Python语言元素
2018-03-10 12:31
232 查看
这一篇讲讲编程语言中的两种编程思想中的面向过程。
何为面向过程? 面向对象编程(简称为OPP,也称为函数)是一种解决软件复用的设计和编程方法。 这种方法把软件系统中相近相似的操作逻辑和操作 应用数据、状态,以类的型式描述出来,以对象实例的形式在软件系统中复用,以达到提高软件开发效率的作用。函数定义语法:def 函数名(形参): 函数体 return(是否需要返回值) #调用函数 函数名(实参)何为面向对象? 面向对象编程(简称: OOP) 至今还没有统一的概念 我这里把它定义为: 按人们 认识客观世界的系统思维方式,采用基于对象(实体)的概念建立模型,模拟客观世界分析、设 计、实现软件的办法。 面向对象编程有两个非常重要的概念:类和对象类就相当于制造飞机时的图纸,用它来进行创建的飞机就相当于对象类: 类是对象的蓝图和模板 有了类就可以创建对象 定义类需要做两件事情: 数据抽象和行为抽象 数据抽象 - 抽取对象共同的静态特征(找名词) - 属性 行为抽象 - 抽取对象共同的动态特征(找动词) - 方法 定义类的关键字 - class - 类名(每个单词首字母大写)对象: 类的实例化,通过对象实现类方法的调用 某一个具体事物的存在 ,在现实世界中可以是看得见摸得着的。可以是直接使用的。语法:
class 类名(父类名): #内置方法 def __init__(self,形参): self.形参 = 形参 #类方法 def 方法名(self,形参): 方法体 变量名 = 类名(实参) #类的实例化(创建对象) 变量名.方法名(实参)类和对象的关系:
毕竟函数式编程(面向过程)才是主题,面向对象就这些,剩下的还是下次讲吧
Python的函数与其他编程语言的函数并不相同。 比如java(有幸看过一点java的教程)。java的函数有一个函数重载的设置,java的函数重载是函数名相同,但是是以函数形参数量不同以及类型不同来区分。 但是Python的函数相对简单。在Python中定义一个函数可以相当java的多个函数,Python的函数支持参数默认值,不定长参数…… 重要的是Python中的实参并不区分数据类型,这就可以使得Python可以用一个变量储存多种数据。函数无重载,或许这也是Python代的一个坑。 在Python中函数没有重载的概念,所以如果在一个.py文件有两个同名的函数的话,后定义者会覆盖前定义者。也就是说在一个.py文件中,同名函数只存在一个。 那有人就会说了,这是猪吗?那我就想说了,多人协作的项目呢? 其实也好解决,可以用import来区分。代码如下:import foomodule1.foo() # 输出hello, world!import foomodule2.foo() # 输出goodbye, world!或者下面这样
import module1 as m1import module2 as m2m1.foo()m2.foo()然后,如果你导入的是自己的.py文件当做模块的话,就会遇到下一个坑。在Python中使用import导入非官方非第三方的模块的话(其实就是想说自己的),就会发现除了调用的可执行函数之外还有代码执行。不得不感慨一句:哪条路上都有坑,Python编程也一样。这种时候我们就可以使用一些Python内置的函数来解决,代码如下:
def foo():passdef bar():pass# __name__是Python中一个隐含的变量它代表了模块的名字# 只有被Python解释器直接执行的模块的名字才是__main__#否则是被调用函数的文件名
if __name__ == '__main__':print('call foo()')foo()print('call bar()')bar() 函数变量的作用域 在使用函数的时候我们通常会用到变量,而变量可以大致分为全局变量和局部变量两种。全局变量就是公共汽车,谁都能用的但是要想下面这样声明一下:def foo():global a #全局变量声明a = 200print(a) # 200if __name__ == '__main__':a = 100foo()print(a) # 200全局变量没有global声明是无法改变的(不可变数据类型),就像坐公交还得给两块呢。谁还没点格调呢值得注意的是,如果没有全局变量还指定了global,那么global指定的那个变量就会成为全局变量,所以还是少用吧 至于局部变量则会因为函数之间相互嵌套而出现分支。如果在一个函数中还嵌套了一个函数,并且内层函数没有变量或者想使用上一层函数的局部变量的话可以使用nonlocal来声明:
def fo():a = 200print(a) # 200def foo():nonlocal a #声明使用上层函数的变量a = 300print(a) #300if __name__ == '__main__':fo()foo()print(a) # 300作用域的执行顺序是:局部作用域 - 嵌套作用域 -全局作用域 - 内置作用域 OK,让我们转个弯来了解一下Python常用的数据类型 字符串 字符串是由0个到N个的字母,数字组成的一串字符。字符串在Python中是一种不可变数据类型。字符串的使用:
def main():str1 = 'hello, world!'# 通过len函数计算字符串的长度print(len(str1)) # 13# 获得字符串首字母大写的拷贝print(str1.capitalize()) # Hello, world!# 获得字符串变大写后的拷贝print(str1.upper()) # HELLO, WORLD!# 从字符串中查找子串所在位置print(str1.find('or')) # 8print(str1.find('shit')) # -1# 与find类似但找不到子串时会引发异常# print(str1.index('or'))# print(str1.index('shit'))# 检查字符串是否以指定的字符串开头print(str1.startswith('He')) # Falseprint(str1.startswith('hel')) # True# 检查字符串是否以指定的字符串结尾print(str1.endswith('!')) # True# 将字符串以指定的宽度居中并在两侧填充指定的字符print(str1.center(50, '*'))# 将字符串以指定的宽度靠右放置左侧填充指定的字符print(str1.rjust(50, ' '))str2 = 'abc123456'# 从字符串中取出指定位置的字符(下标运算)print(str2[2]) # c# 字符串切片(从指定的开始索引到指定的结束索引)print(str2[2:5]) # c12print(str2[2:]) # c123456print(str2[2::2]) # c246print(str2[::2]) # ac246print(str2[::-1]) # 654321cbaprint(str2[-3:-1]) # 45# 检查字符串是否由数字构成print(str2.isdigit()) # False# 检查字符串是否以字母构成print(str2.isalpha()) # False# 检查字符串是否以数字和字母构成print(str2.isalnum()) # Truestr3 = ' jackfrued@126.com 'print(str3)# 获得字符串修剪左右两侧空格的拷贝print(str3.strip())if __name__ == '__main__':main() 字符串操作分两种:一种是函数(len(str)),一种是方法(str.sort()) 元祖 元祖与列表类似,但是元祖是一种不可变数据类型(拿它做全局变量除了转换数据类型,不然谁都改不了,耶稣来了都不好使),列表是可变数据类型元祖使用:def main():# 定义元组t = ('骆昊', 38, True, '四川成都')print(t)# 获取元组中的元素print(t[0])print(t[3])# 遍历元组中的值for member in t:print(member)# 重新给元组赋值# t[0] = '王大锤' # TypeError# 变量t重新引用了新的元组原来的元组将被垃圾回收t = ('王大锤', 20, True, '云南昆明')print(t)# 将元组转换成列表person = list(t)print(person)# 列表是可以修改它的元素的person[0] = '李小龙'person[1] = 25print(person)# 将列表转换成元组fruits_list = ['apple', 'banana', 'orange']fruits_tuple = tuple(fruits_list)print(fruits_tuple)if __name__ == '__main__':main() 集合 Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。 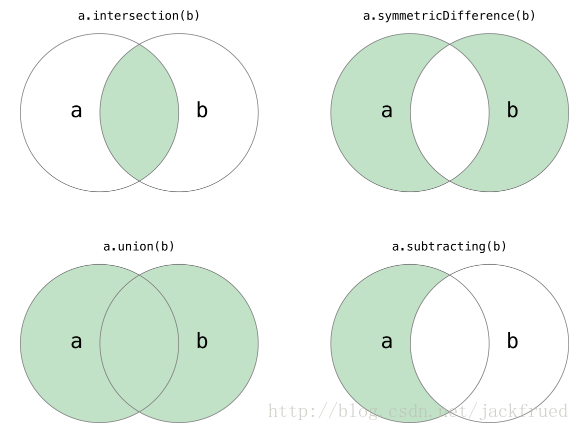 集合使用:
集合使用:def main():set1 = {1, 2, 3, 3, 3, 2}print(set1)print('Length =', len(set1))set2 = set(range(1, 10))print(set2)set1.add(4)set1.add(5)set2.update([11, 12])print(set1)print(set2)set2.discard(5)# remove的元素如果不存在会引发KeyErrorif 4 in set2:set2.remove(4)print(set2)# 遍历集合容器for elem in set2:print(elem ** 2, end=' ')print()# 将元组转换成集合set3 = set((1, 2, 3, 3, 2, 1))print(set3.pop())print(set3)# 集合的交集、并集、差集、对称差运算print(set1 & set2)# print(set1.intersection(set2))print(set1 | set2)# print(set1.union(set2))print(set1 - set2)# print(set1.difference(set2))print(set1 ^ set2)# print(set1.symmetric_difference(set2))# 判断子集和超集print(set2 <= set1)# print(set2.issubset(set1))print(set3 <= set1)# print(set3.issubset(set1))print(set1 >= set2)# print(set1.issuperset(set2))print(set1 >= set3)# print(set1.issuperset(set3))if __name__ == '__main__':main() 字典 字典在python中是一种可变数据类型,但是跟列表,元祖不同的是:字典储存数据的方式是键值对为一个元素,键和值用 : 号分割字典的使用:def main():scores = {'骆昊': 95, '白元芳': 78, '狄仁杰': 82}# 通过键可以获取字典中对应的值print(scores['骆昊'])print(scores['狄仁杰'])# 对字典进行遍历(遍历的其实是键再通过键取对应的值)for elem in scores:print('%s\t--->\t%d' % (elem, scores[elem]))# 更新字典中的元素scores['白元芳'] = 65scores['诸葛王朗'] = 71scores.update(冷面=67, 方启鹤=85)print(scores)if '武则天' in scores:print(scores['武则天'])print(scores.get('武则天'))# get方法也是通过键获取对应的值但是可以设置默认值print(scores.get('武则天', 60))# 删除字典中的元素print(scores.popitem())print(scores.popitem())print(scores.pop('骆昊', 100))# 清空字典scores.clear()print(scores)if __name__ == '__main__':main()以上大致就是面向过程编程方式的实例以及一些在这过程会用到的数据类型的具体使用,感谢Python,感谢老骆

相关文章推荐
- [置顶] Python开发系列课程(2) - 语言元素
- 【脚本语言系列】关于Python基本元素,你需要知道的事
- 12.Selenium2 自动化测试实战-基于Python语言-定位一组元素
- Python3基础 list 推导式 生成与已知列表等长度+元素为0的列表
- Python+Selenium练习篇之6-利用class name定位元素
- 分分钟学会一门语言之Python篇 (转载)
- python selenium系列(二)元素定位方式
- 3.面向对象的解释语言python
- python语言学习笔记(二)------判断输入密码强弱
- 一天时间用python写门语言
- Python语言中的类型之字符串型--Python(11)
- 获取数字特定因子元素的个数 分类: python 小练习 2013-12-02 16:57 250人阅读 评论(0) 收藏
- 使用python脚本语言实现快速打包
- [Python] 解释型语言 VS 编译型语言
- python中删除列表中的空元素以及如何读取excel中的数据
- Python删除list中的元素
- 人工智能标配语言Python纳入2018高考科目!
- 实例讲解hadoop中的map/reduce查询(python语言实现)
- 1.Selenium2 自动化测试实战-基于Python语言-设置窗口大小、调用JS调整滚动条、截取图片
- 用python语言实现冒泡排序算法