神经网络学习(七)MNIST手写字识别 --- Python实现
2018-03-17 10:46
951 查看
系列博客是博主学习神经网络中相关的笔记和一些个人理解,仅为作者记录笔记之用,不免有很多细节不对之处。
将 mnist_loader.py 中的 import cPickle 修改为 import pickle
将 mnist_loader.py 中 的
training_data, validation_data, test_data需要用
若干个print函数需要修改
本节全部代码可以在这里下载到(没有积分的朋友可以私信我),
批处理的随机梯度下降法(mini-batch SGD)在训练模型阶段随机选取nn个样本作为一批(batch)样本,先通过前馈运算得到预测并计算其误差,后通过梯度下降法更新参数,梯度从后往前逐层反馈,直至更新到网络的第一层参数,这样的一个参数更新过程称为一个”批处理过程”(mini-batch)。不同批处理之间按照无放回抽样遍历所有训练样本集样本,遍历一次训练样本称为“一轮”(epoch)。
通过上面这段话可知,一个epoch内无放回遍历所有样本,我在之前的程序中把一个epoch理解为一次模型更新了,并且样本选取属于有放回进行的,这样导致的一个后果是有些数据可能始终都没有参与到模型更新中,造成数据的浪费。(以后的程序更正这个问题,鉴于前面的程序分类效果还OK,博主太懒不再更正了)
Michael Nielsen 的相关代码参见neural networks and deep learning,这里就不做过多介绍了。为了与他的 network(他有三个版本的,第一个版本为 network ,两个优化版本为 network2 和 network3)相区别,我自己编写的神经网络称为gnetwork.
下面是运行脚本
下面是运行结果
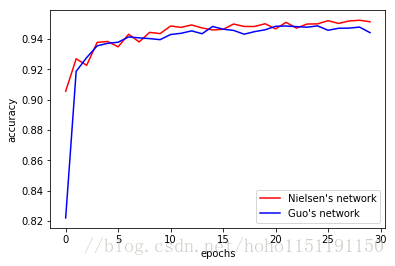
下面是 mini_batch_size = 15 的结果
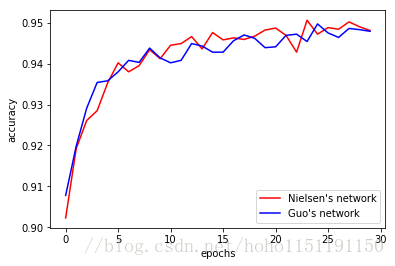
上面的两张图是单次结果,多次试验两者基本没有差。进行对比仅仅是为了验证我们的程序是不是可以达到正常分类水平。Michael Nielsen 称他的第一个版本的 network 识别率可以超过 96%。我运行了多次,始终没有出现超过96%的情况(这充分说明:调参有多么重要!)
Michael Nielsen 的 network 是没有进行优化的,运行效率还是要低一些的。我自己编写的这个的效率会高一些,下面有个简单的对比
下面看看 gNetwork 的实现,Python 实现与前面的 Matlab 实现大同小异,
Michael Nielsen 的 network 计算思路是:先把整个训练样本分为若干个mini_batch,再对 mini_batch 内的每个样本进行循序,计算每个样本所对应的误差,最后对 mini_batch 内的样本求和取平均更新模型。
上面的这段代码是一次性计算完整个 mini_batch 的误差,不做
运行结果如下:
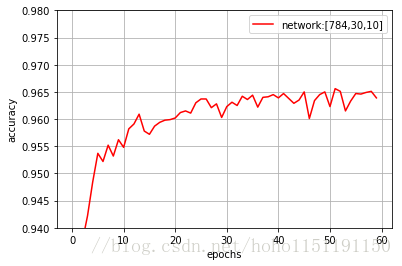
在20个epoch以内可以达到96.0%的识别率,最高可以达到96.5%。设置多个隐层后,分辨率稍有提高,偶尔可达到97.0%,但是训练次数太多后就不稳定了,精度反而急剧下降。
说明
上一节,我们介绍了MNIST手写字的Matlab实现,本节我们看看它的一个简单的Python实现(警告:博主是Python小白),本节代码是参考了 Michael Nielsen的neural networks and deep learning相关代码基础上完成的。博主用的Python版本为3.6。Michael Nielsen的代码是2.7版本的,如果想在3.6版本下使用,需要修改几个地方,将 mnist_loader.py 中的 import cPickle 修改为 import pickle
将 mnist_loader.py 中 的
load_data()函数中 training_data, validation_data, test_data = cPickle.load(f) 语句修改为 training_data, validation_data, test_data = pickle.load(f,encoding = ‘latin1’)
training_data, validation_data, test_data需要用
list()函数处理下
若干个print函数需要修改
本节全部代码可以在这里下载到(没有积分的朋友可以私信我),
实现
我在前面的几个程序中,对随机梯度中的随机理解有些偏差,我的理解是在每次更新过程(一次迭代)中随机选取一些样本进行模型更新,并且把一次迭代称为一个epoch,这个理解是不恰当的,且看下面这段话(摘自解析卷积神经网络-深度学习实践的手册)批处理的随机梯度下降法(mini-batch SGD)在训练模型阶段随机选取nn个样本作为一批(batch)样本,先通过前馈运算得到预测并计算其误差,后通过梯度下降法更新参数,梯度从后往前逐层反馈,直至更新到网络的第一层参数,这样的一个参数更新过程称为一个”批处理过程”(mini-batch)。不同批处理之间按照无放回抽样遍历所有训练样本集样本,遍历一次训练样本称为“一轮”(epoch)。
通过上面这段话可知,一个epoch内无放回遍历所有样本,我在之前的程序中把一个epoch理解为一次模型更新了,并且样本选取属于有放回进行的,这样导致的一个后果是有些数据可能始终都没有参与到模型更新中,造成数据的浪费。(以后的程序更正这个问题,鉴于前面的程序分类效果还OK,博主太懒不再更正了)
Michael Nielsen 的相关代码参见neural networks and deep learning,这里就不做过多介绍了。为了与他的 network(他有三个版本的,第一个版本为 network ,两个优化版本为 network2 和 network3)相区别,我自己编写的神经网络称为gnetwork.
下面是运行脚本
import mnist_loader
import matplotlib.pyplot as plt
import time
import network
import gnetwork
#数据载入
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
test_data = list(test_data)
training_data = list(tr
fb25
aining_data)
#Michael Nielsen的network
net = network.Network([784,30,10])
start = time.clock()
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
print("Time elapsed: ",(time.clock()-start))
#我的network
gnet = gnetwork.gNetwork([784,30,10])
start = time.clock()
gnet.SGD(training_data, 30, 10, 3.0, test_data=test_data)
print("Time elapsed: ",(time.clock()-start))
#绘图
plt.figure()
plt.plot(net.accuracy,color = "r",label = "Nielsen's network")
plt.plot(gnet.accuracy,color = "b",label = "Guo's network")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()下面是运行结果
下面是 mini_batch_size = 15 的结果
上面的两张图是单次结果,多次试验两者基本没有差。进行对比仅仅是为了验证我们的程序是不是可以达到正常分类水平。Michael Nielsen 称他的第一个版本的 network 识别率可以超过 96%。我运行了多次,始终没有出现超过96%的情况(这充分说明:调参有多么重要!)
Michael Nielsen 的 network 是没有进行优化的,运行效率还是要低一些的。我自己编写的这个的效率会高一些,下面有个简单的对比
| mini_batch_size | Michael Nielsen | Guo chf |
|---|---|---|
| 10 | 147.2 | 34.8 |
| 15 | 149.3 | 25.9 |
"""
gnetwork.py
~~~~~~~~~~
采用随机梯度法进行前馈神经网络训练的模块,梯度训练使用BP算法
"""
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class gNetwork(object):
def __init__(self, sizes):
"""
sizes:list类型,表示网络结构,比如[2,3,1]表示输入层2个神经元,
一个包含3个神经元的隐层,1个输出层
"""
self.num_layers = len(sizes)
self.sizes = sizes
#初始化网络
self.biases = [np.random.randn(y, 1)fory in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
#为了方便代码编写,weights和biases与网络结构相同,输入层为空即可
self.biases.insert(0,[])
self.weights.insert(0,[])
self.accuracy=[];
def feedforward(self,a,z):
"""Return the output of the network"""
#z=w*x+b,a=sigma(z)
for ik in range(1,self.num_layers):
z[ik] = np.dot(self.weights[ik], a[ik-1])+self.biases[ik]
a[ik] = sigmoid(z[ik])
def SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):
#中间变量,weights和biases的导数,以及激活值a和带权输入z
nabla_biases = self.biases[:]
nabla_weights = self.weights[:]
a = [[]fori in range(self.num_layers)]
z = [[]fori in range(self.num_layers)]
#测试数据
if test_data:
n_test = len(test_data)
x_test = np.squeeze(np.array([d[0]ford in test_data]).transpose())
y_test = np.squeeze(np.array([d[1]ford in test_data]).transpose())
n = len(training_data)
#主循环
for j in range(epochs):
#对样本数据随机排列
random.shuffle(training_data)
#mini_batch
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
#将tuple的数据处理成矩阵形式,这样可以一次计算所有的mini_batch
#比在mini_batch中循环单个样本快很多
x_train = np.squeeze(np.array([x[0]forx in mini_batch])).transpose()
y_train = np.squeeze(np.array([y[1]fory in mini_batch])).transpose()
a[0] = x_train
#前馈
self.feedforward(a,z)
#反向传播误差,并更新模型
self.update_mini_batch(y_train,a,z,nabla_weights,nabla_biases,mini_batch_size,eta)
if test_data:
yp = self.evaluate(x_test,y_test)
self.accuracy.append(yp/n_test)
print("Epoch {%d}: {%d} / {%d}" %(j, self.evaluate(x_test,y_test), n_test))
else:
print("Epoch {%d} complete" %(j))
def update_mini_batch(self,y_train,a,z,nabla_weights,nabla_biases,mini_batch_size,eta):
#计算输出层,公式BP1
delta = (a[-1]-y_train)*sigmoid_prime(z[-1])
nabla_biases[-1][:,0] = np.mean(delta,axis = 1)
nabla_weights[-1] = np.dot(delta,a[-2].transpose())/mini_batch_size
#反向传播误差
for m in range(2,self.num_layers):
#公式BP2
delta = np.dot(self.weights[-m+1].transpose(),delta)*sigmoid_prime(z[-m])
#公式BP3
nabla_biases[-m][:,0] = np.mean(delta,axis = 1)
#公式BP4
nabla_weights[-m] = np.dot(delta,a[-m-1].transpose())/mini_batch_size
#更新模型
for m in range(1,self.num_layers):
self.weights[m] = self.weights[m] - eta*nabla_weights[m];
self.biases[m] = self.biases[m] - eta*nabla_biases[m];
def evaluate(self, x_test,y_test):
a = x_test[:]
for ik in range(1,self.num_layers):
a = sigmoid(np.dot(self.weights[ik], a)+self.biases[ik])
test_result = np.argmax(a,axis = 0);
return sum(int(x == y)for(x, y) in zip(test_result,y_test))
#### Miscellaneous functions
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
s = sigmoid(z)
return s*(1-s)Michael Nielsen 的 network 计算思路是:先把整个训练样本分为若干个mini_batch,再对 mini_batch 内的每个样本进行循序,计算每个样本所对应的误差,最后对 mini_batch 内的样本求和取平均更新模型。
上面的这段代码是一次性计算完整个 mini_batch 的误差,不做
for循环,从而提高了计算效率。
提升一下
下面咱们进一步提高下分类精度,如咱们讨论的那样,利用ReLU激活函数代替
Sigmoid函数,但是需要注意的是,在模型参数初始化的使用
rand()函数而不是
randn()函数。具体程序如下
"""
gnetwork1.py
~~~~~~~~~~
采用随机梯度法进行前馈神经网络训练的模块,梯度训练使用BP算法
中间层采用ReLU激活函数,输出层采用Sigmoid函数
"""
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class gNetwork(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
#初始化网络,注意下这里
self.biases = [np.random.rand(y, 1)-0.5fory in sizes[1:]]
self.weights = [np.random.rand(y, x)-0.5
for x, y in zip(sizes[:-1], sizes[1:])]
#为了方便代码编写,weights和biases与网络结构相同,输入层为空即可
self.biases.insert(0,[])
self.weights.insert(0,[])
self.accuracy=[];
def feedforward(self,a,z):
"""Return the output of the network"""
#z=w*x+b,a=sigma(z)
for ik in range(1,self.num_layers-1):
z[ik] = np.dot(self.weights[ik], a[ik-1])+self.biases[ik]
a[ik] = relu(z[ik])
ik = ik+1
z[ik] = np.dot(self.weights[ik], a[ik-1])+self.biases[ik]
a[ik] = sigmoid(z[ik])
def SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):
#中间变量,weights和biases的导数,以及激活值a和带权输入z
nabla_biases = self.biases[:]
nabla_weights = self.weights[:]
a = [[]fori in range(self.num_layers)]
z = [[]fori in range(self.num_layers)]
#测试数据
if test_data:
n_test = len(test_data)
x_test = np.squeeze(np.array([d[0]ford in test_data]).transpose())
y_test = np.squeeze(np.array([d[1]ford in test_data]).transpose())
n = len(training_data)
#主循环
for j in range(epochs):
#对样本数据随机排列
random.shuffle(training_data)
#mini_batch
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
#将tuple的数据处理成矩阵形式,这样可以一次计算所有的mini_batch
#比在mini_batch中循环单个样本快很多
x_train = np.squeeze(np.array([x[0]forx in mini_batch])).transpose()
y_train = np.squeeze(np.array([y[1]fory in mini_batch])).transpose()
a[0] = x_train
#前馈
self.feedforward(a,z)
#反向传播误差,并更新模型
self.update_mini_batch(y_train,a,z,nabla_weights,nabla_biases,mini_batch_size,eta)
if test_data:
yp = self.evaluate(x_test,y_test)
self.accuracy.append(yp/n_test)
print("Epoch {%d}: {%d} / {%d}" %(j, self.evaluate(x_test,y_test), n_test))
else:
print("Epoch {%d} complete" %(j))
def update_mini_batch(self,y_train,a,z,nabla_weights,nabla_biases,mini_batch_size,eta):
#计算输出层,公式BP1
delta = (a[-1]-y_train)*sigmoid_prime(z[-1])
nabla_biases[-1][:,0] = np.mean(delta,axis = 1)
nabla_weights[-1] = np.dot(delta,a[-2].transpose())/mini_batch_size
#反向传播误差
for m in range(2,self.num_layers):
#公式BP2
delta = np.dot(self.weights[-m+1].transpose(),delta)*relu_prime(z[-m])
#公式BP3
nabla_biases[-m][:,0] = np.mean(delta,axis = 1)
#公式BP4
nabla_weights[-m] = np.dot(delta,a[-m-1].transpose())/mini_batch_size
#更新模型
for m in range(1,self.num_layers):
self.weights[m] = self.weights[m] - eta*nabla_weights[m];
self.biases[m] = self.biases[m] - eta*nabla_biases[m];
def evaluate(self, x_test,y_test):
a = x_test[:]
for ik in range(1,self.num_layers-1):
a = relu(np.dot(self.weights[ik], a)+self.biases[ik])
ik = ik+1
a = sigmoid(np.dot(self.weights[ik], a)+self.biases[ik])
test_result = np.argmax(a,axis = 0);
return sum(int(x == y)for(x, y) in zip(test_result,y_test))
#### Miscellaneous functions
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
s = sigmoid(z)
return s*(1-s)
def relu(z):
"""The Rectifier Linear Unit function."""
a = z[:]
a[a<0] = 0
return a
def relu_prime(z):
"""Derivative of the ReLU function."""
a = z-z
a[z>0] = 1
return a
运行脚本如下:
import mnist_loader
import matplotlib.pyplot as plt
import time
import gnetwork1
#数据载入
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
test_data = list(test_data)
training_data = list(training_data)
#gnetwork1
gnet1 = gnetwork1.gNetwork([784,30,10])
start = time.clock()
gnet1.SGD(training_data,60,100,3.0, test_data=test_data)
print("Time elapsed: ",(time.clock()-start))
#绘图
plt.figure()
plt.plot(gnet1.accuracy,color = "r",label = "network:[784,30,10]")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim([0.94,0.98])
plt.grid(1)
plt.legend()运行结果如下:
在20个epoch以内可以达到96.0%的识别率,最高可以达到96.5%。设置多个隐层后,分辨率稍有提高,偶尔可达到97.0%,但是训练次数太多后就不稳定了,精度反而急剧下降。

相关文章推荐
- 神经网络学习(六)MNIST手写字识别 --- Matlab实现
- 神经网络与深度学习 使用Python实现基于梯度下降算法的神经网络和自制仿MNIST数据集的手写数字分类可视化程序 web版本
- 深度学习-传统神经网络使用TensorFlow框架实现MNIST手写数字识别
- 神经网络与深度学习 1.6 使用Python实现基于梯度下降算法的神经网络和MNIST数据集的手写数字分类程序
- Python神经网络代码识别手写字的实现流程(一):加载mnist数据
- Python实现深度学习之-神经网络识别手写数字(更新中,更新日期:2017-07-12)
- tensorflow 学习笔记7 普通神经网络实现mnist手写识别
- tensorflow 学习笔记12 循环神经网络RNN LSTM结构实现MNIST手写识别
- python Tensorflow三层全连接神经网络实现手写数字识别
- python神经网络案例——FC全连接神经网络实现mnist手写体识别
- 《神经网络与深度学习》第一章 使用神经网络来识别手写数字(三)- 用Python代码实现
- 利用tensorflow一步一步实现基于MNIST 数据集进行手写数字识别的神经网络,逻辑回归
- keras:1)初体验-MLP神经网络实现MNIST手写识别
- 识别MNIST数据集:用Python实现神经网络
- 机器学习之 神经网络的实现(二)-->手写识别
- 识别MNIST数据集之(二):用Python实现神经网络
- 用python的numpy实现神经网络 实现 手写数字识别
- python在线神经网络实现手写字符识别系统
- 手把手入门神经网络系列(2)_74行代码实现手写数字识别
- 【深度学习】笔记2_caffe自带的第一个例子,Mnist手写数字识别代码,过程,网络详解