编译原理(1)词法分析程序(C++实现)
2018-04-01 23:34
387 查看
这是关于编译原理的第一篇文章。
本科阶段的教学与实际操作存在一些脱节的现象。比如词法编辑器你可以完全在不知道什么nfadfa啊之类东西情况下强行摸索出来,而书上和上课讲的却是各种状态转换之类的东西。还要去背因为考试得考。这样堪称上课与书面考试是一套东西,写代码的时候可能是另一套东西。(可能老师认为代码这种东西学生自学就好)。(当然造成这种结论很有可能是本人知识有限的缘故)
介绍:构造一个自定义的小型语言的词法分析程序,程序要求能从文件输入的源程序中对输入的字符串流进行词法分析。单词种类与词法规则
1 标识符:首字符为字母或下划线,其后由字母、数字或下划线组成;
注:标识符长度不能超过20个字符。
2 无符号整数:由十进制数字组成的一个序列。首位数字不能为0;
注:无符号整数不带正负号。
③ 保留字:procedure、def、if、else、while、call、begin、end、and、or
注:保留字不区分大小写。
④ 单目运算符:+、-、 *、 /、 =、 <、>
⑤ 双目运算符:<=、 >=、 <>、 ==
⑥ 界符: ( ) ,;
⑦ 注释:单行注释和多行注释(注释语法同C语言)。
注:这个词法的规则将会继续在之后的语法等环节沿用。
环境:普通win10,c++语言 直接任意IDE编译运行即可
关于本程序的说明:解析相同目录下的code.txt文件,被分析的代码写在那个文本文件里就好。#include<iostream>
#include<fstream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cstdlib>
using namespace std;
int aa;// fseek的时候用来接着的
string word="";
string reserved_word[11];//保留
char buffer;//每次读进来的一个字符
int num=0;//每个单词中当前字符的位置
int line=1; //行数
int row=1; //列数,就是每行的第几个
bool flag; //文件是否结束了
int flag2;//单词的类型
//设置保留字
void set_reserve()
{
reserved_word[1]="procedure";
reserved_word[2]="def";
reserved_word[3]="if";
reserved_word[4]="else";
reserved_word[5]="while";
reserved_word[6]="call";
reserved_word[7]="begin";
reserved_word[8]="end";
reserved_word[9]="and";
reserved_word[10]="or";
}
//看这个字是不是字母
bool judge_word(char x)
{
if(x>='a' && x<='z' || x>='A' && x<='Z' ){
return true;
}
else return false;
}
//看这个字是不是数字
bool judge_number(char x)
{
if(x>='0' && x<='9'){
return true;
}
else return false;
}
//看这个字符是不是界符
bool judge_jiefu(char x)
{
if(x=='('||x==')'||x==','||x==';'){
return true;
}
else return false;
}
//加减乘
bool judge_yunsuanfu1(char x)
{
if(x=='+'||x=='-'||x=='*')
{
return true;
}
else return false;
}
//等于 赋值,大于小于 大于等于,小于等于,大于小于
bool judge_yunsuannfu2(char x)
{
if(x=='='|| x=='>'||x=='<'){
return true;
}
else return false;
}
//这个最大的函数的总体作用是从文件里读一个单词
int scan(FILE *fp)
{
buffer=fgetc(fp);
if(feof(fp)){
flag=0;return 0;
}
//cout<<buffer;
else if(buffer==' ')
{
row++;
return 0;
}
else if(buffer=='\n')
{
line++;
row=1;
return 0;
}
//如果是字母开头或'_' 看关键字还是普通单词
else if(judge_word(buffer) || buffer=='_')
{
word+=buffer;row++;
while((buffer=fgetc(fp)) && (judge_word(buffer) || judge_number(buffer) || buffer=='_'))
{
word+=buffer;row++;
}
if(feof(fp)){
flag=0;return 1;
}
//这个函数的意义是 因为保留字不区分大小写 要把大写字母全变成小写再比较
string temp=word;
for(int j=0;j<temp.length();j++)
{
if(temp[j]>='A' && temp[j]<='Z')
{
temp[j]+=32;
}
}
for(int i=1;i<=10;i++){
if(temp==reserved_word[i]){
aa=fseek(fp,-1,SEEK_CUR);
return 3;
}
}
aa=fseek(fp,-1,SEEK_CUR);
return 1;
}
//开始是加减乘 一定是类型4
else if(judge_yunsuanfu1(buffer))
{
word+=buffer;row++;
return 4;
}
//开始是数字就一定是数字
else if(judge_number(buffer))
{
word+=buffer;row++;
while((buffer=fgetc(fp)) && judge_number(buffer))
{
word+=buffer;row++;
}
if(feof(fp)){
flag=0;return 2;
}
aa=fseek(fp,-1,SEEK_CUR);
return 2;
}
//检验界符
else if(judge_jiefu(buffer))
{
word+=buffer;row++;
return 6;
}
//检验 <=、 >=、 <>、 == =、 <、>
else if(judge_yunsuannfu2(buffer))
{
row++;
word+=buffer;
if(buffer=='<') //为了检验题目中的<> <=
{
buffer=fgetc(fp);
if(buffer=='>' || buffer=='=')
{
word+=buffer;
row++;
return 5;
}
}
//检验 >= ==
else{
buffer=fgetc(fp);
if(buffer=='=')
{
word+=buffer;
row++;
return 5;
}
}
if(feof(fp)){
flag=0;
}
aa=fseek(fp,-1,SEEK_CUR);
return 4;
}
//首字符是/ 有可能是除号 也有可能是注释
else if(buffer=='/')
{
row++;word+=buffer;
buffer=fgetc(fp);
//这种情况是除号
if(buffer!='*' && buffer !='/')
{
aa=fseek(fp,-1,SEEK_CUR);
return 4;
}
// 这一行剩下的全被注释了
if(buffer=='/')
{
word.clear();
while((buffer=fgetc(fp)) && buffer!='\n' &&!feof(fp))
{
//真的什么也没有做
}
if(feof(fp)){
flag=0;return 0;
}
else{
aa=fseek(fp,-1,SEEK_CUR);
}
line++;row=1;
return 0;
4000
}
if(buffer=='*')
{
bool flag5=1;
while(flag5)
{
word.clear();
buffer=fgetc(fp);
row++;
if(buffer=='\n'){line++;row=1;}
if(buffer!='*')continue;
else {
buffer=fgetc(fp);
row++;if(buffer=='\n'){line++;row=1;}
if(buffer=='/'){
flag5=0;
}
else continue;
}
if(feof(fp)){flag=0;return 0;}
}
}
}
else {
word+=buffer;
row++;
return -1;
}
}
int main()
{
set_reserve();//设置保留字
cout<<"introduction"<<endl;
cout<<"open "<<"code.txt"<<endl;
cout<<"press any key"<<endl;
system("pause");
flag=1;
//ifstream a("需要解析的源代码.txt");
FILE *fp;
if(!(fp=fopen("code.txt","r")))
{
cout<<"not found the file or other error "<<endl;
flag=0;
}
while(flag==1)
{
//flag2 返回的类型
flag2=scan(fp);//反复调用函数提取单词
if(flag2==1)
{
cout<<"type:1 identifier "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
if(word.length()>20)
cout<<"ERROR Identifier length cannot exceed 20 characters"<<endl;
word.clear();
}
else if(flag2==3)
{
cout<<"type:3 reserved word "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
word.clear();
}
else if(flag2==4)
{
cout<<"type:4 unary_operator "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
else if(flag2==2)
{
cout<<"type:2 positive number "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
if(word[0]=='0')
cout<<"ERROR: The first digit cannot be 0!"<<endl;
word.clear();
}
else if(flag2==6)
{
cout<<"type:6 Separator "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
else if(flag2==5)
{
cout<<"type:6 double_operator "<<"line "<<line<<" row "<<row-2<<" "<<word<<endl;
word.clear();
}
//非法字符
else if(flag2==-1)
{
cout<<"Illegal character "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
}
int a=fclose(fp);
cout<<"press e to close"<<endl;
char end;
while(cin>>end && end!='e'){
cout<<"只有e可以关闭"<<endl;
}
return 0;
}关于代码的分析:
比较困难的地方是反而是文本文件的操作了,本人没有找到关于c++这方面的资料,直接使用了C语言的函数。
而在字符出处理方面又采用了比较省事的string类,导致代码里面c与c++杂糅的情况出现,也说不清是好还是不好了。
这个题目最有技术含量的是这个回退操作fseek(fp,-1,SEEK_CUR); 系统总体设计
设置全局变量flag=1,为了读完文本文件,主函数设置一个while(flag)死循环,无限的调用“读一个单词”的功能。
如果读单词的时候文件结束,将flag=0(这个实在都一个单词的函数中实现的,这是这个代码中最大的函数,其实读单词的时候在许多中情况下会遇到文件结束的情况)。
关键数据结构说明
(这些都是全局变量) string word 保存读到的这一个单词,int type 这个词的类型。Line row,表示当前读到的文本文件的位置,调用读单词的功能是会控制这两个变量,(每读了一个字符行就+1,读到一个换行就列+1,行=0)。
关键函数功能说明
唯一一个最关键的函数就是intscan(FILE *fp) 这个最大的函数的总体作用是从文件里读一个单词,返回值是单词类型。接下来是一些小函数,为了大函数写起来方便。
这是测试数据(被分析的文本文件的内容)
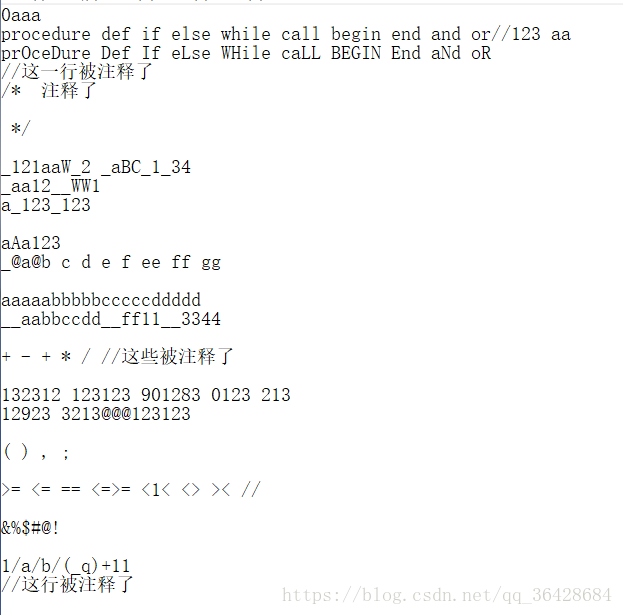

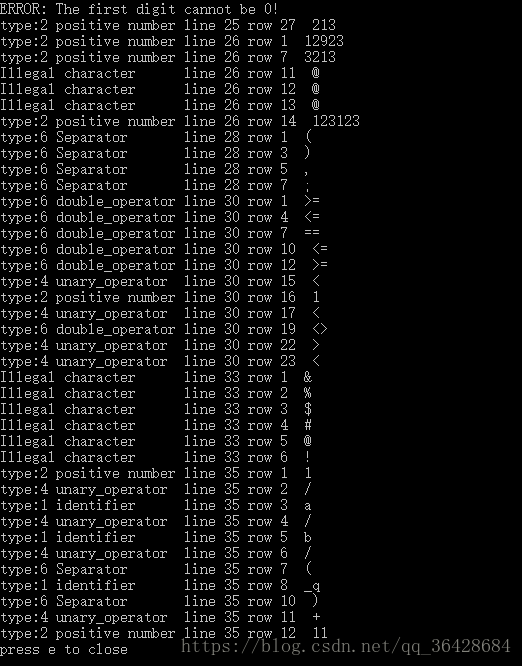
说明,实验测试数据就是一个文件,里面包含了所有种类要求的单词,并且可以提示单词的错误(数字开头是0,字符串过长,非法字符等),2种注释(单行,多行)都可以被跳过。
如图:程序的运行方法:编译之后把需要分析的代码写在同目录下的code.txt里面,运行exe就可以。

这篇文章到这里了,本人认为本次最关键这行代码代表的“回退一个字符”的过程了,剩下的大量代码全是体力劳动。fseek(fp,-1,SEEK_CUR);之后还会有语法和中间代码生成等,正在重新敲代码和整理(或者说学也行)中。本篇文章到这里结束谢谢。
本科阶段的教学与实际操作存在一些脱节的现象。比如词法编辑器你可以完全在不知道什么nfadfa啊之类东西情况下强行摸索出来,而书上和上课讲的却是各种状态转换之类的东西。还要去背因为考试得考。这样堪称上课与书面考试是一套东西,写代码的时候可能是另一套东西。(可能老师认为代码这种东西学生自学就好)。(当然造成这种结论很有可能是本人知识有限的缘故)
介绍:构造一个自定义的小型语言的词法分析程序,程序要求能从文件输入的源程序中对输入的字符串流进行词法分析。单词种类与词法规则
1 标识符:首字符为字母或下划线,其后由字母、数字或下划线组成;
注:标识符长度不能超过20个字符。
2 无符号整数:由十进制数字组成的一个序列。首位数字不能为0;
注:无符号整数不带正负号。
③ 保留字:procedure、def、if、else、while、call、begin、end、and、or
注:保留字不区分大小写。
④ 单目运算符:+、-、 *、 /、 =、 <、>
⑤ 双目运算符:<=、 >=、 <>、 ==
⑥ 界符: ( ) ,;
⑦ 注释:单行注释和多行注释(注释语法同C语言)。
注:这个词法的规则将会继续在之后的语法等环节沿用。
环境:普通win10,c++语言 直接任意IDE编译运行即可
关于本程序的说明:解析相同目录下的code.txt文件,被分析的代码写在那个文本文件里就好。#include<iostream>
#include<fstream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cstdlib>
using namespace std;
int aa;// fseek的时候用来接着的
string word="";
string reserved_word[11];//保留
char buffer;//每次读进来的一个字符
int num=0;//每个单词中当前字符的位置
int line=1; //行数
int row=1; //列数,就是每行的第几个
bool flag; //文件是否结束了
int flag2;//单词的类型
//设置保留字
void set_reserve()
{
reserved_word[1]="procedure";
reserved_word[2]="def";
reserved_word[3]="if";
reserved_word[4]="else";
reserved_word[5]="while";
reserved_word[6]="call";
reserved_word[7]="begin";
reserved_word[8]="end";
reserved_word[9]="and";
reserved_word[10]="or";
}
//看这个字是不是字母
bool judge_word(char x)
{
if(x>='a' && x<='z' || x>='A' && x<='Z' ){
return true;
}
else return false;
}
//看这个字是不是数字
bool judge_number(char x)
{
if(x>='0' && x<='9'){
return true;
}
else return false;
}
//看这个字符是不是界符
bool judge_jiefu(char x)
{
if(x=='('||x==')'||x==','||x==';'){
return true;
}
else return false;
}
//加减乘
bool judge_yunsuanfu1(char x)
{
if(x=='+'||x=='-'||x=='*')
{
return true;
}
else return false;
}
//等于 赋值,大于小于 大于等于,小于等于,大于小于
bool judge_yunsuannfu2(char x)
{
if(x=='='|| x=='>'||x=='<'){
return true;
}
else return false;
}
//这个最大的函数的总体作用是从文件里读一个单词
int scan(FILE *fp)
{
buffer=fgetc(fp);
if(feof(fp)){
flag=0;return 0;
}
//cout<<buffer;
else if(buffer==' ')
{
row++;
return 0;
}
else if(buffer=='\n')
{
line++;
row=1;
return 0;
}
//如果是字母开头或'_' 看关键字还是普通单词
else if(judge_word(buffer) || buffer=='_')
{
word+=buffer;row++;
while((buffer=fgetc(fp)) && (judge_word(buffer) || judge_number(buffer) || buffer=='_'))
{
word+=buffer;row++;
}
if(feof(fp)){
flag=0;return 1;
}
//这个函数的意义是 因为保留字不区分大小写 要把大写字母全变成小写再比较
string temp=word;
for(int j=0;j<temp.length();j++)
{
if(temp[j]>='A' && temp[j]<='Z')
{
temp[j]+=32;
}
}
for(int i=1;i<=10;i++){
if(temp==reserved_word[i]){
aa=fseek(fp,-1,SEEK_CUR);
return 3;
}
}
aa=fseek(fp,-1,SEEK_CUR);
return 1;
}
//开始是加减乘 一定是类型4
else if(judge_yunsuanfu1(buffer))
{
word+=buffer;row++;
return 4;
}
//开始是数字就一定是数字
else if(judge_number(buffer))
{
word+=buffer;row++;
while((buffer=fgetc(fp)) && judge_number(buffer))
{
word+=buffer;row++;
}
if(feof(fp)){
flag=0;return 2;
}
aa=fseek(fp,-1,SEEK_CUR);
return 2;
}
//检验界符
else if(judge_jiefu(buffer))
{
word+=buffer;row++;
return 6;
}
//检验 <=、 >=、 <>、 == =、 <、>
else if(judge_yunsuannfu2(buffer))
{
row++;
word+=buffer;
if(buffer=='<') //为了检验题目中的<> <=
{
buffer=fgetc(fp);
if(buffer=='>' || buffer=='=')
{
word+=buffer;
row++;
return 5;
}
}
//检验 >= ==
else{
buffer=fgetc(fp);
if(buffer=='=')
{
word+=buffer;
row++;
return 5;
}
}
if(feof(fp)){
flag=0;
}
aa=fseek(fp,-1,SEEK_CUR);
return 4;
}
//首字符是/ 有可能是除号 也有可能是注释
else if(buffer=='/')
{
row++;word+=buffer;
buffer=fgetc(fp);
//这种情况是除号
if(buffer!='*' && buffer !='/')
{
aa=fseek(fp,-1,SEEK_CUR);
return 4;
}
// 这一行剩下的全被注释了
if(buffer=='/')
{
word.clear();
while((buffer=fgetc(fp)) && buffer!='\n' &&!feof(fp))
{
//真的什么也没有做
}
if(feof(fp)){
flag=0;return 0;
}
else{
aa=fseek(fp,-1,SEEK_CUR);
}
line++;row=1;
return 0;
4000
}
if(buffer=='*')
{
bool flag5=1;
while(flag5)
{
word.clear();
buffer=fgetc(fp);
row++;
if(buffer=='\n'){line++;row=1;}
if(buffer!='*')continue;
else {
buffer=fgetc(fp);
row++;if(buffer=='\n'){line++;row=1;}
if(buffer=='/'){
flag5=0;
}
else continue;
}
if(feof(fp)){flag=0;return 0;}
}
}
}
else {
word+=buffer;
row++;
return -1;
}
}
int main()
{
set_reserve();//设置保留字
cout<<"introduction"<<endl;
cout<<"open "<<"code.txt"<<endl;
cout<<"press any key"<<endl;
system("pause");
flag=1;
//ifstream a("需要解析的源代码.txt");
FILE *fp;
if(!(fp=fopen("code.txt","r")))
{
cout<<"not found the file or other error "<<endl;
flag=0;
}
while(flag==1)
{
//flag2 返回的类型
flag2=scan(fp);//反复调用函数提取单词
if(flag2==1)
{
cout<<"type:1 identifier "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
if(word.length()>20)
cout<<"ERROR Identifier length cannot exceed 20 characters"<<endl;
word.clear();
}
else if(flag2==3)
{
cout<<"type:3 reserved word "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
word.clear();
}
else if(flag2==4)
{
cout<<"type:4 unary_operator "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
else if(flag2==2)
{
cout<<"type:2 positive number "<<"line "<<line<<" row "<<row-word.length()<<" "<<word<<endl;
if(word[0]=='0')
cout<<"ERROR: The first digit cannot be 0!"<<endl;
word.clear();
}
else if(flag2==6)
{
cout<<"type:6 Separator "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
else if(flag2==5)
{
cout<<"type:6 double_operator "<<"line "<<line<<" row "<<row-2<<" "<<word<<endl;
word.clear();
}
//非法字符
else if(flag2==-1)
{
cout<<"Illegal character "<<"line "<<line<<" row "<<row-1<<" "<<word<<endl;
word.clear();
}
}
int a=fclose(fp);
cout<<"press e to close"<<endl;
char end;
while(cin>>end && end!='e'){
cout<<"只有e可以关闭"<<endl;
}
return 0;
}关于代码的分析:
比较困难的地方是反而是文本文件的操作了,本人没有找到关于c++这方面的资料,直接使用了C语言的函数。
而在字符出处理方面又采用了比较省事的string类,导致代码里面c与c++杂糅的情况出现,也说不清是好还是不好了。
这个题目最有技术含量的是这个回退操作fseek(fp,-1,SEEK_CUR); 系统总体设计
设置全局变量flag=1,为了读完文本文件,主函数设置一个while(flag)死循环,无限的调用“读一个单词”的功能。
如果读单词的时候文件结束,将flag=0(这个实在都一个单词的函数中实现的,这是这个代码中最大的函数,其实读单词的时候在许多中情况下会遇到文件结束的情况)。
关键数据结构说明
(这些都是全局变量) string word 保存读到的这一个单词,int type 这个词的类型。Line row,表示当前读到的文本文件的位置,调用读单词的功能是会控制这两个变量,(每读了一个字符行就+1,读到一个换行就列+1,行=0)。
关键函数功能说明
唯一一个最关键的函数就是intscan(FILE *fp) 这个最大的函数的总体作用是从文件里读一个单词,返回值是单词类型。接下来是一些小函数,为了大函数写起来方便。
这是测试数据(被分析的文本文件的内容)
说明,实验测试数据就是一个文件,里面包含了所有种类要求的单词,并且可以提示单词的错误(数字开头是0,字符串过长,非法字符等),2种注释(单行,多行)都可以被跳过。
如图:程序的运行方法:编译之后把需要分析的代码写在同目录下的code.txt里面,运行exe就可以。
这篇文章到这里了,本人认为本次最关键这行代码代表的“回退一个字符”的过程了,剩下的大量代码全是体力劳动。fseek(fp,-1,SEEK_CUR);之后还会有语法和中间代码生成等,正在重新敲代码和整理(或者说学也行)中。本篇文章到这里结束谢谢。

相关文章推荐
- 编译原理(六) LL(1)文法分析法(分析过程的C++实现)
- 编译原理(七) 算符优先分析法(构造算符优先关系表算法及C++实现)
- 编译原理(六) LL(1)文法分析法(分析过程的C++实现)
- 编译原理(七) 算符优先分析法(构造算符优先关系表算法及C++实现)
- 编译原理(七) 算符优先分析法(构造算符优先关系表算法及C++实现)
- 设计有穷自动机DFA实现C++简单程序的词法分析、扫描(编译原理实验) 推荐
- 编译原理(八) 算符优先分析法(分析过程的算法和C++实现)
- C++函数重载实现的原理以及为什么在C++中调用C语言编译的函数时要加上extern "C"声明
- 编译原理--C-Minus词法分析器C++实现
- C++函数编译原理和成员函数的实现
- 编译原理(八) 算符优先分析法(分析过程的算法和C++实现)
- 编译原理(九) LR(0)文法分析法(算法描述和C++代码实现)
- 编译原理:第七节 及词法分析器的C++和Python实现
- 编译原理(十) SLR文法分析法(算法原理和C++实现)
- 编译原理——Tiny词法分析器c++实现
- C++实现编译原理的词法分析器
- 编译原理(二) NFA的确定化及DFA的最小化的算法及C++实现
- 编译原理LR分析法c++实现
- C++函数编译原理和成员函数的实现
- 编译原理:文法类型判断C++实现