django models 模型 从入门到进阶
2018-03-29 11:55
453 查看
Model 进阶学习
简介
Django经常被用于一些创业团队,乃是因为其非常适合敏捷开发,开发效率非常之高。Model 作为Django重要组成部分也是亮点之一,着实需要我们花时间好好梳理一遍。 ORM需要好好学习一下,运用得当可以大大的提升代码的简洁性。Django的model模块,遵循了DRY(don’t repeat yourself)原则,也会使得代码更加容易维护,只需修改一次,肯定会大大提高程序的健壮性以及可维护性。
而且ORM也使得该框架更加灵活且松解耦。例如有些码农不喜欢django的模版,更偏爱其他的模版渲染引擎。django视图方法并未强制一定要使用自身的模版引擎,你一可以尝试实用jinjia2等等。同时ORM屏蔽了底层数据库的语法,你可以运行非常多的数据库类型(mysql,mongo?don’t care,改一下engine配置即可),当然性能肯定会降低一些,毕竟多封装了一层。
一路走来,踩过无数的大坑,发现网上很多网友的博文是误导性的,所以想在这里写一片文章梳理一下model的全貌,以备复习,也供给大家一个参考,如果发现错误希望可以帮忙指正,谢谢。
本文结构:
model常用字段定义model的初级用法
model的高级用法
model的一些坑
1.model常用字段定义
V=models.CharField(max_length=None[, **options]) #varchar V=models.EmailField([max_length=75, **options]) #varchar V=models.URLField([verify_exists=True, max_length=200, **options]) #varchar V=models.FileField(upload_to=None[, max_length=100, **options]) #varchar #upload_to指定保存目录可带格式, V=models.ImageField(upload_to=None[, height_field=None, width_field=None, max_length=100, **options]) V=models.IPAddressField([**options]) #varchar V=models.FilePathField(path=None[, match=None, recursive=False, max_length=100, **options]) #varchar V=models.SlugField([max_length=50, **options]) #varchar,标签,内含索引 V=models.CommaSeparatedIntegerField(max_length=None[, **options]) #varchar V=models.IntegerField([**options]) #int V=models.PositiveIntegerField([**options]) #int 正整数 V=models.SmallIntegerField([**options]) #smallint V=models.PositiveSmallIntegerField([**options]) #smallint 正整数 V=models.AutoField(**options) #int;在Django代码内是自增 V=models.DecimalField(max_digits=None, decimal_places=None[, **options]) #decimal V=models.FloatField([**options]) #real V=models.BooleanField(**options) #boolean或bit V=models.NullBooleanField([**options]) #bit字段上可以设置上null值 V=models.DateField([auto_now=False, auto_now_add=False, **options]) #date #auto_now最后修改记录的日期;auto_now_add添加记录的日期 V=models.DateTimeField([auto_now=False, auto_now_add=False, **options]) #datetime V=models.TimeField([auto_now=False, auto_now_add=False, **options]) #time V=models.TextField([**options]) #text V=models.XMLField(schema_path=None[, **options]) #text ——————————————————————————– V=models.ForeignKey(othermodel[, **options]) #外键,关联其它模型,创建关联索引 V=models.ManyToManyField(othermodel[, **options]) #多对多,关联其它模型,创建关联表 V=models.OneToOneField(othermodel[, parent_link=False, **options]) #一对一,字段关联表属性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2.model初级用法
首先我们拿官网的例子作为示范,这个例子非常的经典,被用在django book以及其他很多相关的书籍当中。 我们首先假定如下的概念:
一个作者有姓,名,email地址。
出版商有名称,地址,所在的city,province,country,website.
书籍有书名和出版日期。它有一个或者多个作者[many-2-many]。但是只有一个出版商([one 2 many]),被称为外键[foreign key]。
在models.py中添加如下内容:
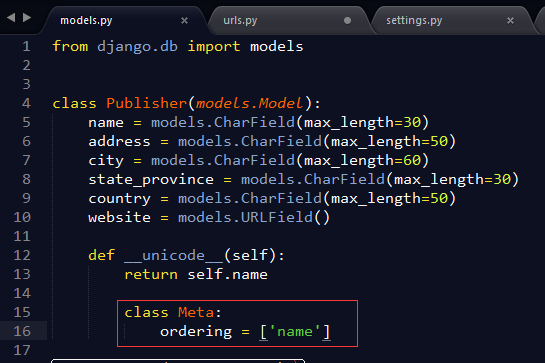
from django.db import models class Publisher(models.Model): name = models.CharField(max_length=30) address = models.CharField(max_length=50) city = models.CharField(max_length=60) state_province = models.CharField(max_length=30) country = models.CharField(max_length=50) website = models.URLField() def __unicode__(self): return self.name class Author(models.Model): first_name = models.CharField(max_length=30) last_name = models.CharField(max_length=40) email = models.EmailField() def __unicode__(self): return u'%s %s' % (self.first_name, self.last_name) class Book(models.Model): title = models.CharField(max_length=100) authors = models.ManyToManyField(Author) publisher = models.ForeignKey(Publisher) publication_date = models.DateField() def __unicode__(self): return self.title1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
并且记得在配置里面加入app model注册,
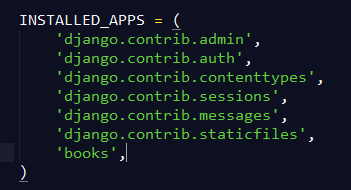
之后可以用
python manage.py validate校验模型的正确性。
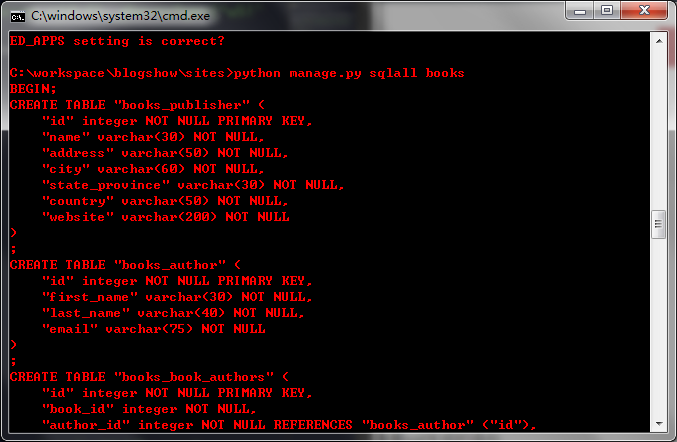
也可以用
python mange.py sqlall books来查看sql生成的语句。
后面还需要执行
python manage.py syncdb
基本的添加数据

基本的选择对象

获取全体对象:
Publisher.objects.all()可以用来获取所有的对象.
筛选部分对象:
Publisher.objects.filter(name='Apress')可以用来筛选所有name是Apress的publisher.(获取的是一个对象列表)
获取单个对象
Publisher.objects.get(name='Apress')
获取一个名字是Apress的开发商(只获取单个对象)。 filter的条件会在高级部分列出。
排序:
publisher.objects.order_by("state_province","-address").这句代码几乎囊括了排序的精华:).我们可以看到是多字段排序,同时,address前面有一个-代表的是逆排序。
当然,一般情况下,只需要按照某个字段进行排序,这种情况下可以指定模型的缺省排序方式:
连查:
除了单个查询,我们还可以用下面这种方式来查询
Publisher.objects.filter(name='xxoo').order_by('-name')[0] 这段程序并不会执行两次,而是最后转化为一句sql语句来执行(考虑的太周到).
更新多个对象:
我们知道,之前我们用p.save()来更新对象,如果涉及到很多条数据需要一次性更新,这个时候该如何呢?Django也考虑到了这一点,可以用如下的方式来更新:
Publisher.objects.all().update(country='China'),一次性将所有的Publisher的国家更新为china。
删除对象:
前面讲了添加、更新,这里补充一下删除,删除主要是筛选出对象后执行
delete()方法.
Publisher.objects.filter(country='USA').delete()
3.model的高级用法
访问外键
>>>b=Book.objects.get(id=1) >>>b=p.publisher <publisher:Apress Publishing> >>>b.publisher.website u'http://www.xuancan.net.cn'1
2
3
4
5
6
对于Foreignkey 来说,关系的另外一端,也可以追溯回来,不过由于不是对称关系,所以有一些区别,获得的是一个list,而非单一对象:
>>>p=Publisher.objects.get(name="Apress Publishing") >>>p.book_set.all() [<Book:The Chinese english>,<Book:the good good study>,...]1
2
3
访问多对多值
多对多和外键工作方式类似,不过我们处理的是QuerySet而非模型实例。例如,查看书籍的作者:>>>b = Book.objects.get(id=1) >>>b.authors.all() [<Author:liushuchun>,<Author:nobb>] >>>b.authors.filter(fisrt_name="liushuchun") [<Author:liushuchun>]1
2
3
4
5
我们可以看到这就是类似objects来用了。
更改数据库结构
Django有一个不完善的地方是,一旦model确定下来后,再想通过命令来更新是无法更新的,会报错,这个时候就要学会用手动的方式更改数据库结构。 具体的过程:
1. 先在models.py文件中,找到你要添加字段的模型,添加(也可以是删除修改,只是sql语句有一些区别)上该字段,如下所示(抱歉,截图多了个等号)
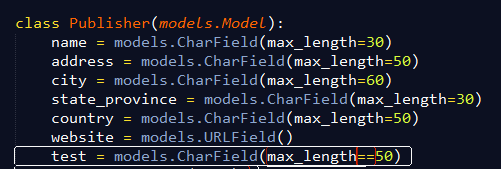
2. 在
cmd下,通过cd命令进入应用目录,也就是manage.py文件所在的目录
3. 然后使用python manage.py sqlall[app_name]命令,打印出app中包括的所有模型的sql语言表示
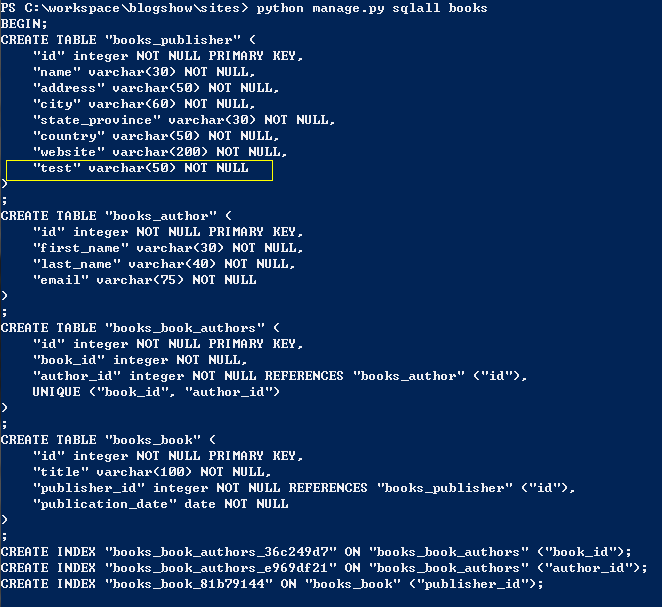
3. 找到你想要添加字段的表,找到你已经添加过的字段test,记下sql语句
4. 进入 manage.py shell 创建一个cursor实例,用于执行sql语句

5. 执行该sql语句,看好了,这个sql语句是刚才我让你记下的sql语句,执行这个命令就可以完成向数据库添加字段.

6. 最后,我们要验证添加字段是否成功,仍然在manage.py shell中,通过调用模型来检查是否成功。
这里我们只说了添加字段,其他删除或者修改字段类似。
manager管理器添加自定义方法
管理器是Django查询数据库时会使用到的一个特别的对象,在Book.objects.all()语法中,objects就是管理器,在django中,每一个model至少有一个管理器,而且,你也可以创建自己的管理器来自定义你的数据库访问操作。一方面可以增加额外的管理器方法,另一方面可以根据你的需求来修改管理器返回的QuerySet。 这是一种”表级别”的操作,下面我们给之前的Book类增加一个方法title_count(),它根据关键字,
返回标题中包括这个关键字的书的个数。
class BookManager(models.Manager): def title_count(self, keyword): return self.filter(title__icontains=keyword).count() class Book(models.Model): title = models.CharField(max_length=100) authors = models.ManyToManyField(Author) publisher = models.ForeignKey(Publisher) publication_date = models.DateField() num_pages = models.IntegerField(blank=True, null=True) #可以直接赋值替换掉默认的objects管理器,也可以定义一个新的管理器变量 #调用时,直接使用这个新变量就可以了,一旦定义了新的管理器,默认管理器 #需要显示声明出来才可以使用 # objects = models.Manger() objects = BookManager() def __unicode__(self): return self.title1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
结果为:
>>>Book.objects.title_count('python')
212
上面的代码可以看到,创建自定义的Manager的步骤:
1. 继承models.Manager,定义新的管理器方法,在方法中使用self,也就是manager本身来
进行操作
2. 把自定义的管理器对象赋值给objects属性来代替默认的管理器。
那为什么不直接创建个title_count函数来实现这个功能呢?
因为创建管理器类,可以更好地进行封装功能和重用代码。
修改返回的QuerySet
Book.objects.all()返回的是所有记录对象,可以重写Manager.get_query_set()方法,它返回的是你自定义的QuerySet,你之后的filter,slice等操作都是基于这个自定义的QuerySet。from django.db import models class RogerBookManager(models.Manager): def get_query_set(self): #调用父类的方法,在原来返回的QuerySet的基础上返回新的QuerySet return super(RogerBookManager, self).get_query_set().filter(title__icontains='python') class Book(models.Model): title = models.CharField(max_length=100) author = models.CharField(max_length=50) #objects默认管理器需要显示声明,才能使用 objects = models.Manager() # 默认的管理器 roger_objects = RogerBookManager() # 自定义的管理器,用新变量1
2
3
4
5
6
7
8
9
10
11
12
13
14
结果为:
>>>Book.objects.all() [<Book:Coplier Theroy>,<Book:python>,...] >>>Book.roger_objects.all() [<Book:Python Tutorial>,<Book:Python tools>]1
2
3
4
你可以为model定义多个不同的管理器来返回不同的QuerySet,不过要注意一点的是Django
会把你第一个定义的管理器当作是默认的管理器,也就是代码行中最上面定义的管理器。Django
有些其它的功能会使用到默认的管理器,为了能让它正常的工作,一种比较好的做法就是把原始默认
的管理器放在第一个定义。
Model添加方法(这部分是抄书)
和管理器的”表级别”操作相比,model的方法更像是”记录级别”的操作,不过,model的主要设计是用来 用”表级别”操作的,”记录级别”的操作往往是用来表示记录的状态的,是那些没有放在数据库表中,但是也
有意义的数据。举例说明:
from django.db import models class Person(models.Model): first_name = models.CharField(max_length=50) last_name = models.CharField(max_length=50) birth_date = models.DateField() address = models.CharField(max_length=100) city = models.CharField(max_length=50) # 用来判读是否在baby boomer出生,可以不用放在数据库表中 def baby_boomer_status(self): "Returns the person's baby-boomer status." import datetime if datetime.date(1945, 8, 1) <= self.birth_date <= datetime.date(1964, 12, 31): return "Baby boomer" if self.birth_date < datetime.date(1945, 8, 1): return "Pre-boomer" return "Post-boomer" # 用来返回全名,这个可以不被插入到数据库表中 def get_full_name(self): "Returns the person's full name." return u'%s %s' % (self.first_name, self.last_name)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
运行结果:
>>> p = Person.objects.get(first_name='Barack', last_name='Obama') >>> p.birth_date datetime.date(1961, 8, 4) >>> p.baby_boomer_status() 'Baby boomer' >>> p.get_full_name() u'Barack Obama'1
2
3
4
5
6
7
执行自定义SQL语句
如果你想执行自定义的SQL语句查询,可以使用django.db.connection对象: 可以使用SQL对数据库中所有的表进行操作,而不用引用特定的model类。
需要注意的是execute()函数使用的SQL语句需要使用到%s这样的格式符,而
不是直接写在里面。
这样的操作比较自由,比较好的做法是把它放在自定义管理器中:
from django.db import connection, models
class PythonBookManager(models.Manager):
def books_titles_after_publication(self, date_string):
cursor = connection.cursor()
cursor.execute("""
SELECT title
FROM books_book
WHERE publication_date > %s""", [date_string])
#fetchall()返回的是元组的列表
return [row[0] for row in cursor.fetchall()]
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField(blank=True, null=True)
num_pages = models.IntegerField(blank=True, null=True)
objects = models.Manager()
python_objects = PythonBookManager()12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
一些django奇技淫巧
还在搜集中,后面会加上.1
2
一些过滤字段方法
1.多表连接查询:当我知道这点的时候顿时觉得django太NX了。class A(models.Model): name = models.CharField(u'名称') class B(models.Model): aa = models.ForeignKey(A) B.objects.filter(aa__name__contains='searchtitle')1
2
3
4
5
1.5 我叫它反向查询,后来插入记录1.5,当我知道的时候瞬间就觉得django太太太NX了。
class A(models.Model): name = models.CharField(u'名称') class B(models.Model): aa = models.ForeignKey(A,related_name="FAN") bb = models.CharField(u'名称')
查A: A.objects.filter(FAN=’XXXX’),都知道related_name的作用,A.FAN.all()是一组以A为外键的B实例,可前面这样的用法是查询出所有(B.aa=A且B.bb=XXXX)的A实例,然后还可以通过__各种关系查找,真赤激!!!
**2.条件选取querySet的时候,filter表示=,exclude表示!=querySet.distinct() 去重复
__exact 精确等于 like 'aaa' __iexact 精确等于 忽略大小写 ilike 'aaa' __contains 包含 like '%aaa%' __icontains 包含 忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。 __gt 大于 __gte 大于等于 __lt 小于 __lte 小于等于 __in 存在于一个list范围内 __startswith 以...开头 __istartswith 以...开头 忽略大小写 __endswith 以...结尾 __iendswith 以...结尾,忽略大小写 __range 在...范围内 __year 日期字段的年份 __month 日期字段的月份 __day 日期字段的日 __isnull=True/False1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
>> q1 = Entry.objects.filter(headline__startswith="What") >> q2 = q1.exclude(pub_date__gte=datetime.date.today()) >> q3 = q1.filter(pub_date__gte=datetime.date.today()) >>> q = q.filter(pub_date__lte=datetime.date.today()) >>> q = q.exclude(body_text__icontains="food")1
2
3
4
5
即q1.filter(pub_date__gte=datetime.date.today())表示为时间>=now,q1.exclude(pub_date__gte=datetime.date.today())表示为<=now
关于缓存:
queryset是有缓存的,a = A.objects.all(),print [i for i in a].第一次执行打印会查询数据库,然后结果会被保存在queryset内置的cache中,再执行print的时候就会取自缓存。
DJANGO or 查询
Q查询——对对象的复杂查询 F查询——专门取对象中某列值的操作
Q查询
1、Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询,例如:
from django.db.models import Q from login.models import New #models对象 news=New.objects.filter(Q(question__startswith='What'))1
2
3
4
2、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
Q(question__startswith='Who') | Q(question__startswith='What')1
3、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合
Q(question__startswith='Who') | ~Q(pub_date__year=2005)1
4、应用范围
Poll.objects.get( Q(question__startswith='Who'), Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)) )1
2
3
4
等价于
SELECT * from polls WHERE question LIKE 'Who%' AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')1
2
5、Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
正确: Poll.objects.get( Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)), question__startswith='Who') 错误: Poll.objects.get( question__startswith='Who', Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))1
2
3
4
5
6
7
8
9
10
Done!有一些粗略,但是大概能用的上的,几乎都在这里了。

相关文章推荐
- Django入门-5:模型的基本使用5-QuerySet API讲解
- Django 模型系统(model)&ORM--进阶
- RabbitMQ3.7.2入门到进阶之Topic主题模型
- Django进阶——模型的高级用法
- models.py---Django中的数据库模型
- Django学习2--创建应用程序、models模型管理、系统管理后台
- Django 根据数据模型models创建数据表的实例
- Django中models.py(添加管理类模型)
- Python Django进阶教程(三)(模型的高级用法)
- 第一章:模型层model layer -- Django从入门到精通系列教程
- 模型的继承 -- Django从入门到精通系列教程
- django models 模型
- Crushe Django 入门笔记4 使用模型
- 模型和字段 -- Django从入门到精通系列教程
- 【Python】django模型models的外键关联使用
- Robotlegs AS3入门介绍 第二部分:Models(模型)
- Django(5)模型models定义详解
- Django中的模型与数据库(Models and database)
- Django 2.0 之Models(模型) 官方文档翻译(一)
- django 模型 models详解