Java 8-stream实现原理分析(一)
2018-03-07 14:43
525 查看
背景介绍
Spliterator和Iterator
Iterator
Spliterator
流来源
实现方式
代码分析
Sink执行分析
filter的begin()
map的begin()
sorted的begin()
filter的accpet()
map的accpet()
sorted的accpet()
filter的end()
map的end()
sorted的end()
ReduceOp的相关方法
总结
参考
Iterator 有两个方法:
此外,这种两方法协议通常需要一定水平的有状态性,比如前窥 (peek ahead ) 一个元素(并跟踪您是否已前窥)。这些要求累积形成了大量的每元素访问开销。
第一个问题比较容易理解,第二个问题就是因为
使用boolean tryAdvance(Consumer);代替
不再提供
提供Spliterator trySplit();将自身一分为二,支持并发
深入理解Java Stream流水线
由于直到终端操作才会执行真正的运算,直接看到
可能到这里就有些疑惑了,为什么
看到这里,我们就可以解释上面的问题了:
由于sorted是一个有状态的中间操作,在sorted完成之前,不能传递给downStream,只有在sorted的end()中才可传递给downStream
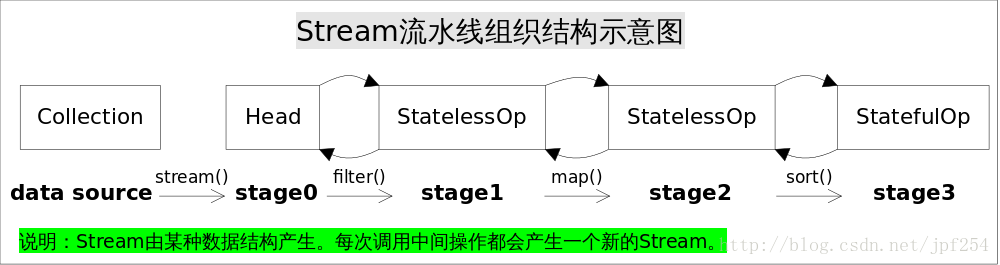

不足
尚未分析并行时如何执行
示例代码中的终端操作时非短路操作,没有看出
《深入理解Java函数式编程》系列文章
深入理解Java Stream流水线
Spliterator和Iterator
Iterator
Spliterator
流来源
实现方式
代码分析
Sink执行分析
filter的begin()
map的begin()
sorted的begin()
filter的accpet()
map的accpet()
sorted的accpet()
filter的end()
map的end()
sorted的end()
ReduceOp的相关方法
总结
参考
背景介绍
Java 8中引入了lambda和
stream,极大的简化了代码编写工作,但是简单的代码为何能实现如何丰富的功能,其背后又是如何实现的呢?
Spliterator和Iterator
Iterator
Iterator是Java中的第二个迭代器接口,在Java 1.2就已存在,相比
Enumeration方法名更简短,还增加了
remove()方法,但是
Iterator始终存在两个问题:
Iterator 有两个方法:
hasNext()和
next();访问下一个元素可能涉及到(但不需要)调用这两个方法。因此,正确编写 Iterator 需要一定量的防御性和重复性编码。(如果客户端没有在调用 next() 之前调用 hasNext() 会怎么样?如果它调用 hasNext() 两次会怎么样?)
此外,这种两方法协议通常需要一定水平的有状态性,比如前窥 (peek ahead ) 一个元素(并跟踪您是否已前窥)。这些要求累积形成了大量的每元素访问开销。
第一个问题比较容易理解,第二个问题就是因为
Iterator中有
remove()方法存在,若要在
Iterator循环中使用
remove(),就一定要记录前一个元素(即前窥 一个元素),比如在
ArrayList.Itr中除了有
cursor代表下一个要访问的元素下标外,还有
lastRet记录上一个访问元素的下标.
Spliterator
Spliterator(splitable iterator可分割迭代器)是Java 中引进的第三个迭代器接口
使用boolean tryAdvance(Consumer);代替
hasNext()和
next()
不再提供
remove()方法
提供Spliterator trySplit();将自身一分为二,支持并发
流来源
Spliterator即为流来源实现方式
本来还想继续写下去,但是发现再如何写也无法超越我当时学习时看的博客,暂时放弃.深入理解Java Stream流水线
代码分析
下面以一段代码示例分析下stream的源码public class StreamDemo {
public static void main(String[] args) {
List<String> strings = List.of("Apple", "bug", "ABC", "Dog");
strings = new ArrayList<>(strings);
OptionalInt max
= strings.stream()
//无状态中间操作
.filter(s -> s.startsWith("A"))
//无状态中间操作
.mapToInt(String::length)
//有状态中间操作
.sorted()
//非短路终端操作
.max();
}
}由于直到终端操作才会执行真正的运算,直接看到
max(),max其实是reduce操作,最后会调用
ReduceOp.evaluateSequential()
/**
* @param helper 终端操作的前一个中间操作,通过调用"helper.wrapSink()"将"sink"构造成链
* @param spliterator 流来源,即ArrayList.Spliterator()
*/
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}/**
*
* @param sink ReduceOp调用makeSink()获得的Sink
*/
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//从最后一个stage直到第一个stage向前调用每个stage的opWrapSink()将sink构造成链
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}opWrapSink()是个抽象方法,我们看下
filter()的
opWrapSink()如何实现
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
/**
*
* @param flags 下一个sink的标志位,供优化使用
* @param sink 下一个sink,通过此参数将sink构造成单链
* @return 当前中间操作关联的sink
*/
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
//Sink.ChainedReference是Sink接口的默认实现,仅调用下一个sink的相应方法
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}opWrapSink()根据
下一个sink和
flags构造
当前sink,并将
当前sink返回,便于构成
sink链
/**
*
* @param wrappedSink 调用wrapSink()返回的结果,即"第一个sink"
* @param spliterator 流来源
*/
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//依次调用begin()-->accept()-->end(),由于sink已经链接在一起,可以调用下一个sink的相应方法
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemai
cf3e
ning(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}copyInto()依次调用
第一个sink的
begin(),
accept(),
end(),此时终端操作结果存放在
最后一个sink中,返回终端操作结果即可.
Sink执行分析
接下来我们分析下4个sink(3个中间操作+1个终端操作)之间是如何协作的filter的begin()
@Override
public void begin(long size) {
//什么都不做,仅仅调用dowStream.begin(),由于不确定传给downStream的元素个数是多少,因此用参数"-1"代表不确定
downstream.begin(-1);
}map的begin()
@Override
public void begin(long size) {
//也是什么都不做,但是map不会减少传给downStream的数据个数,参数依然是"size"
downstream.begin(size);
}sorted的begin()
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
//初始化相关的参数,不在传给downStream
b = (size > 0) ? new SpinedBuffer.OfInt((int) size) : new SpinedBuffer.OfInt();
}filter的accpet()
@Override
public void accept(P_OUT u) {
//只有通过predicate.test(u)才会传递给downStream
if (predicate.test(u))
downstream.accept(u);
}map的accpet()
@Override
public void accept(P_OUT u) {
//执行map操作
downstream.accept(mapper.applyAsInt(u));
}sorted的accpet()
@Override
public void accept(int t) {
//调用b.accept(t),b是SpinedBuffer类型,暂不分析
//同样并未传递给downStream
b.accept(t);
}可能到这里就有些疑惑了,为什么
sorted stage一直没有调用
ReduceOp sink的相关方法?我们带着这个疑问继续.
filter的end()
@Override
public void end() {
//简单传递
downstream.end();
}map的end()
@Override
public void end() {
//同样是简单传递
downstream.end();
}sorted的end()
@Override
public void end() {
int[] ints = b.asPrimitiveArray();
Arrays.sort(ints);
//传递
downstream.begin(ints.length);
if (!cancellationWasRequested) {
for (int anInt : ints)
//传递
downstream.accept(anInt);
}
else {
for (int anInt : ints) {
if (downstream.cancellationRequested()) break;
downstream.accept(anInt);
}
}
//传递
downstream.end();
}看到这里,我们就可以解释上面的问题了:
由于sorted是一个有状态的中间操作,在sorted完成之前,不能传递给downStream,只有在sorted的end()中才可传递给downStream
ReduceOp的相关方法
...
public void begin(long size) {
empty = true;
//state保存最后的max结果,初始为0
state = 0;
}
@Override
public void accept(int t) {
if (empty) {
empty = false;
state = t;
}
else {
//operator就是Math::max,state存放最大值
state = operator.applyAsInt(state, t);
}
}
...总结
stream的中间操作会构造一个stage链,在遇到终端操作时才会真正执行
wrapSink()–>当遇到终端操作时,
最后一个stage调用
wrapSink(),将最后一个
stage直到
第一个stage向前调用每个
stage的
opWrapSink()将
sink构造成链
copyInto–>
sink链构造完毕后,依次调用
第一个sink的
begin(),
accept(),
end(),执行完毕后终端操作结果存放在
最后一个sink中,返回终端操作结果即可
不足
尚未分析并行时如何执行
示例代码中的终端操作时非短路操作,没有看出
Sink.cancellationRequested()的作用
参考
Streams 的幕后原理《深入理解Java函数式编程》系列文章
深入理解Java Stream流水线

相关文章推荐
- Java NIO原理 图文分析及代码实现
- Java NIO原理 图文分析及代码实现
- KMP模式匹配算法原理分析、next数组优化及java实现
- Java NIO原理 图文分析及代码实现
- Java NIO原理图文分析及代码实现<转>
- Java NIO原理图文分析及代码实现
- Java NIO原理 图文分析及代码实现
- [Java基础要义] HashMap的设计原理和实现分析
- Java学习资料-HashMap实现原理分析
- Java java.util.HashMap实现原理源码分析
- Java NIO原理 图文分析及代码实现
- Java对象池技术的原理及其实现 --Java对象的生命周期分析
- Java NIO原理图文分析及代码实现
- Java NIO原理图文分析及代码实现
- Java NIO原理 图文分析及代码实现
- Java NIO原理 图文分析及代码实现
- Java NIO原理 图文分析及代码实现
- (10) java源码分析 ---- HashMap源码分析 及其 实现原理分析
- Java NIO原理 图文分析及代码实现
- 利用JAVA的动态属性之反射原理实现一个简单AOP容器 - AOP的实现原理分析