5、神经网络是如何给出预测结果的?
2018-03-29 09:57
615 查看
本文属于学习笔记,依据(微信公众号:jack床长)的文章整理博客链接:http://blog.csdn.net/jiangjunshow
本章给大家介绍一种用于预测的算法——逻辑回归(logistic regression)

给定一个输入特征向量x(例如你想要识别的图像——是否有猫),你需要一个算法进行计算之后进行结果输出(在这里我们用的是逻辑回归算法)。这个被输出的预测结果我们称为y^y^,假设y是1,如果预测得很准的话y^y^可能会是0.99)。
上图第一个公式中的x是个(n,1)维的矩阵,表示一个训练样本,里面的n表示一个训练样本中的特征数量,例如一张图片就是一个训练样本,图片中每个颜色强度值就是一个特征;w也是一个(n,1)维的矩阵,它表示权重(weight),它一一对应于每个输入的特征,也可以说它指示了某个特征的重要程度;b是一个实数,在这里可以将其看作为一个阀值。
如何理解w和b呢?我举个例子来帮助大家理解。可以把上面的算法过程看作是一种通过权衡输入然后再做出决定的一个过程。假设周末即将到来,你听说在你的城市将会有一个音乐节。你要决定是否去参加这个节日。你需要通过权衡3个因素(3个特征)来做出决定:1、天气好吗 2、你的女友是否愿意陪你去 3、举办地点离地铁近吗 这3个因素就对应着上图中的x1、x2,x3(它们是x这个训练样本中的3个特征)。我们可以给它们赋个值,如果天气好,那么x1为1,否则为0,x2和x3雷同;假设你很讨厌坏天气,如果天气不好,你就不会去参加这个节日,对其它两个因素要求不高(这里假设你是个老司机,女人多得是,不怕冷落了女友)。那么我们分别给3个权重赋值为7,2,2。w1的值大很多,这表明天气对你来说很重要,比你的女友是否愿意去,以及交通的便利性更重要。而b我们可以看作一个阀值,假设我们给b赋值为-5,那么也就是说,只要天气好,即使女友不陪你去、交通也不方便,你也会去参加这个节日——x1 * w1 + x2 * w2 + x3 * w3 = 1 * 7 + 0 * 2 + 0 * 2 = 7(这里的*代表乘法)(我们这里先不考虑σ函数),而7 +(-5)> 0,结果是你会去那个音乐节。如果我们选择不同的w和b值,那么对于同一个输入x,会有不同的结果输出。
训练神经网络的目的就是通过训练过程来得到这些w和b值(后面会教大家如何来训练得到它们)。这些w和b值可以让神经网络得到一项判断能力,一项预测能力——输入一张图片,神经网络根据训练好的w和b,通过上面的公式根据每个像素的值以及与其对应的权重值以及阈值来判定这张图里是否有猫。神经网络就是这样来进行预测的。它和我们人类的思考方式是一样的。虽然我们人可以做出非常复杂的判断,但是基本原理是很简单的。人为什么能轻松分辨出一个图片中是否有猫?因为我们人就是一个巨型的神经网络,这个神经网络里面包含了数亿甚至更多的神经元(上图蓝色的圆圈就表示一个神经元),每个神经元都可以接受多个输入,在日常生活中,小孩子通过大人的教导,不断的看见猫,我们的神经元对于这个输入就形成了很多特定的w(权重),所以当再次看见一个猫时,这个输入(这个猫)与相应的w联合起来进行运算后,其结果就指示了这个输入是一个猫。
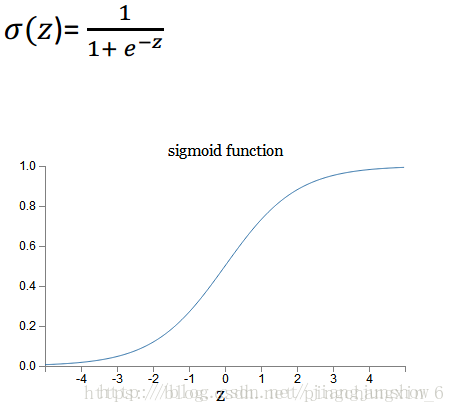
下面再来说一下σ,它代表了sigmoid函数,上面是它的定义公式以及图形。我们为什么需要它?在上面我们举的去参加节日的例子中,我们得出的结果为2,其实对于不同的x和w值,结果可能会更大。所以这并不适用于二元分类问题,因为在二元分类问题中你想要得到的y^y^应该表示一个概率,一个输入是否等于它真实标签的概率(例如输入的图像里面是否有猫)。所以y^y^的值应该在0和1之间。sigmoid函数的作用就是把计算结果转换为0和1之间的值。通过看它的图形就可以明白,往sigmoid函数里输入的值z越大,那么y^y^就越靠近1,也就是里面有猫的概率就越大。
以上就是神经网络为什么能够给出预测结果的大致原理。其实就像jack床长所说,“每个人都是一个巨型的神经网络”,只要我们善于反思、善于总结、善于学习,每个人都会变得越来越强大,都能成就更好的自己。
本章给大家介绍一种用于预测的算法——逻辑回归(logistic regression)
给定一个输入特征向量x(例如你想要识别的图像——是否有猫),你需要一个算法进行计算之后进行结果输出(在这里我们用的是逻辑回归算法)。这个被输出的预测结果我们称为y^y^,假设y是1,如果预测得很准的话y^y^可能会是0.99)。
上图第一个公式中的x是个(n,1)维的矩阵,表示一个训练样本,里面的n表示一个训练样本中的特征数量,例如一张图片就是一个训练样本,图片中每个颜色强度值就是一个特征;w也是一个(n,1)维的矩阵,它表示权重(weight),它一一对应于每个输入的特征,也可以说它指示了某个特征的重要程度;b是一个实数,在这里可以将其看作为一个阀值。
如何理解w和b呢?我举个例子来帮助大家理解。可以把上面的算法过程看作是一种通过权衡输入然后再做出决定的一个过程。假设周末即将到来,你听说在你的城市将会有一个音乐节。你要决定是否去参加这个节日。你需要通过权衡3个因素(3个特征)来做出决定:1、天气好吗 2、你的女友是否愿意陪你去 3、举办地点离地铁近吗 这3个因素就对应着上图中的x1、x2,x3(它们是x这个训练样本中的3个特征)。我们可以给它们赋个值,如果天气好,那么x1为1,否则为0,x2和x3雷同;假设你很讨厌坏天气,如果天气不好,你就不会去参加这个节日,对其它两个因素要求不高(这里假设你是个老司机,女人多得是,不怕冷落了女友)。那么我们分别给3个权重赋值为7,2,2。w1的值大很多,这表明天气对你来说很重要,比你的女友是否愿意去,以及交通的便利性更重要。而b我们可以看作一个阀值,假设我们给b赋值为-5,那么也就是说,只要天气好,即使女友不陪你去、交通也不方便,你也会去参加这个节日——x1 * w1 + x2 * w2 + x3 * w3 = 1 * 7 + 0 * 2 + 0 * 2 = 7(这里的*代表乘法)(我们这里先不考虑σ函数),而7 +(-5)> 0,结果是你会去那个音乐节。如果我们选择不同的w和b值,那么对于同一个输入x,会有不同的结果输出。
训练神经网络的目的就是通过训练过程来得到这些w和b值(后面会教大家如何来训练得到它们)。这些w和b值可以让神经网络得到一项判断能力,一项预测能力——输入一张图片,神经网络根据训练好的w和b,通过上面的公式根据每个像素的值以及与其对应的权重值以及阈值来判定这张图里是否有猫。神经网络就是这样来进行预测的。它和我们人类的思考方式是一样的。虽然我们人可以做出非常复杂的判断,但是基本原理是很简单的。人为什么能轻松分辨出一个图片中是否有猫?因为我们人就是一个巨型的神经网络,这个神经网络里面包含了数亿甚至更多的神经元(上图蓝色的圆圈就表示一个神经元),每个神经元都可以接受多个输入,在日常生活中,小孩子通过大人的教导,不断的看见猫,我们的神经元对于这个输入就形成了很多特定的w(权重),所以当再次看见一个猫时,这个输入(这个猫)与相应的w联合起来进行运算后,其结果就指示了这个输入是一个猫。
下面再来说一下σ,它代表了sigmoid函数,上面是它的定义公式以及图形。我们为什么需要它?在上面我们举的去参加节日的例子中,我们得出的结果为2,其实对于不同的x和w值,结果可能会更大。所以这并不适用于二元分类问题,因为在二元分类问题中你想要得到的y^y^应该表示一个概率,一个输入是否等于它真实标签的概率(例如输入的图像里面是否有猫)。所以y^y^的值应该在0和1之间。sigmoid函数的作用就是把计算结果转换为0和1之间的值。通过看它的图形就可以明白,往sigmoid函数里输入的值z越大,那么y^y^就越靠近1,也就是里面有猫的概率就越大。
以上就是神经网络为什么能够给出预测结果的大致原理。其实就像jack床长所说,“每个人都是一个巨型的神经网络”,只要我们善于反思、善于总结、善于学习,每个人都会变得越来越强大,都能成就更好的自己。

相关文章推荐
- 6、神经网络自己如何判断预测结果是否准确呢?
- 4、如何将待预测数据输入到神经网络中?
- 深度学习系列教程 - 1.2.1 如何将待预测数据输入到神经网络中
- 如何利用训练好的神经网络进行预测
- 小白都理解的人工智能系列(8)——如何检验神经网络结果Evaluate Model
- Keras 如何利用训练好的神经网络进行预测
- 如何利用训练好的神经网络进行预测
- 深度学习系列教程 - 1.2.3 神经网络如何判断自己预测得是否准确
- 干货|如何用Keras为序列预测问题开发复杂的编解码循环神经网络?
- 深度学习系列教程 - 1.2.2 神经网络是如何进行预测的?
- torch入门笔记10:如何建立torch神经网络模型
- 探索 | 神经网络到底是如何思考的?MIT精英们做了这么一个实验室来搞清楚
- 神经网络(3)---如何表示hypothesis,如何表示我们的model
- 判别或预测方法汇总(判别分析、神经网络、支持向量机SVM等)
- 思考: 如何设计 输出结果 具有对称性 的 网络结构
- 如何利用神经网络做回归问题(全连接以及一维卷积)
- 如何加强神经网络训练
- 如何实现模拟人类视觉注意力的循环神经网络?
- 用于金融时序预测的神经网络:可改善经典的移动平均线策略
- 使用机器学习预测天气(第三部分神经网络)