C/C++程序内存的各种变量存储区域和各个区域详解
2018-03-11 17:57
561 查看
C语言在内存中一共分为如下几个区域,分别是:1. 内存栈区: 存放局部变量名;
2. 内存堆区: 存放new或者malloc出来的对象;
3. 常数区: 存放局部变量或者全局变量的值;
4. 静态区: 用于存放全局变量或者静态变量;
5. 代码区:二进制代码。
知道如上一些内存分配机制,有助于我们理解指针的概念。C/C++不提供垃圾回收机制,因此需要对堆中的数据进行及时销毁,防止内存泄漏,使用free和delete销毁new和malloc申请的堆内存,而栈内存是动态释放。
全局变量、静态局部变量保存在全局数据区,初始化的和未初始化的分别保存在一起;普通局部变量保存在堆栈中;全局变量和局部变量在内存里的区别?
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域(RW), 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(ZI)。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放 (RO)
5、程序代码区—存放函数体的二进制代码。 (RO)
注:1、对于RO、RW和WI的概念不是特别清楚的朋友,可以参考我的另外一篇文章,里边有详细的解释。2、按我个人理解为了减少内存碎片的产生,编译器可能会将堆区又分为block和heap区。block由一系列大小相等的内存块组成。分配内存时先在block中分配,如果block占满则从heap区中分配。同时block的大小和个数可以通过配置文件进行配置,使之达到一个合适的数量。例:/* =========================== */
/* HEAP CONF */
/* =========================== */
/* General configuration for both linear heap and block based heap
* define this list to the size and count of individual fixed-size pools
*/
#define BLOCK_LIST \
/* size count */ \
BLOCK( 22, 80 ) \
BLOCK( 44, 64 ) \
BLOCK( 56, 16 )二、例子程序
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 程序运行时由编译器自动分配,存放函数的参数值,局部变量的值等。 其操作方式类似于数据结构中的栈。
2、堆区(heap) — 在内存开辟另一块存储区域。 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。 注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)—编译器编译时即分配内存。 全局变量和静态变量的存储是放在一块的, 初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后由系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放。
5、程序代码区—存放函数体的二进制代码。
注意:静态局部变量和静态全局变量属于静态存储方式的量不一定就是静态变量。 例如:全局变量虽属于静态存储方式,但不一定是静态变量, 必须由 static加以定义后才能成为静态外部变量,或称静态全局变量。把局部变量改变为静态变量后是改变了它的存储方式,即改变了它的生存期。
把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
静态分配内存:是在程序编译和链接时就确定好的内存。
动态分配内存:是在程序加载、调入、执行的时候分配/回收的内存。
这块内存是共享的,当有多个相同进程(Process)存在时,共用同一个text段。
.data: 也有的地方叫GVAR(global value),用来存放程序中已经初始化的非零全局变量。静态分配。
data又可分为读写(RW)区域和只读(RO)区域。
-> RO段保存常量所以也被称为
-> RW段则是普通非常全局变量,静态变量就在其中
.bss: 存放程序中为初始化的和零值全局变量。静态分配,在程序开始时通常会被清零。
text和data段都在可执行文件中,由系统从可执行文件中加载;而bss段不在可执行文件中,由系统初始化。
这三段内存就组成了我们编写的程序的本体,但是一个程序运行起来,还需要更多的数据和数据间的交互,否则这个程序就是死的,无用的。所以我们还需要为更多的数据和数据交互提供一块内存——堆栈。
Heap: 堆,自由申请的空间,按内存地址由低到高方向生长,其大小由系统内存/虚拟内存上限决定,速度较慢,但自由性大,可用空间大。
每个线程都会有自己的栈,但是堆空间是共用的。
Tips:
2
3
我们可以看到:text、data(gvar)、bss 在内存中地址较低低的位置(low level address),而堆栈则在相对较搞的位置。
堆(Heap)往高地址方向生长,栈(Stack)往低地址方向生长。
在C\C++中,通常可以把内存理解为4个分区:栈、堆、全局/静态存储区和常量存储区。下面我们分别简单地介绍一下各自的特点。
[/align][align=center] [/align][align=center]表2 全局/静态存储区和常量存储区的对比[/align][align=center]
[/align]
l 栈区:主要用来存放局部变量, 传递参数, 存放函数的返回地址。.esp 始终指向栈顶, 栈中的数据越多, esp的值越小。l 堆区:用于存放动态分配的对象, 当你使用 malloc和new 等进行分配时,所得到的空间就在堆中。动态分配得到的内存区域附带有分配信息, 所以你能够 free和delete它们。l 数据区:全局,静态和常量是分配在数据区中的,数据区包括bss(未初始化数据区)和初始化数据区。注意:1) 堆向高内存地址生长;2) 栈向低内存地址生长;3) 堆和栈相向而生,堆和栈之间有个临界点,称为stkbrk。 1、一条进程在内存中的映射 假设现在有一个程序,它的函数调用顺序如下:main(...) ->; func_1(...) ->; func_2(...) ->; func_3(...),即:主函数main调用函数func_1; 函数func_1调用函数func_2; 函数func_2调用函数func_3。当一个程序被操作系统调入内存运行, 其对应的进程在内存中的映射如下图所示:

注意:
l 随着函数调用层数的增加,函数栈帧是一块块地向内存低地址方向延伸的;
l 随着进程中函数调用层数的减少(即各函数调用的返回),栈帧会一块块地被遗弃而向内存的高址方向回缩;
l 各函数的栈帧大小随着函数的性质的不同而不等, 由函数的局部变量的数目决定。
l 未初始化数据区(BSS):用于存放程序的静态变量,这部分内存都是被初始化为零的;而初始化数据区用于存放可执行文件里的初始化数据。这两个区统称为数据区。
l Text(代码区):是个只读区,存放了程序的代码。任何尝试对该区的写操作会导致段违法出错。代码区是被多个运行该可执行文件的进程所共享的。
l 进程对内存的动态申请是发生在Heap(堆)里的。随着系统动态分配给进程的内存数量的增加,Heap(堆)有可能向高址或低址延伸, 这依赖于不同CPU的实现,但一般来说是向内存的高地址方向增长的。
l 在未初始化数据区(BSS)或者Stack(栈区)的增长耗尽了系统分配给进程的自由内存的情况下,进程将会被阻塞, 重新被操作系统用更大的内存模块来调度运行。
l 函数的栈帧:包含了函数的参数(至于被调用函数的参数是放在调用函数的栈帧还是被调用函数栈帧, 则依赖于不同系统的实现)。函数的栈帧中的局部变量以及恢复该函数的主调函数的栈帧(即前一个栈帧)所需要的数据, 包含了主调函数的下一条执行指令的地址。
2、 函数的栈帧
函数调用时所建立的栈帧包含下面的信息:
1) 函数的返回地址。返回地址是存放在主调函数的栈帧还是被调用函数的栈帧里,取决于不同系统的实现;
2) 主调函数的栈帧信息, 即栈顶和栈底;
3) 为函数的局部变量分配的栈空间;
4) 为被调用函数的参数分配的空间取决于不同系统的实现。
注意:
l BSS区(未初始化数据段):并不给该段的数据分配空间,仅仅是记录了数据所需空间的大小。
l DATA(初始化的数据段):为数据分配空间,数据保存在目标文件中。
基本上程序员在开始接触Linux编程时就大抵就都听过代码段、数据段等等概念,它们是各种数据存放的位置。通过objdump -h命令可以查看一个.o文件(已编译成二进制文件但未链接)的各个段:

编译后查看大小:

显然,global_arr数组占据的1M空间并没有占据文件空间。将global_arr数组改放在.data段中:

文件变成了1M多,显然.data段上的数据是占据文件空间的。
(1) 程序中的常量不一定就放在rodata中,有的立即数和指令编码放在.text中
(2) 对于字符串常量,若程序中存在重复的字符串,编译器会保证只存在一个
(3) rodata是在多个进程间共享的
(4) 有的嵌入式系统,rodata放在ROM(或者NOR FLASH)中,运行时直接读取无需加载至RAM( 哈佛和冯诺依曼,从STM32的const全局变量说起有所记录)
想要将数据放在.rodata只需要加上const属性修饰即可。
2. 内存堆区: 存放new或者malloc出来的对象;
3. 常数区: 存放局部变量或者全局变量的值;
4. 静态区: 用于存放全局变量或者静态变量;
5. 代码区:二进制代码。
知道如上一些内存分配机制,有助于我们理解指针的概念。C/C++不提供垃圾回收机制,因此需要对堆中的数据进行及时销毁,防止内存泄漏,使用free和delete销毁new和malloc申请的堆内存,而栈内存是动态释放。
全局变量、静态局部变量保存在全局数据区,初始化的和未初始化的分别保存在一起;普通局部变量保存在堆栈中;全局变量和局部变量在内存里的区别?
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域(RW), 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(ZI)。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放 (RO)
5、程序代码区—存放函数体的二进制代码。 (RO)
注:1、对于RO、RW和WI的概念不是特别清楚的朋友,可以参考我的另外一篇文章,里边有详细的解释。2、按我个人理解为了减少内存碎片的产生,编译器可能会将堆区又分为block和heap区。block由一系列大小相等的内存块组成。分配内存时先在block中分配,如果block占满则从heap区中分配。同时block的大小和个数可以通过配置文件进行配置,使之达到一个合适的数量。例:/* =========================== */
/* HEAP CONF */
/* =========================== */
/* General configuration for both linear heap and block based heap
* define this list to the size and count of individual fixed-size pools
*/
#define BLOCK_LIST \
/* size count */ \
BLOCK( 22, 80 ) \
BLOCK( 44, 64 ) \
BLOCK( 56, 16 )二、例子程序
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b;// 栈
char s[] = "abc"; //"abc"在常量区,s在栈上。
char *p2; //栈
char *p3 = "123456"; //123456\0";在常量区,p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 程序运行时由编译器自动分配,存放函数的参数值,局部变量的值等。 其操作方式类似于数据结构中的栈。
2、堆区(heap) — 在内存开辟另一块存储区域。 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。 注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)—编译器编译时即分配内存。 全局变量和静态变量的存储是放在一块的, 初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后由系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放。
5、程序代码区—存放函数体的二进制代码。
注意:静态局部变量和静态全局变量属于静态存储方式的量不一定就是静态变量。 例如:全局变量虽属于静态存储方式,但不一定是静态变量, 必须由 static加以定义后才能成为静态外部变量,或称静态全局变量。把局部变量改变为静态变量后是改变了它的存储方式,即改变了它的生存期。
把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
楔子
一个可执行程序文件需要在计算机硬件上运行起来,其实质就是静态的文件被加载到内存中的过程,可执行程序文件只是一个程序的载体。那么执行一个应用后,它在内存中是一个怎样的结构呢,请关注今天的走进科学——《C/C++ 程序内存结构》。动&静
一个程序被加载到内存中,这块内存首先就存在两种属性:静态分配内存和动态分配内存。静态分配内存:是在程序编译和链接时就确定好的内存。
动态分配内存:是在程序加载、调入、执行的时候分配/回收的内存。
Text & Data & Bss
.text: 也称为代码段(Code),用来存放程序执行代码,同时也可能会包含一些常量(如一些字符串常量等)。该段内存为静态分配,只读(某些架构可能允许修改)。这块内存是共享的,当有多个相同进程(Process)存在时,共用同一个text段。
.data: 也有的地方叫GVAR(global value),用来存放程序中已经初始化的非零全局变量。静态分配。
data又可分为读写(RW)区域和只读(RO)区域。
-> RO段保存常量所以也被称为
.constdata
-> RW段则是普通非常全局变量,静态变量就在其中
.bss: 存放程序中为初始化的和零值全局变量。静态分配,在程序开始时通常会被清零。
text和data段都在可执行文件中,由系统从可执行文件中加载;而bss段不在可执行文件中,由系统初始化。
这三段内存就组成了我们编写的程序的本体,但是一个程序运行起来,还需要更多的数据和数据间的交互,否则这个程序就是死的,无用的。所以我们还需要为更多的数据和数据交互提供一块内存——堆栈。
堆栈(Heap& Stack)
堆和栈都是动态分配内存,两者空间大小都是可变的。Stack: 栈,存放Automatic Variables,按内存地址由高到低方向生长,其最大大小由编译时确定,速度快,但自由性差,最大空间不大。Heap: 堆,自由申请的空间,按内存地址由低到高方向生长,其大小由系统内存/虚拟内存上限决定,速度较慢,但自由性大,可用空间大。
每个线程都会有自己的栈,但是堆空间是共用的。
Tips:
char* p = new char[20]; // 这行代码在Heap中开辟了20个char长度的空间,同时在Stack上压入了p, // 指针变量p存在于栈上,其值为刚刚在堆上开辟的空间的首地址。1
2
3
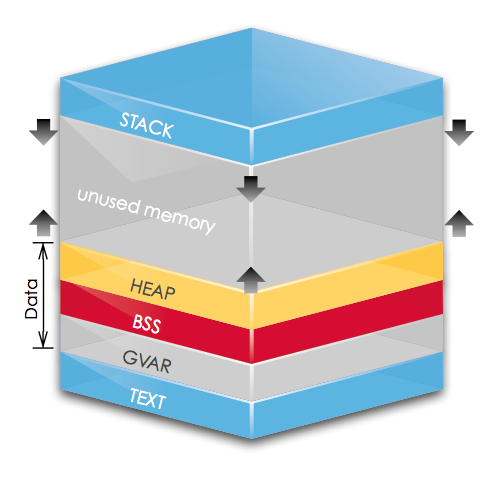
图解
在 sw-at 的博客上扒了一张图,这张图中所示内存空间,地址由下往上增长,分别标示了 .text、.data、.bss、stack和heap的内存分部情况。我们可以看到:text、data(gvar)、bss 在内存中地址较低低的位置(low level address),而堆栈则在相对较搞的位置。
堆(Heap)往高地址方向生长,栈(Stack)往低地址方向生长。
在C\C++中,通常可以把内存理解为4个分区:栈、堆、全局/静态存储区和常量存储区。下面我们分别简单地介绍一下各自的特点。
1 栈
通常是用于那些在编译期间就能确定存储大小的变量的存储区,用于在函数作用域内创建,在离开作用域后自动销毁的变量的存储区。通常是局部变量,函数参数等的存储区。他的存储空间是连续的,两个紧密挨着定义的局部变量,他们的存储空间也是紧挨着的。栈的大小是有限的,通常Visual C++编译器的默认栈的大小为1MB,所以不要定义int a[1000000]这样的超大数组。2 堆
通常是用于那些在编译期间不能确定存储大小的变量的存储区,它的存储空间是不连续的,一般由malloc(或new)函数来分配内存块,并且需要用free(delete)函数释放内存。如果程序员没有释放掉,那么就会出现常说的内存泄漏问题。需要注意的是,两个紧挨着定义的指针变量,所指向的malloc出来的两块内存并不一定的是紧挨着的,所以会产生内存碎片。另外需要注意的一点是,堆的大小几乎不受限制,理论上每个程序最大可达4GB。3 全局/静态存储区
和“栈”一样,通常是用于那些在编译期间就能确定存储大小的变量的存储区,但它用于的是在整个程序运行期间都可见的全局变量和静态变量。4 常量存储区
和“全局/静态存储区”一样,通常是用于那些在编译期间就能确定存储大小的常量的存储区,并且在程序运行期间,存储区内的常量是全局可见的。这是一块比较特殊的存储去,他们里面存放的是常量,不允许被修改。5 总结
根据上面的内容,分别将栈和堆、全局/静态存储区和常量存储区进行对比,结果如下。表1 栈和堆的对比[align=left]| 栈 | 堆 | |
| 存储内容 | 局部变量 | 变量 |
| 作用域 | 函数作用域、语句块作用域 | 函数作用域、语句块作用域 |
| 编译期间大小是否确定 | 是 | 否 |
| 大小 | 1MB | 4GB |
| 内存分配方式 | 地址由高向低减少 | 地址由低向高增加 |
| 内容是否可以修改 | 是 | 是 |
| 全局/静态存储区 | 常量存储区 | |
| 存储内容 | 全局变量、静态变量 | 常量 |
| 编译期间大小是否确定 | 是 | 是 |
| 内容是否可以修改 | 是 | 否 |
l 栈区:主要用来存放局部变量, 传递参数, 存放函数的返回地址。.esp 始终指向栈顶, 栈中的数据越多, esp的值越小。l 堆区:用于存放动态分配的对象, 当你使用 malloc和new 等进行分配时,所得到的空间就在堆中。动态分配得到的内存区域附带有分配信息, 所以你能够 free和delete它们。l 数据区:全局,静态和常量是分配在数据区中的,数据区包括bss(未初始化数据区)和初始化数据区。注意:1) 堆向高内存地址生长;2) 栈向低内存地址生长;3) 堆和栈相向而生,堆和栈之间有个临界点,称为stkbrk。 1、一条进程在内存中的映射 假设现在有一个程序,它的函数调用顺序如下:main(...) ->; func_1(...) ->; func_2(...) ->; func_3(...),即:主函数main调用函数func_1; 函数func_1调用函数func_2; 函数func_2调用函数func_3。当一个程序被操作系统调入内存运行, 其对应的进程在内存中的映射如下图所示:
注意:
l 随着函数调用层数的增加,函数栈帧是一块块地向内存低地址方向延伸的;
l 随着进程中函数调用层数的减少(即各函数调用的返回),栈帧会一块块地被遗弃而向内存的高址方向回缩;
l 各函数的栈帧大小随着函数的性质的不同而不等, 由函数的局部变量的数目决定。
l 未初始化数据区(BSS):用于存放程序的静态变量,这部分内存都是被初始化为零的;而初始化数据区用于存放可执行文件里的初始化数据。这两个区统称为数据区。
l Text(代码区):是个只读区,存放了程序的代码。任何尝试对该区的写操作会导致段违法出错。代码区是被多个运行该可执行文件的进程所共享的。
l 进程对内存的动态申请是发生在Heap(堆)里的。随着系统动态分配给进程的内存数量的增加,Heap(堆)有可能向高址或低址延伸, 这依赖于不同CPU的实现,但一般来说是向内存的高地址方向增长的。
l 在未初始化数据区(BSS)或者Stack(栈区)的增长耗尽了系统分配给进程的自由内存的情况下,进程将会被阻塞, 重新被操作系统用更大的内存模块来调度运行。
l 函数的栈帧:包含了函数的参数(至于被调用函数的参数是放在调用函数的栈帧还是被调用函数栈帧, 则依赖于不同系统的实现)。函数的栈帧中的局部变量以及恢复该函数的主调函数的栈帧(即前一个栈帧)所需要的数据, 包含了主调函数的下一条执行指令的地址。
2、 函数的栈帧
函数调用时所建立的栈帧包含下面的信息:
1) 函数的返回地址。返回地址是存放在主调函数的栈帧还是被调用函数的栈帧里,取决于不同系统的实现;
2) 主调函数的栈帧信息, 即栈顶和栈底;
3) 为函数的局部变量分配的栈空间;
4) 为被调用函数的参数分配的空间取决于不同系统的实现。
注意:
l BSS区(未初始化数据段):并不给该段的数据分配空间,仅仅是记录了数据所需空间的大小。
l DATA(初始化的数据段):为数据分配空间,数据保存在目标文件中。
基本上程序员在开始接触Linux编程时就大抵就都听过代码段、数据段等等概念,它们是各种数据存放的位置。通过objdump -h命令可以查看一个.o文件(已编译成二进制文件但未链接)的各个段:
1. 代码段(.txt)
.txt段存放代码(如函数)与部分整数常量,.txt段的数据可以被执行2. 数据段(.data)
.data用于存放初始化过的全局变量。若全局变量值为0,为了优化编译器会将它放在.bss段中3. bss段(.bss)
.bss段被用来存放那些没有初始化或者初始化为0的全局变量。bss段只占运行时的内存空间而不占文件空间。在程序运行的整个周期内,.bss段的数据一直存在 .data和.bss段的区别可以通过下面程序验证:#include <stdio.h>
char global_arr[1024 * 1024]; //存放在.bss段
int main(void)
{
return 0;
}编译后查看大小:
显然,global_arr数组占据的1M空间并没有占据文件空间。将global_arr数组改放在.data段中:
char global_arr[1024 * 1024] = {4}; //存放在.data段 编译后查看大小: 文件变成了1M多,显然.data段上的数据是占据文件空间的。
4. 常量数据段(.rodata)
ro表read only,用于存放不可变修改的常量数据,一旦程序中对其修改将会出现段错误:(1) 程序中的常量不一定就放在rodata中,有的立即数和指令编码放在.text中
(2) 对于字符串常量,若程序中存在重复的字符串,编译器会保证只存在一个
(3) rodata是在多个进程间共享的
(4) 有的嵌入式系统,rodata放在ROM(或者NOR FLASH)中,运行时直接读取无需加载至RAM( 哈佛和冯诺依曼,从STM32的const全局变量说起有所记录)
想要将数据放在.rodata只需要加上const属性修饰即可。
5. 栈
栈是用于存放临时变量和函数调用的。栈也是一种先进后出的数据结构,函数的递归调用正得益于栈的存在。需注意存在栈的数据只在当前函数和子函数中有效,一旦函数返回数据将会被自动释放。6. 堆
堆的使用周期有使用者控制,程序中的内存泄漏多因程序员对堆的管理不当引起,需谨慎。7. .comment段
在上图中还看到.comment段,它存放的是编译器版本等信息。除了.comment,还有.note、.hash等其他段,了解即可。
相关文章推荐
- 程序内存情况及变量存储区域(转载)
- C++变量在内存中的存储区域
- Linux下C/C++程序内存布局 各种类型数据存储区域及生长方向
- C++变量在内存中的存储区域
- c++变量在内存中的存储区域
- c++变量在内存中的存储区域
- C++中各种类型的变量的存储区域和作用域
- c++变量在内存中的存储区域(转)
- C/C++学习(8)变量在内存中的存储位置
- C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区
- 探讨C++ 变量生命周期、栈分配方式、类内存布局、Debug和Release程序的区别2
- C/C++程序的内存分配(变量存储)
- C++ 内存中 常见数据存储区域
- C/C++变量在内存中的存储
- 【Linux C/C++系列教程】 第一讲 HelloWorld程序内存分区详解
- Java中变量,对象,字符串等在内存中的存储区域
- C/C++程序内存分配详解
- C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区
- C/C++程序内存分配详解
- iOS开发程序中各种变量的存储位置和程序返回变量的问题