【归纳整理】十大经典排序算法的简单C++实现
2018-03-22 22:19
656 查看
一、比较排序
1.冒泡排序
思路:通过不断交换的方式不断地把最大的数移到最后,就像鱼吐泡泡一样。
时间复杂度:平均:O(n^2),最好:O(n^2),最坏:O(n^2)
空间复杂度:O(1)
稳定性:稳定
效果图:

代码:void Bubblesort(int* a,int n)
{
for(int i=n-1; i>0; i--)
for(int j=0; j<i; j++)
{
if(a[j]>a[j+1])
swap(a[j],a[j+1]);
}
}2.选择排序
思路:每轮选出一个最小的数,把这个最小的数和a[0]交换。
时间复杂度:平均:O(n^2),最好:O(n^2),最坏:O(n^2)
空间复杂度:O(1)
稳定性:不稳定
效果图:

代码:void Selectionsort(int* a,int n)
{
for(int i=0; i<=n-2; i++)
{
int Min=i;
for(int j=i+1; j<=n-1; j++)
{
if(a[j]<a[Min])
Min=j;
}
swap(a[i],a[Min]);
}
}3.插入排序
思路:不断把后面的数“插入”前面已排序好的序列中合适的位置。
时间复杂度:平均:O(n^2),最好:O(n),最坏:O(n^2)
空间复杂度:O(1)
稳定性:稳定
效果图:

代码:void Insertsort(int* a,int n)
{
for(int i=1; i<n; i++)
{
int temp=a[i];
int j=i-1;
while(j>=0&&temp<a[j])
{
a[j+1]=a[j];
j--;
}
a[j+1]=temp;
}
}4.希尔排序
思路:把数组分为多组(每一定间隔(增量)的数为一组),进行多轮插入排序,
4000
可以减少移动次数。一开始先选择较大的增量,然后不断缩短增量直至增量为1,变为普通插入排序。增量序列可以任选,但必须是递减的,效率有高有低。
希尔排序是插入排序的改良版,其代价是牺牲了稳定性。
时间复杂度:不确定,与增量序列的选取有关,从O(nlogn)到O(n^2)不等
空间复杂度:O(1)
稳定性:不稳定
效果图:
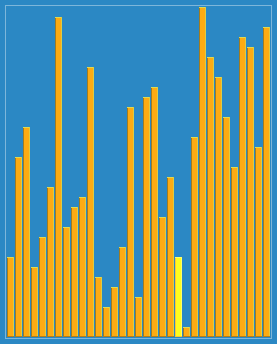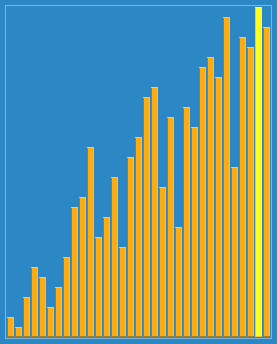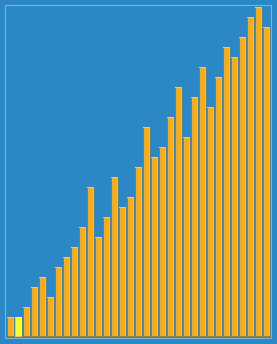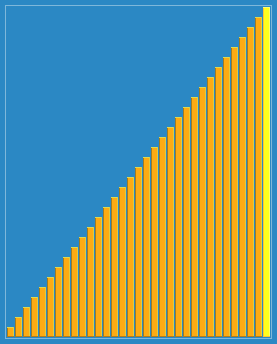
代码:void Shellsort(int* a,int n)
{
for(int gap=n/3; gap>=1; gap=(gap-1)/3+1)//选取增量并不断缩小,直至为1。增量可以任选,如Hibbard、Sedgewick序列。
//序列中两个相邻元素应尽量避免倍数关系。
//目前似乎还没有找到一个最高效的增量序列。
{
for(int i=gap; i<n; i++)//以下和插入排序方法相同,只是增量由1变为了gap。
{
int temp=a[i];
int j=i-gap;
while(j>=0&&temp<a[j])
{
a[j+gap]=a[j];
j-=gap;
}
a[j+gap]=temp;
}
if(gap<=1)//临界判断,防止死循环
break;
}
}5.快速排序
思路:把数组划分成两部分,左边的部分中所有的元素都小于右边的部分,然后分别对左右两部分进行同样的操作(递归)。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(n^2)
空间复杂度:O(logn)~O(n),与情况好坏有关,最坏情况要O(n)的空间压栈
稳定性:不稳定
效果图:
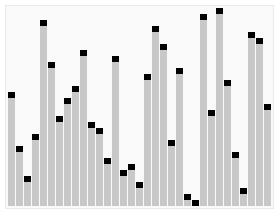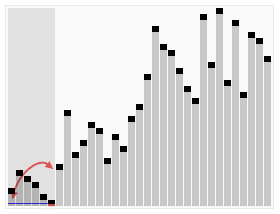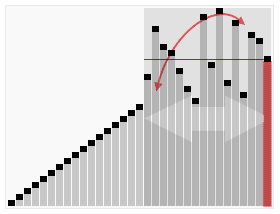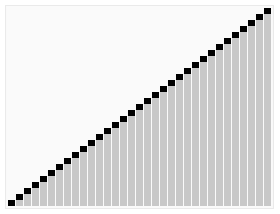
代码:int Partition(int *a,int n)//把数组a的n个元素划分为左右两部分,返回分界点。
{
int i=0;
for(int j=0; j<=n-2; j++)
if(a[j]<=a[n-1])
swap(a[i++],a[j]);//选取a[n-1]为主元,把前面的数逐一与其比较,小的放在前面,大的放在后面。
//主元可以随机选取,尽量避免最坏情况发生。
swap(a[i],a[n-1]);//最后把主元放在中间
return i;
}
void Quicksort(int *a,int n)
{
if(n<=1)
return;//临界判断
int i=Partition(a,n);//把a的n个元素划分为两部分,取其分界点。
Quicksort(a,i);
Quicksort(a+i+1,n-1-i);//对左右两部分递归划分。
}6.归并排序
思路:把数组平均分成两半,分别对左右两半部分进行排序,然后把两部分合并在一起(递归)。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(nlogn)
空间复杂度:O(n)
稳定性:稳定
效果图:

代码:void Merge(int* a,int p,int n)//把数组a对0~p-1和p~n两部分分别排序
{
const int Infinity=0x3f3f3f3f;//定义无穷大量
int n1=p,n2=n-p;
int* L=new int[n1+1],*R=new int[n2+1];//建立两个数组来分别保存左右两部分的元素
for(int i=0; i<n1; i++)
L[i]=a[i];
for(int i=0; i<n2; i++)
R[i]=a[p+i];
L[n1]=R[n2]=Infinity;//将左右两部分的最后一个元素设为无穷大,简化判断。
for(int i=0,j=0; i+j<n;)
{
if(L[i]<R[j])
{
a[i+j]=L[i];
i++;
}
else
{
a[i+j]=R[j];
j++;
}
}//每次取出左右两部分中较小的元素放回a中,因为有无穷大量垫底,所以不必判断是否为空。
delete []L;
delete []R;
}
void Mergesort(int* a,int n)
{
if(n<=1)
return;//临界判断
int i=n/2;//设置划分间隔,n/2为最佳选择。
Mergesort(a,i);
Mergesort(a+i,n-i);//对左右两部分分别排序(递归)
Merge(a,i,n);//将已排好序的两部分合并
}7.堆排序
思路:把数组想象成一棵二叉树(也叫二叉堆),通过计算得到每个元素在堆中对应的位置,通过元素交换使得堆中每一个节点都大于等于它的子节点(建立最大堆),然后不断把堆顶元素移到最后。整个过程中需要不断地维护最大堆。
堆排序与归并排序相比,节省了额外的空间;与快速排序相比,避免了最坏情况的O(n^2)的复杂度。但由于维护最大堆要花费大量的时间,因此在常数上堆排序要逊与归并和快排一筹。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(nlogn)
空间复杂度:O(1)
稳定性:不稳定
效果图:
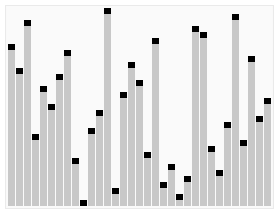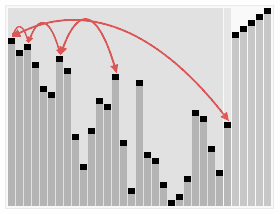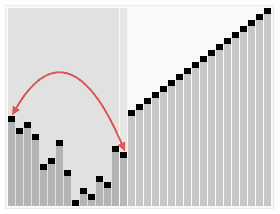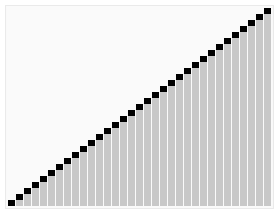
代码:void Max_heapify(int* a,int p,int n)//维护最大堆
{
int L=2*p+1,R=2*p+2;//计算左右孩子的下标
int largest=L<n&&a[L]>a[p]?L:p;
if(R<n&&a[R]>a[largest])
largest=R;//取得该节点与左右孩子中最大值的下标
if(largest!=p)
{
swap(a[p],a[largest]);//如果孩子中有元素比该节点大,那么交换它们的值。
Max_heapify(a,largest,n);//由于这么做可能会破坏以孩子为根节点的最大堆性质,需要对孩子做同样的处理。
}
}
void Heapsort(int* a,int n)
{
for(int i=n/2-1; i>=0; i--)
Max_heapify(a,i,n);//数组中,下标从n/2-1到0都是根节点,其余的是叶节点,对所有根节点倒序建立最大堆。
for(int i=n-1; i>=1; i--)
{
swap(a[0],a[i]);//建完堆后,把堆顶的元素与堆底元素交换。
Max_heapify(a,0,i);//由于上述操作也会破坏最大堆性质,需要再次维护最大堆。
}
}7种比较排序的效果对比图:

二、非比较排序
8.计数排序
思路:统计每个数字出现的次数,保存在另一个数组中,然后算出每个数应该填充的位置,填充到第三个数组中。
时间复杂度:O(n+k),k为待排序元素的取值范围 (由于是非比较排序,所以不存在最好最坏的情况)
空间复杂度:O(n+k) (需要n个临时存储空间以及k个计数器)
稳定性:稳定
代码:void Countingsort(int* a,int n)
{
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int* b=new int
;//用来临时存放排序后的元素
int* c=new int[maxn+1];//计数器
memset(c,0,sizeof(int)*(maxn+1));//清零计数器
for(int i=0; i<n; i++)
c[a[i]]++;//记录每个数出现的次数
for(int i=1; i<=maxn; i++)
c[i]+=c[i-1];//记录每个数应填充的位置
for(int i=n-1; i>=0; i--)
{
b[c[a[i]]-1]=a[i];//将a中的元素填充到数组b中相应的位置上,倒序填充为了维持稳定性。
c[a[i]]--;//每填充一次,下一个该填充的位置-1
}
memcpy(a,b,sizeof(int)*n);//将b复制给a
delete []b;
delete []c;
}9.基数排序
思路:选取一个数作为基数,通过对基数求余取模的方式把数组元素按照模的大小进行多轮计数排序,并不断成倍扩大这个基数直至大于数组中的最大元素。
时间复杂度:O((n+radix)*d) ,radix为基数大小,当与n相差很大时可以忽略。d为排序趟数,与最大值和基数有关。
空间复杂度:O(n+radix) (需要n个临时存储空间以及radix个计数器)
稳定性:稳定
代码:void Radixsort(int* a,int n)
{
const int radix=10;//选取基数,可以任选,比如16、32等,这里以10为例。选取合适的基数有助于提高效率。
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int* b=new int
;//用来临时存放排序后的元素
int* c=new int[radix];//计数器,数量与基数大小相同
for(int k=1; k<=maxn; k*=radix)//进行多轮计数排序,用k来记录基数的值,不断扩大k值直至超过最大值。
//以下操作方式与计数排序相同
{
memset(c,0,sizeof(int)*radix);//清零计数器
for(int i=0; i<n; i++)
c[a[i]/k%radix]++;
for(int i=1; i<radix; i++)
c[i]+=c[i-1];
for(int i=n-1; i>=0; i--)
{
b[c[a[i]/k%radix]-1]=a[i];
c[a[i]/k%radix]--;
}
memcpy(a,b,sizeof(int)*n);
}
delete []b;
delete []c;
}三、其他
10.桶排序
思路:把数组中的元素分散到多个数组(桶)中进行排序,保证每个桶中的元素都比下一个桶中的元素小,然后依次从每个桶中取出相应的元素。是比较排序与非比较排序结合的版本。
网上的桶排序有很多版本,我选择了用链表的形式来处理,这里以整数的排序为例。
时间复杂度:平均:O(n),最好:O(n),最坏:O(n^2) (数据分布越均匀效率越高)
空间复杂度:O(n+k),需要k个桶子以及n个链表元素
稳定性:稳定
代码:void Bucketsort(int* a,int n)
{
const int k=10;//选取桶数,以10为例
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int div=1;
while(maxn>=k)
{
maxn/=k;
div*=k;
}//计算出除数div,待排序元素除以div之后的结果即为该放进的桶的编号
list<int> bucket[k];//建桶
for(int i=n-1; i>=0; i--)
{
int d=a[i]/div;//计算出该放进的桶的编号
list<int>::iterator it=bucket[d].begin();
while(it!=bucket[d].end()&&a[i]>*it)
it++;
bucket[d].insert(it,a[i]);//将元素插入到合适的位置,倒序插入以维持稳定性
}
int p=0;
for(int i=0; i<k; i++)
{
for(list<int>::iterator it=bucket[i].begin(); it!=bucket[i].end(); it++)
a[p++]=*it;
}//将桶中的元素依次放回原数组
}参考文献:《算法导论》(机械工业出版社)
部分图片来源:
https://blog.csdn.net/seanblog/article/details/21395293
http://www.bubuko.com/infodetail-2052474.html
1.冒泡排序
思路:通过不断交换的方式不断地把最大的数移到最后,就像鱼吐泡泡一样。
时间复杂度:平均:O(n^2),最好:O(n^2),最坏:O(n^2)
空间复杂度:O(1)
稳定性:稳定
效果图:
代码:void Bubblesort(int* a,int n)
{
for(int i=n-1; i>0; i--)
for(int j=0; j<i; j++)
{
if(a[j]>a[j+1])
swap(a[j],a[j+1]);
}
}2.选择排序
思路:每轮选出一个最小的数,把这个最小的数和a[0]交换。
时间复杂度:平均:O(n^2),最好:O(n^2),最坏:O(n^2)
空间复杂度:O(1)
稳定性:不稳定
效果图:
代码:void Selectionsort(int* a,int n)
{
for(int i=0; i<=n-2; i++)
{
int Min=i;
for(int j=i+1; j<=n-1; j++)
{
if(a[j]<a[Min])
Min=j;
}
swap(a[i],a[Min]);
}
}3.插入排序
思路:不断把后面的数“插入”前面已排序好的序列中合适的位置。
时间复杂度:平均:O(n^2),最好:O(n),最坏:O(n^2)
空间复杂度:O(1)
稳定性:稳定
效果图:
代码:void Insertsort(int* a,int n)
{
for(int i=1; i<n; i++)
{
int temp=a[i];
int j=i-1;
while(j>=0&&temp<a[j])
{
a[j+1]=a[j];
j--;
}
a[j+1]=temp;
}
}4.希尔排序
思路:把数组分为多组(每一定间隔(增量)的数为一组),进行多轮插入排序,
4000
可以减少移动次数。一开始先选择较大的增量,然后不断缩短增量直至增量为1,变为普通插入排序。增量序列可以任选,但必须是递减的,效率有高有低。
希尔排序是插入排序的改良版,其代价是牺牲了稳定性。
时间复杂度:不确定,与增量序列的选取有关,从O(nlogn)到O(n^2)不等
空间复杂度:O(1)
稳定性:不稳定
效果图:
代码:void Shellsort(int* a,int n)
{
for(int gap=n/3; gap>=1; gap=(gap-1)/3+1)//选取增量并不断缩小,直至为1。增量可以任选,如Hibbard、Sedgewick序列。
//序列中两个相邻元素应尽量避免倍数关系。
//目前似乎还没有找到一个最高效的增量序列。
{
for(int i=gap; i<n; i++)//以下和插入排序方法相同,只是增量由1变为了gap。
{
int temp=a[i];
int j=i-gap;
while(j>=0&&temp<a[j])
{
a[j+gap]=a[j];
j-=gap;
}
a[j+gap]=temp;
}
if(gap<=1)//临界判断,防止死循环
break;
}
}5.快速排序
思路:把数组划分成两部分,左边的部分中所有的元素都小于右边的部分,然后分别对左右两部分进行同样的操作(递归)。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(n^2)
空间复杂度:O(logn)~O(n),与情况好坏有关,最坏情况要O(n)的空间压栈
稳定性:不稳定
效果图:
代码:int Partition(int *a,int n)//把数组a的n个元素划分为左右两部分,返回分界点。
{
int i=0;
for(int j=0; j<=n-2; j++)
if(a[j]<=a[n-1])
swap(a[i++],a[j]);//选取a[n-1]为主元,把前面的数逐一与其比较,小的放在前面,大的放在后面。
//主元可以随机选取,尽量避免最坏情况发生。
swap(a[i],a[n-1]);//最后把主元放在中间
return i;
}
void Quicksort(int *a,int n)
{
if(n<=1)
return;//临界判断
int i=Partition(a,n);//把a的n个元素划分为两部分,取其分界点。
Quicksort(a,i);
Quicksort(a+i+1,n-1-i);//对左右两部分递归划分。
}6.归并排序
思路:把数组平均分成两半,分别对左右两半部分进行排序,然后把两部分合并在一起(递归)。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(nlogn)
空间复杂度:O(n)
稳定性:稳定
效果图:
代码:void Merge(int* a,int p,int n)//把数组a对0~p-1和p~n两部分分别排序
{
const int Infinity=0x3f3f3f3f;//定义无穷大量
int n1=p,n2=n-p;
int* L=new int[n1+1],*R=new int[n2+1];//建立两个数组来分别保存左右两部分的元素
for(int i=0; i<n1; i++)
L[i]=a[i];
for(int i=0; i<n2; i++)
R[i]=a[p+i];
L[n1]=R[n2]=Infinity;//将左右两部分的最后一个元素设为无穷大,简化判断。
for(int i=0,j=0; i+j<n;)
{
if(L[i]<R[j])
{
a[i+j]=L[i];
i++;
}
else
{
a[i+j]=R[j];
j++;
}
}//每次取出左右两部分中较小的元素放回a中,因为有无穷大量垫底,所以不必判断是否为空。
delete []L;
delete []R;
}
void Mergesort(int* a,int n)
{
if(n<=1)
return;//临界判断
int i=n/2;//设置划分间隔,n/2为最佳选择。
Mergesort(a,i);
Mergesort(a+i,n-i);//对左右两部分分别排序(递归)
Merge(a,i,n);//将已排好序的两部分合并
}7.堆排序
思路:把数组想象成一棵二叉树(也叫二叉堆),通过计算得到每个元素在堆中对应的位置,通过元素交换使得堆中每一个节点都大于等于它的子节点(建立最大堆),然后不断把堆顶元素移到最后。整个过程中需要不断地维护最大堆。
堆排序与归并排序相比,节省了额外的空间;与快速排序相比,避免了最坏情况的O(n^2)的复杂度。但由于维护最大堆要花费大量的时间,因此在常数上堆排序要逊与归并和快排一筹。
时间复杂度:平均:O(nlogn),最好:O(nlogn),最坏:O(nlogn)
空间复杂度:O(1)
稳定性:不稳定
效果图:
代码:void Max_heapify(int* a,int p,int n)//维护最大堆
{
int L=2*p+1,R=2*p+2;//计算左右孩子的下标
int largest=L<n&&a[L]>a[p]?L:p;
if(R<n&&a[R]>a[largest])
largest=R;//取得该节点与左右孩子中最大值的下标
if(largest!=p)
{
swap(a[p],a[largest]);//如果孩子中有元素比该节点大,那么交换它们的值。
Max_heapify(a,largest,n);//由于这么做可能会破坏以孩子为根节点的最大堆性质,需要对孩子做同样的处理。
}
}
void Heapsort(int* a,int n)
{
for(int i=n/2-1; i>=0; i--)
Max_heapify(a,i,n);//数组中,下标从n/2-1到0都是根节点,其余的是叶节点,对所有根节点倒序建立最大堆。
for(int i=n-1; i>=1; i--)
{
swap(a[0],a[i]);//建完堆后,把堆顶的元素与堆底元素交换。
Max_heapify(a,0,i);//由于上述操作也会破坏最大堆性质,需要再次维护最大堆。
}
}7种比较排序的效果对比图:
二、非比较排序
8.计数排序
思路:统计每个数字出现的次数,保存在另一个数组中,然后算出每个数应该填充的位置,填充到第三个数组中。
时间复杂度:O(n+k),k为待排序元素的取值范围 (由于是非比较排序,所以不存在最好最坏的情况)
空间复杂度:O(n+k) (需要n个临时存储空间以及k个计数器)
稳定性:稳定
代码:void Countingsort(int* a,int n)
{
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int* b=new int
;//用来临时存放排序后的元素
int* c=new int[maxn+1];//计数器
memset(c,0,sizeof(int)*(maxn+1));//清零计数器
for(int i=0; i<n; i++)
c[a[i]]++;//记录每个数出现的次数
for(int i=1; i<=maxn; i++)
c[i]+=c[i-1];//记录每个数应填充的位置
for(int i=n-1; i>=0; i--)
{
b[c[a[i]]-1]=a[i];//将a中的元素填充到数组b中相应的位置上,倒序填充为了维持稳定性。
c[a[i]]--;//每填充一次,下一个该填充的位置-1
}
memcpy(a,b,sizeof(int)*n);//将b复制给a
delete []b;
delete []c;
}9.基数排序
思路:选取一个数作为基数,通过对基数求余取模的方式把数组元素按照模的大小进行多轮计数排序,并不断成倍扩大这个基数直至大于数组中的最大元素。
时间复杂度:O((n+radix)*d) ,radix为基数大小,当与n相差很大时可以忽略。d为排序趟数,与最大值和基数有关。
空间复杂度:O(n+radix) (需要n个临时存储空间以及radix个计数器)
稳定性:稳定
代码:void Radixsort(int* a,int n)
{
const int radix=10;//选取基数,可以任选,比如16、32等,这里以10为例。选取合适的基数有助于提高效率。
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int* b=new int
;//用来临时存放排序后的元素
int* c=new int[radix];//计数器,数量与基数大小相同
for(int k=1; k<=maxn; k*=radix)//进行多轮计数排序,用k来记录基数的值,不断扩大k值直至超过最大值。
//以下操作方式与计数排序相同
{
memset(c,0,sizeof(int)*radix);//清零计数器
for(int i=0; i<n; i++)
c[a[i]/k%radix]++;
for(int i=1; i<radix; i++)
c[i]+=c[i-1];
for(int i=n-1; i>=0; i--)
{
b[c[a[i]/k%radix]-1]=a[i];
c[a[i]/k%radix]--;
}
memcpy(a,b,sizeof(int)*n);
}
delete []b;
delete []c;
}三、其他
10.桶排序
思路:把数组中的元素分散到多个数组(桶)中进行排序,保证每个桶中的元素都比下一个桶中的元素小,然后依次从每个桶中取出相应的元素。是比较排序与非比较排序结合的版本。
网上的桶排序有很多版本,我选择了用链表的形式来处理,这里以整数的排序为例。
时间复杂度:平均:O(n),最好:O(n),最坏:O(n^2) (数据分布越均匀效率越高)
空间复杂度:O(n+k),需要k个桶子以及n个链表元素
稳定性:稳定
代码:void Bucketsort(int* a,int n)
{
const int k=10;//选取桶数,以10为例
int maxn=a[0];
for(int i=1; i<n; i++)
if(a[i]>maxn)
maxn=a[i];//获取待排序元素中的最大值
int div=1;
while(maxn>=k)
{
maxn/=k;
div*=k;
}//计算出除数div,待排序元素除以div之后的结果即为该放进的桶的编号
list<int> bucket[k];//建桶
for(int i=n-1; i>=0; i--)
{
int d=a[i]/div;//计算出该放进的桶的编号
list<int>::iterator it=bucket[d].begin();
while(it!=bucket[d].end()&&a[i]>*it)
it++;
bucket[d].insert(it,a[i]);//将元素插入到合适的位置,倒序插入以维持稳定性
}
int p=0;
for(int i=0; i<k; i++)
{
for(list<int>::iterator it=bucket[i].begin(); it!=bucket[i].end(); it++)
a[p++]=*it;
}//将桶中的元素依次放回原数组
}参考文献:《算法导论》(机械工业出版社)
部分图片来源:
https://blog.csdn.net/seanblog/article/details/21395293
http://www.bubuko.com/infodetail-2052474.html

相关文章推荐
- 【整理】经典内部排序算法总结和C/C++实现
- 十大经典排序算法的 JavaScript 实现
- 用JavaScript实现十大经典排序算法--插入排序
- 十大经典排序算法的 JavaScript 实现
- C++实现顺序排序算法简单示例代码
- 七种常见经典排序算法分析与实现--C++
- 用JavaScript实现十大经典排序算法--冒泡排序
- 用JavaScript实现十大经典排序算法--快速排序
- 用JavaScript实现十大经典排序算法--选择排序
- 经典的7种排序算法 原理C++实现
- 一些经典排序算法的实现(C/C++实现)
- 先码后看 十大经典排序算法最强总结(含Java代码实现) 侵立删
- 非常经典的C++ 引用计数技术及智能指针的简单实现
- 排序算法总结与C++实现(冒泡、简单选择、直接插入、堆、归并、快速)
- 经典的7种排序算法 原理C++实现
- 用C++实现七种排序算法,可选择排序方法,简单易懂。
- [数据结构]七种排序算法的C++简单实现
- C/C++经典算法精华整理(3)-实现栈的数据结构
- 十大经典排序算法最强总结(含Java代码实现)
- 各种排序算法学习整理 C++实现