Spring Cloud Hystrix的依赖隔离和断路器(八)
2018-03-23 16:38
375 查看
前言
在上一篇中,我们已经体验了如何使用@HystrixCommand来为一个依赖资源定义服务降级逻辑。实现方式非常简单,同时对于降级逻辑还能实现一些更加复杂的级联降级等策略。之前对于使用Hystrix来实现服务容错保护时,除了服务降级之外,我们还提到过线程隔离、断路器等功能。那么在本篇中我们就来具体说说线程隔离。依赖隔离
“舱壁模式”对于熟悉Docker的读者一定不陌生,Docker通过“舱壁模式”实现进程的隔离,使得容器与容器之间不会互相影响。而Hystrix则使用该模式实现线程池的隔离,它会为每一个Hystrix命令创建一个独立的线程池,这样就算某个在Hystrix命令包装下的依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的服务。通过对依赖服务的线程池隔离实现,可以带来如下优势:
应用自身得到完全的保护,不会受不可控的依赖服务影响。即便给依赖服务分配的线程池被填满,也不会影响应用自身的额其余部分。
可以有效的降低接入新服务的风险。如果新服务接入后运行不稳定或存在问题,完全不会影响到应用其他的请求。
当依赖的服务从失效恢复正常后,它的线程池会被清理并且能够马上恢复健康的服务,相比之下容器级别的清理恢复速度要慢得多。
当依赖的服务出现配置错误的时候,线程池会快速的反应出此问题(通过失败次数、延迟、超时、拒绝等指标的增加情况)。同时,我们可以在不影响应用功能的情况下通过实时的动态属性刷新(后续会通过Spring Cloud Config与Spring Cloud Bus的联合使用来介绍)来处理它。
当依赖的服务因实现机制调整等原因造成其性能出现很大变化的时候,此时线程池的监控指标信息会反映出这样的变化。同时,我们也可以通过实时动态刷新自身应用对依赖服务的阈值进行调整以适应依赖方的改变。
除了上面通过线程池隔离服务发挥的优点之外,每个专有线程池都提供了内置的并发实现,可以利用它为同步的依赖服务构建异步的访问。
总之,通过对依赖服务实现线程池隔离,让我们的应用更加健壮,不会因为个别依赖服务出现问题而引起非相关服务的异常。同时,也使得我们的应用变得更加灵活,可以在不停止服务的情况下,配合动态配置刷新实现性能配置上的调整。
虽然线程池隔离的方案带了如此多的好处,但是很多使用者可能会担心为每一个依赖服务都分配一个线程池是否会过多地增加系统的负载和开销。对于这一点,使用者不用过于担心,因为这些顾虑也是大部分工程师们会考虑到的,Netflix在设计Hystrix的时候,认为线程池上的开销相对于隔离所带来的好处是无法比拟的。同时,Netflix也针对线程池的开销做了相关的测试,以证明和打消Hystrix实现对性能影响的顾虑。
下图是Netflix Hystrix官方提供的一个Hystrix命令的性能监控,该命令以每秒60个请求的速度(QPS)向一个单服务实例进行访问,该服务实例每秒运行的线程数峰值为350个。
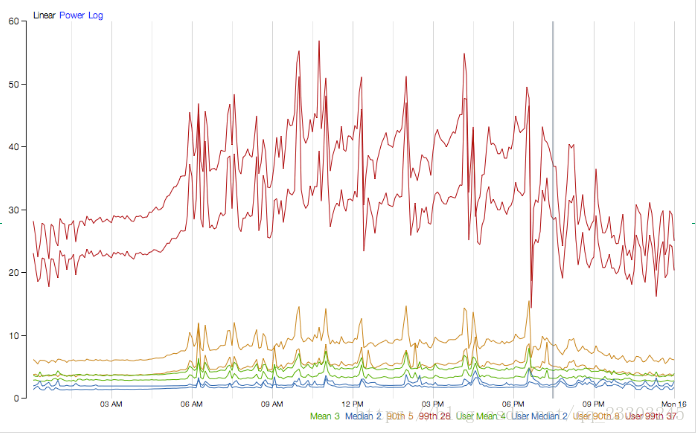
从图中的统计我们可以看到,使用线程池隔离与不使用线程池隔离的耗时差异如下表所示:

在99%的情况下,使用线程池隔离的延迟有9ms,对于大多数需求来说这样的消耗是微乎其微的,更何况为系统在稳定性和灵活性上所带来的巨大提升。虽然对于大部分的请求我们可以忽略线程池的额外开销,而对于小部分延迟本身就非常小的请求(可能只需要1ms),那么9ms的延迟开销还是非常昂贵的。实际上Hystrix也为此设计了另外的一个解决方案:信号量。
Hystrix中除了使用线程池之外,还可以使用信号量来控制单个依赖服务的并发度,信号量的开销要远比线程池的开销小得多,但是它不能设置超时和实现异步访问。所以,只有在依赖服务是足够可靠的情况下才使用信号量。在HystrixCommand和HystrixObservableCommand中2处支持信号量的使用:
命令执行:如果隔离策略参数execution.isolation.strategy设置为SEMAPHORE,Hystrix会使用信号量替代线程池来控制依赖服务的并发控制。
降级逻辑:当Hystrix尝试降级逻辑时候,它会在调用线程中使用信号量。
信号量的默认值为10,我们也可以通过动态刷新配置的方式来控制并发线程的数量。对于信号量大小的估算方法与线程池并发度的估算类似。仅访问内存数据的请求一般耗时在1ms以内,性能可以达到5000rps,这样级别的请求我们可以将信号量设置为1或者2,我们可以按此标准并根据实际请求耗时来设置信号量。
如何使用
说了那么多依赖隔离的好处,那么我们如何使用Hystrix来实现依赖隔离呢?其实,我们在上一篇定义服务降级的时候,已经自动的实现了依赖隔离。在上一篇的示例中,我们使用了@HystrixCommand来将某个函数包装成了Hystrix命令,这里除了定义服务降级之外,Hystrix框架就会自动的为这个函数实现调用的隔离。所以,依赖隔离、服务降级在使用时候都是一体化实现的,这样利用Hystrix来实现服务容错保护在编程模型上就非常方便的,并且考虑更为全面。除了依赖隔离、服务降级之外,还有一个重要元素:断路器。我们将在下一篇做详细的介绍,这三个重要利器构成了Hystrix实现服务容错保护的强力组合拳。
断路器
断路器模式源于Martin Fowler的Circuit Breaker一文。“断路器”本身是一种开关装置,用于在电路上保护线路过载,当线路中有电器发生短路时,“断路器”能够及时的切断故障电路,防止发生过载、发热、甚至起火等严重后果。在分布式架构中,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),直接切断原来的主逻辑调用。但是,在Hystrix中的断路器除了切断主逻辑的功能之外,还有更复杂的逻辑,下面我们来看看它更为深层次的处理逻辑。
以在上一文中实现的服务降级例子为示例,我们来说说断路器的工作原理。当我们把服务提供者eureka-client中加入了模拟的时间延迟之后,在服务消费端的服务降级逻辑因为hystrix命令调用依赖服务超时,触发了降级逻辑,但是即使这样,受限于Hystrix超时时间的问题,我们的调用依然很有可能产生堆积。
这个时候断路器就会发挥作用,那么断路器是在什么情况下开始起作用呢?这里涉及到断路器的三个重要参数:快照时间窗、请求总数下限、错误百分比下限。这个参数的作用分别是:
快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
请求总数下限:在快照时间窗内,必须满足请求总数下限才有资格根据熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用此时不足20次,即时所有的请求都超时或其他原因失败,断路器都不会打开。
错误百分比下限:当请求总数在快照时间窗内超过了下限,比如发生了30次调用,如果在这30次调用中,有16次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%下限情况下,这时候就会将断路器打开。
那么当断路器打开之后会发
4000
生什么呢?我们先来说说断路器未打开之前,对于之前那个示例的情况就是每个请求都会在当hystrix超时之后返回fallback,每个请求时间延迟就是近似hystrix的超时时间,如果设置为5秒,那么每个请求就都要延迟5秒才会返回。当熔断器在10秒内发现请求总数超过20,并且错误百分比超过50%,这个时候熔断器打开。打开之后,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级逻辑,这个时候就不会等待5秒之后才返回fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
在断路器打开之后,处理逻辑并没有结束,我们的降级逻辑已经被成了主逻辑,那么原来的主逻辑要如何恢复呢?对于这一问题,hystrix也为我们实现了自动恢复功能。当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
通过上面的一系列机制,hystrix的断路器实现了对依赖资源故障的端口、对降级策略的自动切换以及对主逻辑的自动恢复机制。这使得我们的微服务在依赖外部服务或资源的时候得到了非常好的保护,同时对于一些具备降级逻辑的业务需求可以实现自动化的切换与恢复,相比于设置开关由监控和运维来进行切换的传统实现方式显得更为智能和高效。

相关文章推荐
- Spring Cloud Spring Boot mybatis 企业分布式微服务云(八)服务容错保护(Hystrix依赖隔离)【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix依赖隔离)
- Spring Cloud Spring Boot mybatis 企业分布式微服务云(八)服务容错保护(Hystrix依赖隔离)【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix依赖隔离)
- Spring Cloud架构教程 (十五)服务容错保护(Hystrix依赖隔离)【Dalston版】
- Spring Cloud构建微服务架构:服务容错保护(Hystrix依赖隔离)【Dalston版】
- Spring Cloud构建微服务架构-Hystrix依赖隔离
- Spring Cloud构建微服务架构:服务容错保护(Hystrix依赖隔离)
- SpringCloud 学习 | 第八篇: 断路器监控使用(Hystrix Dashboard)
- SpringCloud之断路器聚合监控Spring Cloud Hystrix Turbine实例
- SpringCloud 教程 | 第四篇:断路器(Hystrix)
- SpringCloud: 断路器聚合监控(Hystrix Turbine)
- Spring Cloud构建微服务架构:服务容错保护(Hystrix断路器)【Dalston版】
- Spring Cloud 断路器Hystrix实战
- springcloud实战之8 断路器-仪表盘-单例监控(Hystrix)
- [bigdata-110] spring-cloud-06 Hystrix断路器
- SpringCloud之Ribbon和Feign断路器支持(Hystrix)|第四章-yellowcong
- Spring Cloud中使用Hystrix 线程隔离导致ThreadLocal数据丢失
- 疯狂Spring Cloud连载(18)Hystrix断路器的开启和关闭
- Spring Cloud中Hystrix 线程隔离导致ThreadLocal数据丢失(二)