JAVA实现简单网络爬虫
2018-03-11 21:15
976 查看
这是我第一次写博客,所以写的不算好,看到的人请见谅。
先说一下我的学习经历,JAVA爬虫是我最近才刚开始学会写的,寒假的时候在家一直看罗刚写的那本《自己动手写爬虫》,看了那么久也没什么思路。然后就在网上看别人写的代码,然后看了些直播,慢慢的就会写了,其实写完后才发现,爬虫其实也没那么难。一个爬虫程序,有一个下载HTML页面源码类getHtml(),接着一个解析Html页面源码获得目标内容的类getGoalDate(),如果不是只获得当前页面的内容,还需要一个获得下一个页面网址的类getUrl()。以爬取豆瓣《红海行动》的所有评论为例,目标是爬取所有评论以及发表评论的用户名。
getHtml()类,首先是URL url1=new URL(url);模拟在网页输入网址,接着 URLConnection uc=url1.openConnection();模拟敲回车键打开该网址页面,后面的看注释应该能看懂了。bf.readLine()是依次每行读取页面的源码,
/**
* 下载HTML页面源码
* @author yangjianxin
* @return string @author yangjianxin
* @time 2018-03-09
*/
public static String getHtml(String url,String encoding) {
StringBuffer sb=new StringBuffer();
BufferedReader bf = null;
InputStreamReader isr = null;
try {
//创建网络连接
URL url1=new URL(url);
//打开网络
URLConnection uc=url1.openConnection();
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//建立文件输入流
isr=new InputStreamReader(uc.getInputStream(),encoding);
//高效率读取
bf=new BufferedReader(isr);
//下载页面源码
String temp=null;
while((temp=bf.readLine())!=null) {
sb.append(temp+"\n");
}
//System.out.println(sb.toString());
} catch (MalformedURLException e) {
System.out.println("网页打开失败,请重新输入网址。");
e.printStackTrace();
}catch (IOException e) {
System.out.println("网页打开失败,请检查网络。");
e.printStackTrace();
}finally {
if(bf!=null) {try {
bf.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if(isr!=null) {
try {
isr.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
return sb.toString();
}
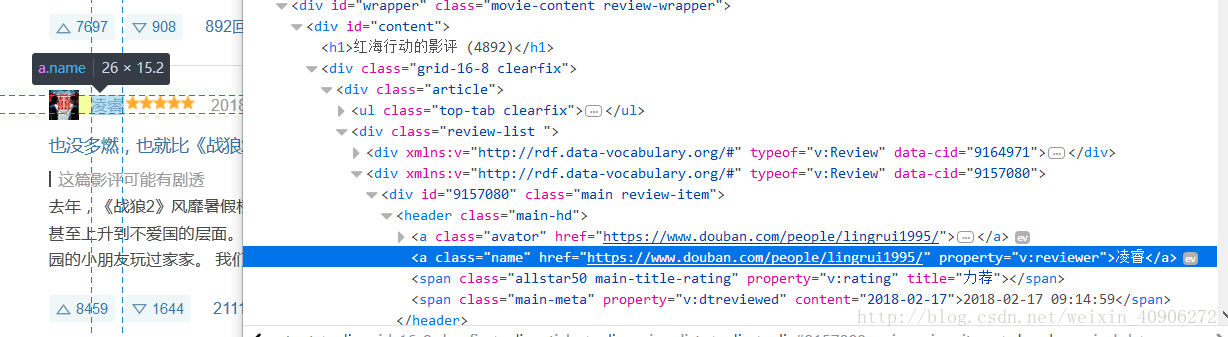
getGoalDate()类,Document document=Jsoup.parse(html),运用Jsoup.parse()解析网页源码,接着就是开始确定自己需要爬取的东西在网页里的位置,这需要我们对html有点了解,能看、读懂网页标签,可以看出当前页面的所有评论都在id为"content"的大盒子里,每条评论都在class名为"main review-item"的小盒子里, for(Element el:elments)是指对象el在当前页面循环去小盒子"main review-item"查找我们要爬取的东西,也就是用户名和评论, String name=el.getElementsByClass("name").text()中的“name”可以在当前盒子里查找到用户名,用.text()将它赋予给变量name,同理评论也是这样抓取,如果不用将它存入磁盘,则可以后面那段文件操作删除,只打印就行
/**
* @author yangjianxin
* @descreption 解析需要的数据,把它存入文件
* @return ArrayList
* @time 2018-03-09
*/
public static String getGoalDate(String url,String encoding,String fileName) {
String html=getHtml(url,encoding);
//解析页面源码
Document document=Jsoup.parse(html);
//根据id名找到装有目标的盒子
Element elment=document.getElementById("content");
//根据class进一步确定目标内容位置
Elements elments=document.getElementsByClass("main review-item");
//循环依次单个拿到目标文件
for(Element el:elments) {
String name=el.getElementsByClass("name").text();
String comment=el.getElementsByClass("short-content").text();
System.out.println("用户名为:"+name+"\n"+"评论:"+comment+"\n");
maps=new ArrayList<String>();
maps.add("用户名为:"+name+"\n"+"评论:"+comment+"\n");
try {
//打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件,如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
FileWriter writer = new FileWriter(fileName, true);
writer.write("用户名为:"+name+"\r\n");
writer.write("评论:"+comment+"\r\n");
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return maps.toString();
}
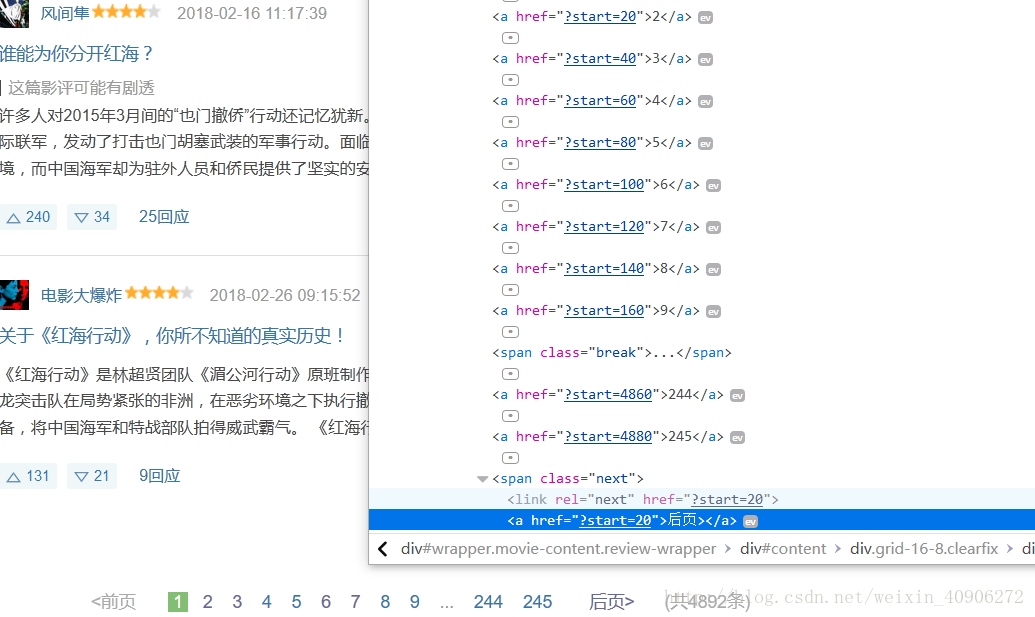
getUrl(),这里需要我们去分析一下网页,就会发现每次下页的网址都是最后两个数字发生改变,且是以20的等差递增,所以可以很容易获得所有评论网页的内容,这里我只爬了80页的评论(也是为了代码运行不发生错误,因为现在网站反爬的能力很强,可能到了后面,就会拒绝你访问该网址。我之前就碰到这样的情况,爬了几次之后,就不能在访问该网址了)
/**
* @descreption 获取当前页面包含的下一个目标网址
* @param url
* @return List<string>
*/
public static List<String> getUrl(String url) {
List<String> hrefList=new ArrayList<String>();
hrefList.add(url);
for(int i=20;i<2000;i+=20) {
hrefList.add("https://movie.douban.com/subject/26861685/reviews?start="+i);
}
return hrefList;
}
最后就是主方法入口了
/**
* @className 入口
* @author yangj
4000
ianxin
* @goal 爬取豆瓣红海行动所有评论
* @href "https://movie.douban.com/subject/26861685/reviews?start=0"
*/
public class main {
public static void main(String[] args) throws FileNotFoundException {
//String html=getHtml("https://movie.douban.com/subject/26861685/reviews?start=0","utf-8");
String url="https://movie.douban.com/subject/26861685/reviews?start=0";
//System.out.println(getUrl("https://movie.douban.com/subject/26861685/reviews").toString()+"\n");
for(int i=0;i<80;i++) {
System.out.println(getGoalDate(getUrl("https://movie.douban.com/subject/26861685/"
+ "reviews?start=0").get(i),"utf-8","honghai-comment"));
//appendMethodB(getGoalDate(getUrl("https://movie.douban.com/subject/26861685/"
//+ "reviews?start=0").get(i),"utf-8"),"honghai-comment");
}
}
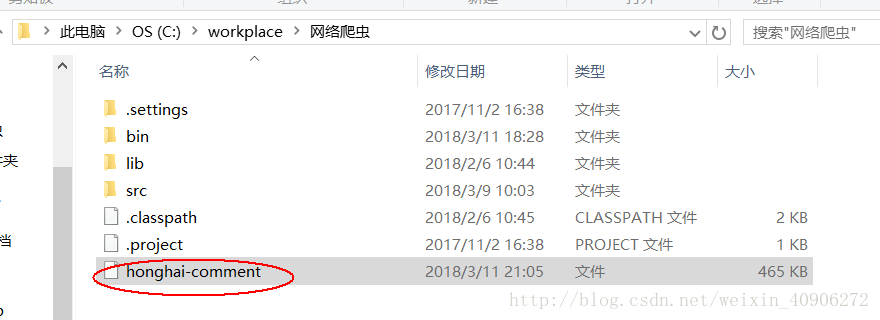
结果:

最后说一下学会写爬虫的收获,做什么事之前都要有一个明确的目标,在学习过程中,绝对不能做存拿来主义,直接去复制粘贴,(我寒假就是直接去网上找代码,找了好多代码,然后运行,虽然能获得结果但却是别人的,并不是自己想要的)长期这样,到头来我们什么都学不会,只有学会了自己去思考,围绕着目标自己慢慢推导,这样我们才能有收获。
先说一下我的学习经历,JAVA爬虫是我最近才刚开始学会写的,寒假的时候在家一直看罗刚写的那本《自己动手写爬虫》,看了那么久也没什么思路。然后就在网上看别人写的代码,然后看了些直播,慢慢的就会写了,其实写完后才发现,爬虫其实也没那么难。一个爬虫程序,有一个下载HTML页面源码类getHtml(),接着一个解析Html页面源码获得目标内容的类getGoalDate(),如果不是只获得当前页面的内容,还需要一个获得下一个页面网址的类getUrl()。以爬取豆瓣《红海行动》的所有评论为例,目标是爬取所有评论以及发表评论的用户名。
getHtml()类,首先是URL url1=new URL(url);模拟在网页输入网址,接着 URLConnection uc=url1.openConnection();模拟敲回车键打开该网址页面,后面的看注释应该能看懂了。bf.readLine()是依次每行读取页面的源码,
/**
* 下载HTML页面源码
* @author yangjianxin
* @return string @author yangjianxin
* @time 2018-03-09
*/
public static String getHtml(String url,String encoding) {
StringBuffer sb=new StringBuffer();
BufferedReader bf = null;
InputStreamReader isr = null;
try {
//创建网络连接
URL url1=new URL(url);
//打开网络
URLConnection uc=url1.openConnection();
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//建立文件输入流
isr=new InputStreamReader(uc.getInputStream(),encoding);
//高效率读取
bf=new BufferedReader(isr);
//下载页面源码
String temp=null;
while((temp=bf.readLine())!=null) {
sb.append(temp+"\n");
}
//System.out.println(sb.toString());
} catch (MalformedURLException e) {
System.out.println("网页打开失败,请重新输入网址。");
e.printStackTrace();
}catch (IOException e) {
System.out.println("网页打开失败,请检查网络。");
e.printStackTrace();
}finally {
if(bf!=null) {try {
bf.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if(isr!=null) {
try {
isr.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
return sb.toString();
}
getGoalDate()类,Document document=Jsoup.parse(html),运用Jsoup.parse()解析网页源码,接着就是开始确定自己需要爬取的东西在网页里的位置,这需要我们对html有点了解,能看、读懂网页标签,可以看出当前页面的所有评论都在id为"content"的大盒子里,每条评论都在class名为"main review-item"的小盒子里, for(Element el:elments)是指对象el在当前页面循环去小盒子"main review-item"查找我们要爬取的东西,也就是用户名和评论, String name=el.getElementsByClass("name").text()中的“name”可以在当前盒子里查找到用户名,用.text()将它赋予给变量name,同理评论也是这样抓取,如果不用将它存入磁盘,则可以后面那段文件操作删除,只打印就行
/**
* @author yangjianxin
* @descreption 解析需要的数据,把它存入文件
* @return ArrayList
* @time 2018-03-09
*/
public static String getGoalDate(String url,String encoding,String fileName) {
String html=getHtml(url,encoding);
//解析页面源码
Document document=Jsoup.parse(html);
//根据id名找到装有目标的盒子
Element elment=document.getElementById("content");
//根据class进一步确定目标内容位置
Elements elments=document.getElementsByClass("main review-item");
//循环依次单个拿到目标文件
for(Element el:elments) {
String name=el.getElementsByClass("name").text();
String comment=el.getElementsByClass("short-content").text();
System.out.println("用户名为:"+name+"\n"+"评论:"+comment+"\n");
maps=new ArrayList<String>();
maps.add("用户名为:"+name+"\n"+"评论:"+comment+"\n");
try {
//打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件,如果为 true,则将字节写入文件末尾处,而不是写入文件开始处
FileWriter writer = new FileWriter(fileName, true);
writer.write("用户名为:"+name+"\r\n");
writer.write("评论:"+comment+"\r\n");
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return maps.toString();
}
getUrl(),这里需要我们去分析一下网页,就会发现每次下页的网址都是最后两个数字发生改变,且是以20的等差递增,所以可以很容易获得所有评论网页的内容,这里我只爬了80页的评论(也是为了代码运行不发生错误,因为现在网站反爬的能力很强,可能到了后面,就会拒绝你访问该网址。我之前就碰到这样的情况,爬了几次之后,就不能在访问该网址了)
/**
* @descreption 获取当前页面包含的下一个目标网址
* @param url
* @return List<string>
*/
public static List<String> getUrl(String url) {
List<String> hrefList=new ArrayList<String>();
hrefList.add(url);
for(int i=20;i<2000;i+=20) {
hrefList.add("https://movie.douban.com/subject/26861685/reviews?start="+i);
}
return hrefList;
}
最后就是主方法入口了
/**
* @className 入口
* @author yangj
4000
ianxin
* @goal 爬取豆瓣红海行动所有评论
* @href "https://movie.douban.com/subject/26861685/reviews?start=0"
*/
public class main {
public static void main(String[] args) throws FileNotFoundException {
//String html=getHtml("https://movie.douban.com/subject/26861685/reviews?start=0","utf-8");
String url="https://movie.douban.com/subject/26861685/reviews?start=0";
//System.out.println(getUrl("https://movie.douban.com/subject/26861685/reviews").toString()+"\n");
for(int i=0;i<80;i++) {
System.out.println(getGoalDate(getUrl("https://movie.douban.com/subject/26861685/"
+ "reviews?start=0").get(i),"utf-8","honghai-comment"));
//appendMethodB(getGoalDate(getUrl("https://movie.douban.com/subject/26861685/"
//+ "reviews?start=0").get(i),"utf-8"),"honghai-comment");
}
}
结果:
最后说一下学会写爬虫的收获,做什么事之前都要有一个明确的目标,在学习过程中,绝对不能做存拿来主义,直接去复制粘贴,(我寒假就是直接去网上找代码,找了好多代码,然后运行,虽然能获得结果但却是别人的,并不是自己想要的)长期这样,到头来我们什么都学不会,只有学会了自己去思考,围绕着目标自己慢慢推导,这样我们才能有收获。

相关文章推荐
- 用URLConnection来实现简单的java网络爬虫
- java 简单网络爬虫实现
- Java简单的网络爬虫实现
- Java语言实现的简单网络爬虫复习
- 关于使用Java实现的简单网络爬虫Demo
- Java简单的网络爬虫实现
- 网络爬虫(三) Java实现简单的网络爬虫
- java实现一个简单的网络爬虫代码示例
- 关于使用Java实现的简单网络爬虫Demo
- Java实现一个简单的网络爬虫
- java+jsoup实现简单网络爬虫
- Java简单的网络爬虫实现
- java 简单网络爬虫实现
- 基于Java的简单网络爬虫的实现--下载Silverlight视频
- 关于使用Java实现的简单网络爬虫Demo
- Java之——简单的网络爬虫实现
- java简单实现网络爬虫
- Java实现简单的网络爬虫
- Java实现简单的网络爬虫(一)
- 搜索引擎----Java实现一个简单的网络爬虫