JAVA集合笔记回顾总结(二)
2018-04-02 00:55
525 查看
List集合支持对元素的增、删、改、查。 1.添加(增): add(index, element):在指定的索引位插入元素。 addAll(index, collection):在指定的索引位插入一堆元素。 2.删除(删): remove(index):删除指定索引位的元素。 返回被删的元素。 3.获取(查): element get(index):通过索引获取指定元素。 int indexOf(element):获取指定元素第一次出现的索引位,如果该元素不存在返回—1;所以,通过—1,可以判断一个元素是否存在。 int lastIndexOf(element) :反向索引指定元素的位置。 List subList(start,end) :获取子列表。 4.修改(改): element set(index, newElement):对指定索引位进行元素的修改。 5.获取所有元素: ListIterator listIterator():list集合特有的迭代器。 在进行list列表元素迭代的时候,如果想要在迭代过程中,想要对元素进行操作的时候,比如满足条件添加新元素。会发生ConcurrentModificationException并发修改异常。 导致的原因是:集合引用和迭代器引用在同时操作元素,通过集合获取到对应的迭代器后,在迭代中,进行集合引用的元素添加,迭代器并不知道,所以会出现异常情况。ArrayList<E>类 接下来先讨论List接口的第一个重要子类:java.util.ArrayList<E>类,我这里先抛开泛型不说,本篇后面有专门阐述。但要注意,由于还没有使用泛型,利用Iterator的next()方法取出的元素必须向下转型,才可使用子类特有方法。针对ArrayList类,我们最需要注意的是,ArrayList的contains方法底层使用的equals方法判别的,所以自定义元素类型中必须复写Object的equals方法。LinkedList<E>类 java.util.LinkedList<E>类是List接口的链表实现,可以利用LinkedList实现堆栈、队列结构。它的特有方法有如下这些: addFirst(); addLast(); 在jdk1.6以后: offerFirst(); offerLast(); getFirst():获取链表中的第一个元素。如果链表为空,抛出NoSuchElementException; getLast(); 在jdk1.6以后: peekFirst();获取链表中的第一个元素。如果链表为空,返回null。 peekLast(); removeFirst():获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表为空,抛出NoSuchElementException removeLast(); 在jdk1.6以后: pollFirst();获取链表中的第一个元素,但是会删除链表中的第一个元素。如果链表
1617e
为空,返回null。 pollLast();Set<E>接口 java.util.Set<E>接口,一个不包含重复元素的 collection。更确切地讲,set 不包含满足e1.equals(e2) 的元素对e1 和e2,并且最多包含一个 null 元素。 Set:不允许重复元素。和Collection的方法相同。Set集合取出方法只有一个:迭代器。 |--HashSet:底层数据结构是哈希表(散列表)。无序,比数组查询的效率高。线程不同步的。 -->根据哈希冲突的特点,为了保证哈希表中元素的唯一性, 该容器中存储元素所属类应该复写Object类的hashCode、equals方法。 |--LinkedhashSet:有序,HashSet的子类。 |--TreeSet:底层数据结构是二叉树。可以对Set集合的元素按照指定规则进行排序。线程不同步的。 -->add方法新添加元素必须可以同容器已有元素进行比较, 所以元素所属类应该实现Comparable接口的compareTo方法,以完成排序。 或者添加Comparator比较器,实现compare方法HashSet<E>类 java.util.HashSet<E>类实现Set 接口,由哈希表(实际上是一个HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用null 元素。 堆内存的底层实现就是一种哈希表结构,需要通过哈希算法来计算对象在该结构中存储的地址。这个方法每个对象都具备,叫做hashCode()方法,隶属于java.lang.Objecct类。hashCode本身调用的是wondows系统本地的算法,也可以自己定义。 哈希表的原理: 1.对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值称为哈希值。 2.哈希值就是这个元素的位置。 3.如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。 如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。 4.存储哈希值的结构,我们称为哈希表。 5.既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。 这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。 哈希表的特点: 1.不允许存储重复元素,因为会发生查找的不确定性。 2.不保证存入和取出的顺序一致,即不保证有序。 3.比数组查询的效率高。 哈希冲突: 当哈希算法算出的两个元素的值相同时,称为哈希冲突。冲突后,需要对元素进行进一步的判断。判断的是元素的内容,equals。如果不同,还要继续计算新的位置,比如地址链接法,相当于挂一个链表扩展下来。 如何保证哈希表中元素的唯一性? 元素必须覆盖hashCode和equals方法。 覆盖hashCode方法是为了根据元素自身的特点确定哈希值。 覆盖equals方法,是为了解决哈希值的冲突。 ArrayList存储元素依赖的是equals方法。比如remove、contains底层判断用的都是equals方法。 HashSet判断元素是否相同:依据的是hashCode和equals方法。如果哈希冲突(哈希值相同),再判断元素的equals方法。如果equals方法返回true,不存;返回false,存储!TreeSet<E>类 java.util.Set<E>类基于TreeMap的NavigableSet实现。使用元素的自然顺序(Comparable的compareTo方法)对元素进行排序,或者根据创建 set 时提供的自定义比较器(Comparator的compare方法)进行排序,具体取决于使用的构造方法。此实现为基本操作(add、remove和contains)提供受保证的 log(n) 时间开销。 TreeSet:可以对元素排序。 有序:存入和取出的顺序一致。--> ListTreeSet排序方式: 需要元素自身具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。如果元素不具备比较性,在运行时会发生ClassCastException异常。 TreeSet能够进行排序。但是自定义的Person类并没有给出排序的规则。即普通的自定义类不具备排序的功能,所以要实现Comparable接口,强制让元素具备比较性,复写compareTo方法。TreeSet第一种排序方式:需要元素具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。 需求中也有这样一种情况,元素具备的比较功能不是所需要的,也就是说不想按照自然排序的方式,而是按照自定义的排序方式,对元素进行排序。而且,存储到TreeSet中的元素万一没有比较功能,该如何排序呢? 这时,就只能使用第二种排序方式--是让集合具备比较功能,定义一个比较器。联想到集合的构造函数,去查API。 TreeSet第二种排序方式:需要集合具备比较功能,定义一个比较器。所以要实现java.util.Comparator<T>接口,覆盖compare方法。将Comparator接口的对象,作为参数传递给TreeSet集合的构造函数。TreeSet集合排序有两种方式,Comparable和Comparator区别: 1.让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。 2.让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。 3.容器使用Comparator比较器接口对元素进行排序,只要实现比较器对象就可以。 -->降低了比较方式和集合之间的耦合性-->自定义比较器的方式更为灵活。 元素自身可以具备比较功能 -->自然排序通常都作为元素的默认排序。 4.Comparable接口的compareTo方法,一个参数;Comparator接口的compare方法,两个参数。 List是数组或者链表结构,允许重复元素。 HashSet是哈希表结构,查询速度快。 TreeSet是二叉树数据结构。二叉树结构可以实现排序,一堆数据只要存入二叉树,自动完成排序。ArrayList:数组结构。看到数组,就知道查询快,看到List,就知道可以重复。可以增删改查。 LinkedList:链表结构,增删快。xxxFirst、xxxLast方法,xxx:add、get、remove HashSet:哈希表,查询速度更快,就要想到唯一性、元素必须覆盖hashCode、equals。不保证有序。看到Set,就知道不可以重复。 LinkedHashSet:链表+哈希表。可以实现有序,因为有链表。但保证元素唯一性。 TreeSet:二叉树,可以排序。就要想到两种比较方式(两个接口):一种是自然排序Comparable,一种是比较器Comparator。Map<K, V>接口 java.util.Map<K,V>接口,将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。要保证键的唯一性-->Set。值可以重复-->Collection。 Map:双列集合,一次存一对,键值对。 |--Hashtable:底层是哈希表数据结构,是线程同步的,不允许存储null键,null值。 |--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。 |--HashMap:底层是哈希表数据结构,是线程不同步的,允许存储null键,null值。替代了Hashtable。 |--TreeMap:底层是二叉树结构,线程不同步的。可以对map集合中的键进行指定顺序的排序。 揭秘:HashSet、TreeSet的底层是用HashMap、TreeMap实现的,只操作键,就是Set集合。 Map集合存储和Collection有着很大不同: Collection一次存一个元素;Map一次存一对元素。 Collection是单列集合;Map是双列集合。 Map中的存储的一对元素:一个是键,一个是值,键与值之间有对应(映射)关系。 特点:要保证map集合中键的唯一性。 Map接口中的共性功能: 1.添加: v put(key, value):当存储的键相同时,新的值会替换老的值,并将老值返回。如果键没有重复,返回null。 putAll(Map<k,v> map); 2.删除: void clear():清空 v remove(key):删除指定键- -> 会改变集合长度! 3.判断: boolean containsKey(Object key):是否包含key boolean containsValue(Object value):是否包含value boolean isEmpty(); 4.取出: v get(key):通过指定键获取对应的值。如果返回null,可以判断该键不存在。 当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的。 int size():返回长度。 5.想要获取Map中的所有元素: 原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了。之所以转成set,是因为map集合具备着键的唯一性,其实set集合就来自于map,set集合底层其实用的就是map的方法。把Map集合转成Set的方法: 方式1: Set keySet(); 可以将map集合中的键都取出存放到set集合中。对set集合进行迭代。迭代完成,再通过get方法对获取到的键进行值的获取。
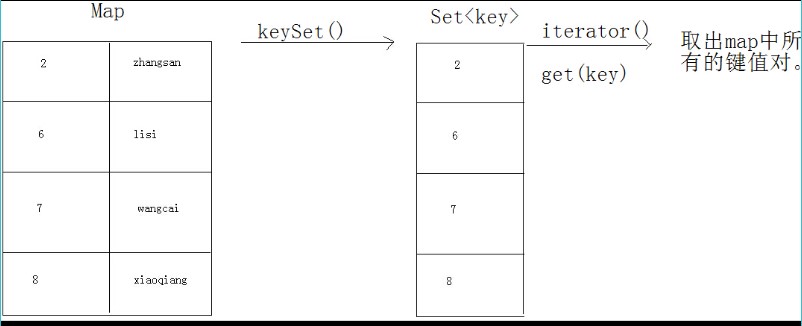
[java] view plain copySet keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()) {
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}
方式2: Set entrySet(); 取的是键和值的映射关系。Map.Entry:其实就是一个Map接口中的内部接口。为什么要定义在map内部呢?entry是访问键值关系的入口,是map的入口,访问的是map中的键值对。
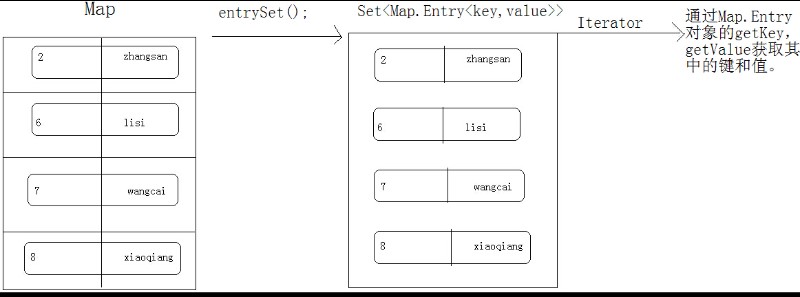
[java] view plain copySet entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
System.out.println(me.getKey()+"::::"+me.getValue());
}
Collections类 java.util.Collections类的出现给集合操作提供了更多的功能。这个类不需要创建对象,完全由在 collection 上进行操作或返回 collection 的静态方法组成。 1.对List排序: sort(list);//具备泛型限定,保证安全。 2.逆序: reverseOrder 3.最值: max min 4.二分查找: binarySearch 5.将非同步集合转成同步集合: synchronizedCollection synchronizedList SynchronizedSet synchronizedMaCollection 和 Collections的区别: Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法,实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。 Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口主要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历等。Arrays类 java.util.Arrays类是用来操作数组的工具类,里面的方法都是静态的。 Arrays类中有一个很重要的方法就是asList()方法,它返回一个受指定数组支持的固定大小的List列表。所以这里我就重点说一下,如何实现数组和集合之间的转换。 1.数组转成集合 Arrays.asList方法:将数组转换成list集合。 将数组转换成集合,有什么好处呢? 用aslist方法,将数组变成集合;可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set等方法。 注意(局限性): 数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException)。 如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。 如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。 2.集合转成数组 用的是Collection接口中的方法:toArray()。 注意: 如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。 如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。 所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
1617e
为空,返回null。 pollLast();Set<E>接口 java.util.Set<E>接口,一个不包含重复元素的 collection。更确切地讲,set 不包含满足e1.equals(e2) 的元素对e1 和e2,并且最多包含一个 null 元素。 Set:不允许重复元素。和Collection的方法相同。Set集合取出方法只有一个:迭代器。 |--HashSet:底层数据结构是哈希表(散列表)。无序,比数组查询的效率高。线程不同步的。 -->根据哈希冲突的特点,为了保证哈希表中元素的唯一性, 该容器中存储元素所属类应该复写Object类的hashCode、equals方法。 |--LinkedhashSet:有序,HashSet的子类。 |--TreeSet:底层数据结构是二叉树。可以对Set集合的元素按照指定规则进行排序。线程不同步的。 -->add方法新添加元素必须可以同容器已有元素进行比较, 所以元素所属类应该实现Comparable接口的compareTo方法,以完成排序。 或者添加Comparator比较器,实现compare方法HashSet<E>类 java.util.HashSet<E>类实现Set 接口,由哈希表(实际上是一个HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用null 元素。 堆内存的底层实现就是一种哈希表结构,需要通过哈希算法来计算对象在该结构中存储的地址。这个方法每个对象都具备,叫做hashCode()方法,隶属于java.lang.Objecct类。hashCode本身调用的是wondows系统本地的算法,也可以自己定义。 哈希表的原理: 1.对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值称为哈希值。 2.哈希值就是这个元素的位置。 3.如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。 如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。 4.存储哈希值的结构,我们称为哈希表。 5.既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。 这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。 哈希表的特点: 1.不允许存储重复元素,因为会发生查找的不确定性。 2.不保证存入和取出的顺序一致,即不保证有序。 3.比数组查询的效率高。 哈希冲突: 当哈希算法算出的两个元素的值相同时,称为哈希冲突。冲突后,需要对元素进行进一步的判断。判断的是元素的内容,equals。如果不同,还要继续计算新的位置,比如地址链接法,相当于挂一个链表扩展下来。 如何保证哈希表中元素的唯一性? 元素必须覆盖hashCode和equals方法。 覆盖hashCode方法是为了根据元素自身的特点确定哈希值。 覆盖equals方法,是为了解决哈希值的冲突。 ArrayList存储元素依赖的是equals方法。比如remove、contains底层判断用的都是equals方法。 HashSet判断元素是否相同:依据的是hashCode和equals方法。如果哈希冲突(哈希值相同),再判断元素的equals方法。如果equals方法返回true,不存;返回false,存储!TreeSet<E>类 java.util.Set<E>类基于TreeMap的NavigableSet实现。使用元素的自然顺序(Comparable的compareTo方法)对元素进行排序,或者根据创建 set 时提供的自定义比较器(Comparator的compare方法)进行排序,具体取决于使用的构造方法。此实现为基本操作(add、remove和contains)提供受保证的 log(n) 时间开销。 TreeSet:可以对元素排序。 有序:存入和取出的顺序一致。--> ListTreeSet排序方式: 需要元素自身具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。如果元素不具备比较性,在运行时会发生ClassCastException异常。 TreeSet能够进行排序。但是自定义的Person类并没有给出排序的规则。即普通的自定义类不具备排序的功能,所以要实现Comparable接口,强制让元素具备比较性,复写compareTo方法。TreeSet第一种排序方式:需要元素具备比较功能。所以元素需要实现Comparable接口。覆盖compareTo方法。 需求中也有这样一种情况,元素具备的比较功能不是所需要的,也就是说不想按照自然排序的方式,而是按照自定义的排序方式,对元素进行排序。而且,存储到TreeSet中的元素万一没有比较功能,该如何排序呢? 这时,就只能使用第二种排序方式--是让集合具备比较功能,定义一个比较器。联想到集合的构造函数,去查API。 TreeSet第二种排序方式:需要集合具备比较功能,定义一个比较器。所以要实现java.util.Comparator<T>接口,覆盖compare方法。将Comparator接口的对象,作为参数传递给TreeSet集合的构造函数。TreeSet集合排序有两种方式,Comparable和Comparator区别: 1.让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。 2.让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。 3.容器使用Comparator比较器接口对元素进行排序,只要实现比较器对象就可以。 -->降低了比较方式和集合之间的耦合性-->自定义比较器的方式更为灵活。 元素自身可以具备比较功能 -->自然排序通常都作为元素的默认排序。 4.Comparable接口的compareTo方法,一个参数;Comparator接口的compare方法,两个参数。 List是数组或者链表结构,允许重复元素。 HashSet是哈希表结构,查询速度快。 TreeSet是二叉树数据结构。二叉树结构可以实现排序,一堆数据只要存入二叉树,自动完成排序。ArrayList:数组结构。看到数组,就知道查询快,看到List,就知道可以重复。可以增删改查。 LinkedList:链表结构,增删快。xxxFirst、xxxLast方法,xxx:add、get、remove HashSet:哈希表,查询速度更快,就要想到唯一性、元素必须覆盖hashCode、equals。不保证有序。看到Set,就知道不可以重复。 LinkedHashSet:链表+哈希表。可以实现有序,因为有链表。但保证元素唯一性。 TreeSet:二叉树,可以排序。就要想到两种比较方式(两个接口):一种是自然排序Comparable,一种是比较器Comparator。Map<K, V>接口 java.util.Map<K,V>接口,将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。要保证键的唯一性-->Set。值可以重复-->Collection。 Map:双列集合,一次存一对,键值对。 |--Hashtable:底层是哈希表数据结构,是线程同步的,不允许存储null键,null值。 |--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。 |--HashMap:底层是哈希表数据结构,是线程不同步的,允许存储null键,null值。替代了Hashtable。 |--TreeMap:底层是二叉树结构,线程不同步的。可以对map集合中的键进行指定顺序的排序。 揭秘:HashSet、TreeSet的底层是用HashMap、TreeMap实现的,只操作键,就是Set集合。 Map集合存储和Collection有着很大不同: Collection一次存一个元素;Map一次存一对元素。 Collection是单列集合;Map是双列集合。 Map中的存储的一对元素:一个是键,一个是值,键与值之间有对应(映射)关系。 特点:要保证map集合中键的唯一性。 Map接口中的共性功能: 1.添加: v put(key, value):当存储的键相同时,新的值会替换老的值,并将老值返回。如果键没有重复,返回null。 putAll(Map<k,v> map); 2.删除: void clear():清空 v remove(key):删除指定键- -> 会改变集合长度! 3.判断: boolean containsKey(Object key):是否包含key boolean containsValue(Object value):是否包含value boolean isEmpty(); 4.取出: v get(key):通过指定键获取对应的值。如果返回null,可以判断该键不存在。 当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的。 int size():返回长度。 5.想要获取Map中的所有元素: 原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了。之所以转成set,是因为map集合具备着键的唯一性,其实set集合就来自于map,set集合底层其实用的就是map的方法。把Map集合转成Set的方法: 方式1: Set keySet(); 可以将map集合中的键都取出存放到set集合中。对set集合进行迭代。迭代完成,再通过get方法对获取到的键进行值的获取。
[java] view plain copySet keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()) {
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}
方式2: Set entrySet(); 取的是键和值的映射关系。Map.Entry:其实就是一个Map接口中的内部接口。为什么要定义在map内部呢?entry是访问键值关系的入口,是map的入口,访问的是map中的键值对。
[java] view plain copySet entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
System.out.println(me.getKey()+"::::"+me.getValue());
}
Collections类 java.util.Collections类的出现给集合操作提供了更多的功能。这个类不需要创建对象,完全由在 collection 上进行操作或返回 collection 的静态方法组成。 1.对List排序: sort(list);//具备泛型限定,保证安全。 2.逆序: reverseOrder 3.最值: max min 4.二分查找: binarySearch 5.将非同步集合转成同步集合: synchronizedCollection synchronizedList SynchronizedSet synchronizedMaCollection 和 Collections的区别: Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法,实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。 Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口主要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历等。Arrays类 java.util.Arrays类是用来操作数组的工具类,里面的方法都是静态的。 Arrays类中有一个很重要的方法就是asList()方法,它返回一个受指定数组支持的固定大小的List列表。所以这里我就重点说一下,如何实现数组和集合之间的转换。 1.数组转成集合 Arrays.asList方法:将数组转换成list集合。 将数组转换成集合,有什么好处呢? 用aslist方法,将数组变成集合;可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set等方法。 注意(局限性): 数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException)。 如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。 如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。 2.集合转成数组 用的是Collection接口中的方法:toArray()。 注意: 如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。 如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。 所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。

相关文章推荐
- Java集合笔记回顾总结(一)
- 黑马程序员--java 知识回顾--集合笔记
- Java基础知识强化之集合框架笔记74:各种集合常见功能 和 遍历方式总结
- Java 笔记之 ---集合总结
- Java 回顾笔记_集合框架之_linkedList_arrayList
- java学习笔记11--集合总结
- 《黑马程序员》java笔记->集合框架集合大总结
- 9.9-全栈Java笔记:遍历集合的N种方式总结&Collections工具类
- Java基础学习笔记16——(Set集合,Collection集合总结)
- Java 回顾笔记_集合框架_基本体系功能和迭代器
- Java学习笔记27(集合框架一:ArrayList回顾、Collection接口方法)
- java笔记总结_06_集合泛型
- Java常用集合总结笔记
- Java 回顾笔记_集合框架-泛型基本应用
- java笔记 集合总结
- Java高级个人笔记(java常用集合总结)
- Java笔记之集合框架Collectio与Map各个子类总结
- Java集合简单回顾总结
- Java 回顾笔记_集合框架-泛型高级应用
- 黑马程序员——Java学习笔记之11——“Collection集合”总结