基于scrapy_redis部署scrapy分布式爬虫
2018-03-26 21:15
225 查看
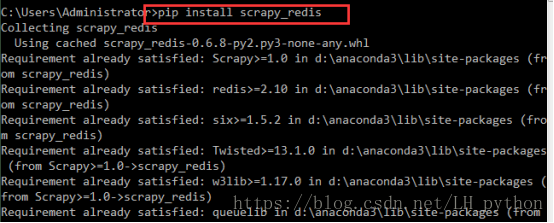
1使用命令行下载包 scrapy_redis
使用pycharm打开项目,找到settings文件,配置scrapy项目使用的调度器及过滤器
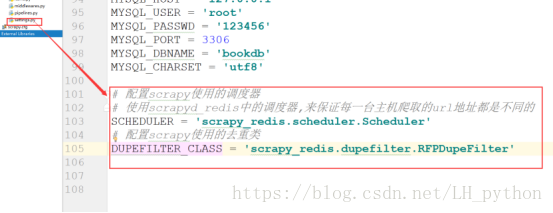

这个让scrapy不使用自己的调度器,使用scrapy_redis重写的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
这个是让scrapy使用scrapy_redis重写的去重方法,运用redis的去重方法
保证多台电脑运行的时候,不会爬取相同的url
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
这个是让爬取的item也在redis中备份一份,保证数据不会丢失。
'scrapy_redis.pipelines.RedisPipeline': 300
这个使用让多个爬虫文件从哪个ip地址的主机下拿去url。
3) 在settings.py中添加下面一句话,用于配置redis
REDIS_URL = 'redis://root:@192.168.9.211:6379'(自己的IP地址,Redis默认端口是6379)
==========
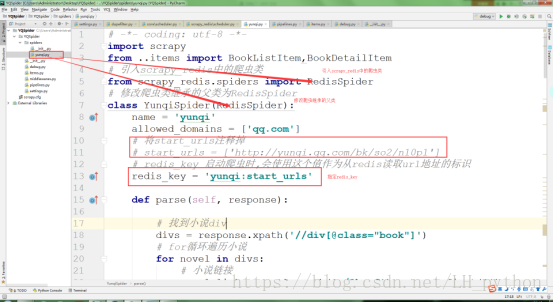
3) 修改爬虫的类文件
from scrapy_redis.spiders import RedisSpider
类需要继承自RedisSpider
把start_urls给注释掉,一般命名方法是:爬虫名:start_urls 方便区分记忆。
redis_key = 'jobbole:start_urls'
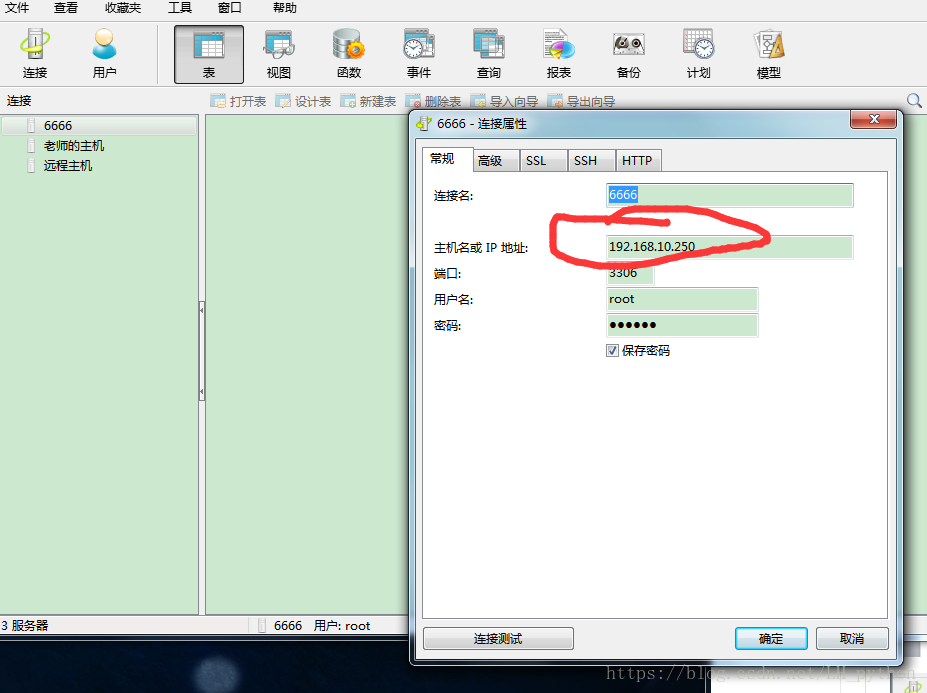
2. 如果连接的有远程服务,例如MySQL,Redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接
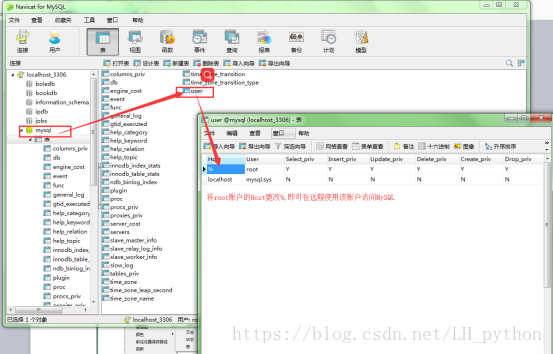
分布式用到的代码应该是同一套代码
1) 先把项目配置为分布式
2) 把项目拷贝到多台服务器中
3) 把所有爬虫项目都跑起来
4) 在redis中lpush你的网址即可
5) 效果:所有爬虫都开始运行,并且数据还都不一样
====
2. 配置远程连接的MySQL及redis地址
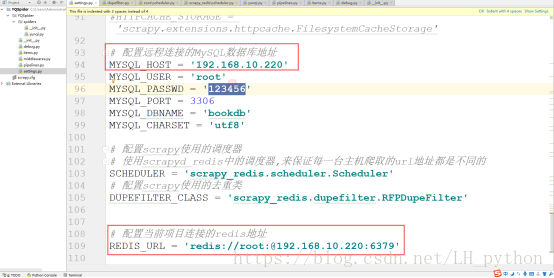
----------------------------------------------------------------------
分布式爬虫主机需要开启 redis-server redis.windows.conf 开启服务器端口,并开启(redis-cli -h ip地址 -p 端口号)
来开启客户端端口,用来lpush 网址
分机只需要接收文件,正常运行就好了
使用pycharm打开项目,找到settings文件,配置scrapy项目使用的调度器及过滤器
这个让scrapy不使用自己的调度器,使用scrapy_redis重写的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
这个是让scrapy使用scrapy_redis重写的去重方法,运用redis的去重方法
保证多台电脑运行的时候,不会爬取相同的url
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
这个是让爬取的item也在redis中备份一份,保证数据不会丢失。
'scrapy_redis.pipelines.RedisPipeline': 300
这个使用让多个爬虫文件从哪个ip地址的主机下拿去url。
3) 在settings.py中添加下面一句话,用于配置redis
REDIS_URL = 'redis://root:@192.168.9.211:6379'(自己的IP地址,Redis默认端口是6379)
==========
3) 修改爬虫的类文件
from scrapy_redis.spiders import RedisSpider
类需要继承自RedisSpider
把start_urls给注释掉,一般命名方法是:爬虫名:start_urls 方便区分记忆。
redis_key = 'jobbole:start_urls'
2. 如果连接的有远程服务,例如MySQL,Redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接
分布式用到的代码应该是同一套代码
1) 先把项目配置为分布式
2) 把项目拷贝到多台服务器中
3) 把所有爬虫项目都跑起来
4) 在redis中lpush你的网址即可
5) 效果:所有爬虫都开始运行,并且数据还都不一样
====
2. 配置远程连接的MySQL及redis地址
----------------------------------------------------------------------
分布式爬虫主机需要开启 redis-server redis.windows.conf 开启服务器端口,并开启(redis-cli -h ip地址 -p 端口号)
来开启客户端端口,用来lpush 网址
分机只需要接收文件,正常运行就好了

相关文章推荐
- 基于Scrapy_redis部署scrapy分布式爬虫
- 基于Scrapy_redis部署scrapy分布式爬虫
- Scrapy基于scrapy_redis实现分布式爬虫部署
- scrapy-redis的使用(基于scrapy的改装)
- 基于Python,scrapy,redis的分布式爬虫实现框架
- 基于Windows下使用Docker 部署Redis
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
- 基于Python,scrapy,redis的分布式爬虫实现框架
- 小白进阶之Scrapy(基于Scrapy-Redis的分布式以及cookies池)
- 基于twemproxy的redis集群部署
- 基于scrapy和redis的分布式爬虫环境搭建
- 基于Twemproxy的Redis集群方案部署
- 基于Python+scrapy+redis的分布式爬虫实现框架
- 基于Python使用scrapy-redis框架实现分布式爬虫 注
- scrapy-redis(七):部署scrapy
- 基于scrapy的redis安装和配置方法
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
- 使用Docker Compose部署基于Sentinel的高可用Redis集群