 3 | ysb | 1090 |
+----+------+---------+
3 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.16 sec)
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 900 |
| 2 | egon | 1010 |
| 3 | ysb | 1090 |
+----+------+---------+
3 rows in set (0.00 sec)
mysql> rollback; #出现异常就回滚到初始状态
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 900 |
| 2 | egon | 1010 |
| 3 | ysb | 1090 |
+----+------+---------+
3 rows in set (0.00 sec)
函数与流程控制
函数
一、数学函数
ROUND(x,y)
返回参数x的四舍五入的有y位小数的值
RAND()
返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
二、聚合函数(常用于GROUP BY从句的SELECT查询中)
AVG(col)返回指定列的平均值
COUNT(col)返回指定列中非NULL值的个数
MIN(col)返回指定列的最小值
MAX(col)返回指定列的最大值
SUM(col)返回指定列的所有值之和
GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果
三、字符串函数
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示
FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。
LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。
LOWER(str)
变小写
UPPER(str)
变大写
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
四、日期和时间函数
CURDATE()或CURRENT_DATE() 返回当前的日期
CURTIME()或CURRENT_TIME() 返回当前的时间
DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) 返回date是一个月的第几天(1~31)
DAYOFYEAR(date) 返回date是一年的第几天(1~366)
DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts
HOUR(time) 返回time的小时值(0~23)
MINUTE(time) 返回time的分钟值(0~59)
MONTH(date) 返回date的月份值(1~12)
MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
NOW() 返回当前的日期和时间
QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
WEEK(date) 返回日期date为一年中第几周(0~53)
YEAR(date) 返回日期date的年份(1000~9999)
重点:
DATE_FORMAT(date,format) 根据format字符串格式化date值
mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');
-> 'Sunday October 2009'
mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s');
-> '22:23:00'
mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00',
-> '%D %y %a %d %m %b %j');
-> '4th 00 Thu 04 10 Oct 277'
mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
-> '%H %k %I %r %T %S %w');
-> '22 22 10 10:23:00 PM 22:23:00 00 6'
mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');
-> '1998 52'
mysql> SELECT DATE_FORMAT('2006-06-00', '%d');
-> '00'
五、加密函数
MD5()
计算字符串str的MD5校验和
PASSWORD(str)
返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。
六、控制流函数
CASE WHEN[test1] THEN [result1]...ELSE [default] END
如果testN是真,则返回resultN,否则返回default
CASE [test] WHEN[val1] THEN [result]...ELSE [default]END
如果test和valN相等,则返回resultN,否则返回default
IF(test,t,f)
如果test是真,返回t;否则返回f
IFNULL(arg1,arg2)
如果arg1不是空,返回arg1,否则返回arg2
NULLIF(arg1,arg2)
如果arg1=arg2返回NULL;否则返回arg1
mysql> CREATE TABLE blog (
-> id INT PRIMARY KEY auto_increment,
-> NAME CHAR (32),
-> sub_time datetime
-> );
Query OK, 0 rows affected (0.78 sec)
mysql> INSERT INTO blog (NAME, sub_time)
-> VALUES
-> ('第1篇','2015-03-01 11:31:21'),
-> ('第2篇','2015-03-11 16:31:21'),
-> ('第3篇','2016-07-01 10:21:31'),
-> ('第4篇','2016-07-22 09:23:21'),
-> ('第5篇','2016-07-23 10:11:11'),
-> ('第6篇','2016-07-25 11:21:31'),
-> ('第7篇','2017-03-01 15:33:21'),
-> ('第8篇','2017-03-01 17:32:21'),
-> ('第9篇','2017-03-01 18:31:21');
Query OK, 9 rows affected (0.14 sec)
Records: 9 Duplicates: 0 Warnings: 0
mysql> SELECT DATE_FORMAT(sub_time,'%Y-%m'),COUNT(1) FROM blog GROUP BY DATE_FORMAT(sub_time,'%Y-%m');
+-------------------------------+----------+
| DATE_FORMAT(sub_time,'%Y-%m') | COUNT(1) |
+-------------------------------+----------+
| 2015-03 | 2 |
| 2016-07 | 4 |
| 2017-03 | 3 |
+-------------------------------+----------+
3 rows in set (0.22 sec)
mysql>
流程控制
delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ; if条件语句
3、索引原理
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
若索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产生影响,要找到一个平衡点,这对应用程序的性能至关重要。
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。
每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生(B+树是通过二叉查找树,再由平衡二叉树,B树演化而来)。
b+树性质 1.索引字段要尽量的小;2.索引的最左匹配特性
这种数据结构减少I/O次数
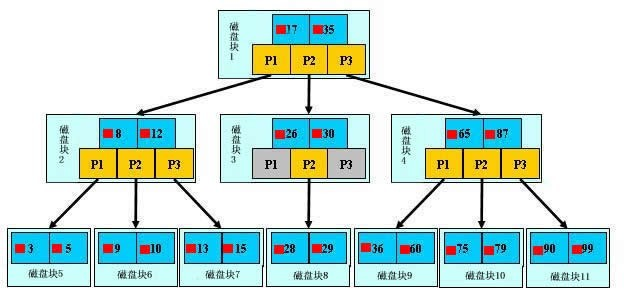
真实数据只存在叶子节点的磁盘块的数据项;树杈节点的数据象就是为了建数据结构而虚拟出的;
I/O固定在固定范围,3次,它的高度决定的。
InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放,建表的时候一定要建个主键,它会在你这个表里边找主键;
聚集索引与辅助索引
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息

- 数据库 - Navicat与pymysql模块
- xUtils工具四大功能模块:操作数据库、HTTP通信等
- 转!!sql server 数据库 索引的原理与应用
- Mysql性能优化实战:数据库锁的介绍与索引查找原理
- 【数据库管理工具】Navicat安装及使用教程
- mysq数据库管理工具navicat基本使用方法
- 一个功能强大的数据库备份、还原工具
- 如何去掉管理后台中的“支付工具、模块管理”等功能
- 数据库的索引原理
- 数据库索引的原理
- 数据库中索引原理
- 【转】数据库中索引原理
- 如何用plsql developer工具的text importer功能将外部的excel表,或txt的数据导入到数据库表
- 建立索引提高数据库查询速度的原理
- [数据库工具]Navicat
- 数据库中索引原理
- 数据库—索引实现原理
- Navicat for MySQL用ssh功能连接远程数据库
- 数据库索引原理
- 数据库中索引原理