数据结构 B+树 索引
2018-03-18 21:18
381 查看
具体参见:http://blog.csdn.net/hust_dxxxd/article/details/50905446
部分转自:https://www.cnblogs.com/gengsc/p/7230514.html
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1]个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):
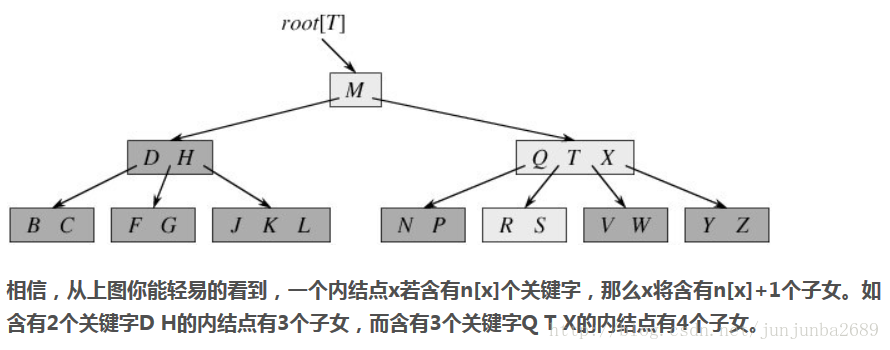
B树 特性:
1)树中每个结点最多含有m个孩子(m>=2);
2)除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
3) 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4)所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
5)每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:

B树的类型和节点定义如下图所示:

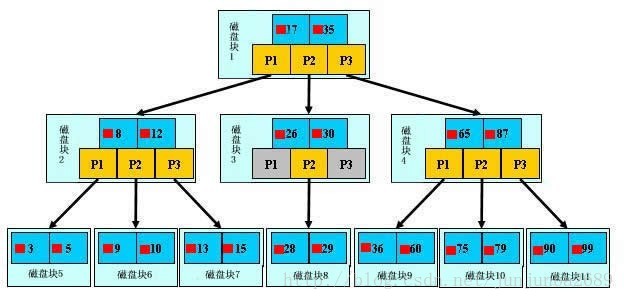
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
根据p2指针,我们定位到磁盘块3,并将
b607
其中的信息导入内存。【磁盘IO操作 2次】
此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。
B树的高度由什么决定的呢?
若B树某一非叶子节点包含N个关键字,则此非叶子节点含有N+1个孩子结点,而所有的叶子结点都在第I层,我们可以得出:
所以
这个B树的高度公式从侧面显示了B树的查找效率是相当高的。
曾在一次面试中被问到,一棵含有N个总关键字数的m阶的B树的最大高度是多少?答曰:log_ceil(m/2)(N+1)/2 + 1 (上面中关于m阶B树的第1点特性已经提到:树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<=m<=m。而树中每个结点含孩子数越少,树的高度则越大,故如此)。在2012微软4月份的笔试中也问到了此问题。
一棵m阶的B+树和m阶的B树的异同点在于:
1.有n棵子树的结点中含有n-1 个关键字; (此处颇有争议,B+树到底是与B 树n棵子树有n-1个关键字 保持一致,还是不一致:B树n棵子树的结点中含有n个关键字,待后续查证。暂先提供两个参考链接)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
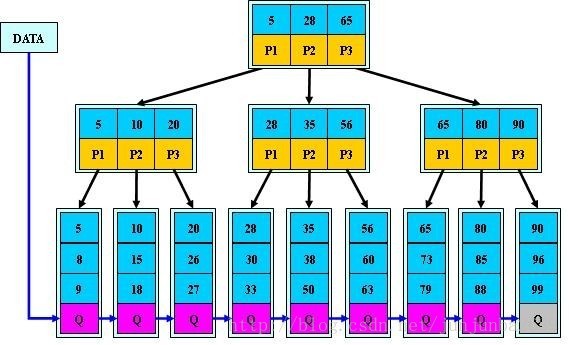
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
补充:
索引主要进行提高数据的查询速度。 当进行DML时,会更新索引。因此索引越多,则DML越慢,其需要维护索引。 因此在创建索引及DML需要权衡。
创建索引:
单一索引:
Create Index On(Column_Name);
复合索引:
Create Index i_deptno_job onemp(deptno,job);
—>在emp表的deptno、job列建立索引。
DBA经常用 REBUILD 来重建索引可以减少硬盘碎片和提高应用系统的性能。
答:主要是基于Hash表和B+树
题目2: 请你说一下B+树的实现细节是什么样的?B-树和B+树有什么区别?联合索引在B+树中如何存储?
答: 首先,数据库使用树型结构来增加查询效率,并保持有序。
那么,为什么不使用二叉树来实现数据结构呢,二叉树算法时间复杂度是lg(N),查询速度和比较次数都是较小的。
实际上,查询索引操作最耗资源的不在内存中,而是磁盘IO。索引是存在磁盘上的,当数据量比较大的时候,索引的大小可能达到几个G。
那么,我们利用索引进行查询的时候,不可能把索引直接加载到内存中,只能一次读取一个磁盘页,一个磁盘页对应着一个节点,一次读取操作时一个磁盘io。
在二叉树查询时,最坏的情况下查找的次数是树的高度,即io次数为树的高度。B-树就是比二叉树“矮胖”的树。
B树的特征如下:
根节点至少有两个子女
每个中间节点包含k-1个元素和k个孩子,其中 m/2 <= k <= m
每个叶子节点包含k-1个元素,其中 m/2 <= k <= m
所有叶子节点位于同一层
节点中的元素从小到大排列,正好是孩子节点的值域。(就是孩子节点的元素都比父节点中元素的最小值大,比父节点元素的最大值小)
B-树查询的次数并不比二叉树的次数小,但是相比起磁盘io速度,内存中比较的耗时就不足为提了。所以只要树的高度足够低,io次数少,就可以提升查找性能。而每个节点中有多个元素,都只在内存中操作。
而B+树是基于B-树的,增加了如下规则:
有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
所以,B+树对比B-树有如下好处:
io次数少:b+树中间节点只存索引,不存在实际的数据,所以可以存储更多的数据。索引树更加的矮胖,io次数更少。
性能稳定:b+树数据只存在于叶子节点,查询性能稳定
范围查询简单:b+树不需要中序遍历,遍历链表即可。
部分转自:https://www.cnblogs.com/gengsc/p/7230514.html
1. B树
我们知道,B 树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。与本blog之前介绍的红黑树很相似,但在降低磁盘I/0操作方面要更好一些。许多数据库系统都一般使用B树或者B树的各种变形结构,如下文即将要介绍的B+树,B*树来存储信息。B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。那为什么又说B树与红黑树很相似呢?因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,应为它的分支因子比较大。所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
如下图所示,即是一棵B树,一棵关键字为英语中辅音字母的B树,现在要从树种查找字母R(包含n[x]个关键字的内结点x,x有n[x]+1]个子女(也就是说,一个内结点x若含有n[x]个关键字,那么x将含有n[x]+1个子女)。所有的叶结点都处于相同的深度,带阴影的结点为查找字母R时要检查的结点):
B树 特性:
1)树中每个结点最多含有m个孩子(m>=2);
2)除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
3) 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4)所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
5)每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:
B树的类型和节点定义如下图所示:
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
根据p2指针,我们定位到磁盘块3,并将
b607
其中的信息导入内存。【磁盘IO操作 2次】
此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
根据上面的例子我们可以看出,对于辅存做IO读的次数取决于B树的高度。
B树的高度由什么决定的呢?
若B树某一非叶子节点包含N个关键字,则此非叶子节点含有N+1个孩子结点,而所有的叶子结点都在第I层,我们可以得出:
因为根至少有两个孩子,因此第2层至少有两个结点。 除根和叶子外,其它结点至少有┌m/2┐个孩子, 因此在第3层至少有2*┌m/2┐个结点, 在第4层至少有2*(┌m/2┐^2)个结点, 在第 I 层至少有2*(┌m/2┐^(l-2) )个结点,于是有: N+1 ≥ 2*┌m/2┐I-2; 考虑第L层的结点个数为N+1,那么2*(┌m/2┐^(l-2))≤N+1,也就是L层的最少结点数刚好达到N+1个,即: I≤ log┌m/2┐((N+1)/2 )+2;
所以
当B树包含N个关键字时,B树的最大高度为l-1(因为计算B树高度时,叶结点所在层不计算在内),即: l - 1 = log┌m/2┐((N+1)/2 )+1。
这个B树的高度公式从侧面显示了B树的查找效率是相当高的。
曾在一次面试中被问到,一棵含有N个总关键字数的m阶的B树的最大高度是多少?答曰:log_ceil(m/2)(N+1)/2 + 1 (上面中关于m阶B树的第1点特性已经提到:树中每个结点含有最多含有m个孩子,即m满足:ceil(m/2)<=m<=m。而树中每个结点含孩子数越少,树的高度则越大,故如此)。在2012微软4月份的笔试中也问到了此问题。
2. B+树
是应文件系统所需而产生的一种B-tree的变形树。一棵m阶的B+树和m阶的B树的异同点在于:
1.有n棵子树的结点中含有n-1 个关键字; (此处颇有争议,B+树到底是与B 树n棵子树有n-1个关键字 保持一致,还是不一致:B树n棵子树的结点中含有n个关键字,待后续查证。暂先提供两个参考链接)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
补充:
索引主要进行提高数据的查询速度。 当进行DML时,会更新索引。因此索引越多,则DML越慢,其需要维护索引。 因此在创建索引及DML需要权衡。
创建索引:
单一索引:
Create Index On(Column_Name);
复合索引:
Create Index i_deptno_job onemp(deptno,job);
—>在emp表的deptno、job列建立索引。
DBA经常用 REBUILD 来重建索引可以减少硬盘碎片和提高应用系统的性能。
ALTER INDEX emp_ix REBUILD REVERSE; //修改索引 drop index pk_dept; //删除索引
3.面试案例
题目1: Mysql数据库用过吧?l里面的索引是基于什么数据结构。答:主要是基于Hash表和B+树
题目2: 请你说一下B+树的实现细节是什么样的?B-树和B+树有什么区别?联合索引在B+树中如何存储?
答: 首先,数据库使用树型结构来增加查询效率,并保持有序。
那么,为什么不使用二叉树来实现数据结构呢,二叉树算法时间复杂度是lg(N),查询速度和比较次数都是较小的。
实际上,查询索引操作最耗资源的不在内存中,而是磁盘IO。索引是存在磁盘上的,当数据量比较大的时候,索引的大小可能达到几个G。
那么,我们利用索引进行查询的时候,不可能把索引直接加载到内存中,只能一次读取一个磁盘页,一个磁盘页对应着一个节点,一次读取操作时一个磁盘io。
在二叉树查询时,最坏的情况下查找的次数是树的高度,即io次数为树的高度。B-树就是比二叉树“矮胖”的树。
B树的特征如下:
根节点至少有两个子女
每个中间节点包含k-1个元素和k个孩子,其中 m/2 <= k <= m
每个叶子节点包含k-1个元素,其中 m/2 <= k <= m
所有叶子节点位于同一层
节点中的元素从小到大排列,正好是孩子节点的值域。(就是孩子节点的元素都比父节点中元素的最小值大,比父节点元素的最大值小)
B-树查询的次数并不比二叉树的次数小,但是相比起磁盘io速度,内存中比较的耗时就不足为提了。所以只要树的高度足够低,io次数少,就可以提升查找性能。而每个节点中有多个元素,都只在内存中操作。
而B+树是基于B-树的,增加了如下规则:
有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
所以,B+树对比B-树有如下好处:
io次数少:b+树中间节点只存索引,不存在实际的数据,所以可以存储更多的数据。索引树更加的矮胖,io次数更少。
性能稳定:b+树数据只存在于叶子节点,查询性能稳定
范围查询简单:b+树不需要中序遍历,遍历链表即可。

相关文章推荐
- 【数据结构之二叉树】(一)B树、B-树、B+树、B*树介绍,和B+树更适合做文件索引的原因
- 【数据结构之二叉树】(二)B+树比B树更适合做文件索引的原因
- 【数据结构之二叉树】(二)B+树比B树更适合做文件索引的原因
- 数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
- B+树索引结构
- MySQL索引结构--由 B-/B+树看
- 四种数据存储结构---顺序存储 链接存储 索引存储 散列存储
- Atitit.数据索引 的种类以及原理实现机制 索引常用的存储结构 v3 r819
- B-树和B+树的应用:数据搜索和数据库索引
- (转)B-树和B+树的应用:数据搜索和数据库索引
- Atitit.数据索引 的种类以及原理实现机制 索引常用的存储结构
- 数据结构——什么是B树和B+树
- 索引基础——B-Tree、B+Tree、红黑树、B*Tree数据结构
- B-树和B+树的应用:数据搜索和数据库索引
- Atitit.数据索引 的种类以及原理实现机制 索引常用的存储结构
- 数据结构2:B树,B+树,B*树
- 在表中有大量数据时,修改了表结构或者索引造成表锁死时的解决办法
- ElasticSearch51:索引管理_内核级知识点_深入探秘type底层数据结构
- 四种数据存储结构---顺序存储 链接存储 索引存储 散列存储
- 数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)