备战校招必备的计算机网络知识(一)
2018-03-02 11:11
260 查看
这些知识点是我看了不少面经,以及查了不少资料总结的,大概率会考到这些,目前我也正在每天牢记,希望这些能帮助到您,也可以提出宝贵意见!

1、端口号:用来标识同一台计算机的不同的应用进程。1)源端口:源端口和IP地址的作用是标识报文的返回地址。2)目的端口:端口指明接收方计算机上的应用程序接口。TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。2、序号和确认号:是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。例如:一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
4.窗口大小(2字节):TCP流量控制通过连接的每一端声明窗口大小进行控制(接收缓冲区大小) 20 00(00100000 00000000)= 8192 由于2字节能够表示的最大正整数为65535,故窗口最大值为65535u16位检验和:检验和覆盖了整个的TCP报文段: TCP首部和TCP数据。这是一个强制性的字段,一定是由发端计算和存储,并由收端进行验证。u16位紧急指针:注:一般不使用。只有当U R G标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。
2. UDP报头格式UDP有两个字段:数据字段和首部字段 用户数据报UDP有两个字段:数据字段和首部字段。首部字段很简单
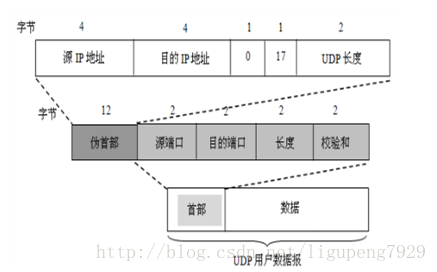
1. 源端口:源端口号。在需要对方回信时选用,不需要时可用全0.
2. 目的端口:目的端口号。这在终点交付报文时必须要使用到。
3. 长度: UDP用户数据报的长度,其最小值是8(仅有首部)。
UDP用户数据报首部中检验和的计算方法有些特殊。在计算检验时,要在UDP用户数据报之前增加12个字的伪首部。
所谓“伪首部”是因为这种伪首部并不是UDP用户数据报真正的首部。只在计算检验和时,临时添加在UDP用户数据报前面,得到一个临时的UDP用户数据报。2. http协议的报文格式
* 请求方法主要有GET和POST两种
GET:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源。
POST:要求被请求服务器接受附在请求后面的数据,常用于提交表单。当浏览器向服务器发送一个请求到Web服务器,它发送一个数据块,或请求信息,HTTP请求信息包括3部分:请求方法URI协议/版本;请求头(Request Header);请求正文;
1>. http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
2>. https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
3>. 原因是,https要比http更加安全一些,也就是说http协议是由ssl+http协议构建的可进行加密传输、身份验证的网络协议要比http协议安全,现在大多数的网站都逐渐用https://,因为安全问题太重要了,有很多的网站都被攻破了,用户数据被泄露。
7. SESSION机制、cookie机制
* cookie通过客户端确定记录信息确定用户身份,session通过服务器端记录信息确定用户身份。
* 虽然Session保存在服务器,对客户端是透明的,它的正常运行仍然需要客户端浏览器的支持。这是因为Session需要使用Cookie作为识别标志。HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一客户,因此服务器向客户端浏览器发送一个名为JSESSIONID的Cookie,它的值为该Session的id(也就是HttpSession.getId()的返回值)。Session依据该Cookie来识别是否为同一用户。
8. 交换机和路由器的区别
* 路由器可以给你的局域网自动分配IP,虚拟拨号,就像一个交通警察,指挥着你的电脑该往哪走,你自己不用操心那么多了。交换机只是用来分配网络数据的。
* 路由器在网络层,路由器根据IP地址寻址,路由器可以处理TCP/IP协议,交换机不可以。交换机在中继层,交换机根据MAC地址寻址
* 路由器可以把一个IP分配给很多个主机使用,这些主机对外只表现出一个IP。交换机可以把很多主机连起来,这些主机对外各有各的IP。
* 路由器提供防火墙的服务,交换机不能提供该功能。集线器、交换机都是做端口扩展的,就是扩大局域网(通常都是以太网)的接入点,也就是能让局域网可以连进来更多的电脑。 路由器是用来做网间连接,也就是用来连接不同的网络9.以下是TCP提供可靠性的方式: (1)应用数据被分割成TCP认为的最合适发送的数据块; (2)当TCP发出一个报文段后,就启动一个定时器,用来等待目的端确认收到这个报文段;若没能及时收到这个确认,TCP发送端将重新发送这个报文段(超时重传); (3)TCP收到一个发自TCP连接的另一端的数据后就将发送一个确认,不过这个确认不是立即就发送,而是要推迟几分之一秒后才发送; (对于收到的请求,给出确认响应) (之所以推迟,可能是要对包做完整校验)(4)TCP将保持它的首部和数据的检验和;(这是一个端到端的检验和,为了检验数据在传输过程中发生的错误;若检测到段的检验和有差错,TCP将丢弃和不确认收到此报文段并希望发端可以进行超时重传) (5)由于TCP报文段是作为IP数据报来传输的,又因为IP数据报的到达可能会失序,所以TCP报文段的到达也可能会失序;因此,有必要的话TCP会对收到的数据进行重新排序后交给应用层; (6)因为TCP报文段是作为IP数据报来传输的,并且IP数据报可能会发生重复,所以TCP的接收端必须丢弃掉重复的数据; (7)TCP提供流量控制;10TCP和UDP区别(从机制上来说)1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
计算机网络
1. TCP报头格式TCP(Transmission Control Protocol)传输控制协议是一种面向连接的、可靠的、基于字节流的传输层协议1、端口号:用来标识同一台计算机的不同的应用进程。1)源端口:源端口和IP地址的作用是标识报文的返回地址。2)目的端口:端口指明接收方计算机上的应用程序接口。TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。2、序号和确认号:是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。例如:一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
3.标志位
ACK 置1时表示确认号(为合法,为0的时候表示数据段不包含确认信息,确认号被忽略。RST 置1时重建连接。如果接收到RST位时候,通常发生了某些错误。SYN 置1时用来发起一个连接。FIN 置1时表示发端完成发送任务。用来释放连接,表明发送方已经没有数据发送了。URG 紧急指针,告诉接收TCP模块紧要指针域指着紧要数据。注:一般不使用。PSH 置1时请求的数据段在接收方得到后就可直接送到应用程序,而不必等到缓冲区满时才传送。注:一般不使用。4.窗口大小(2字节):TCP流量控制通过连接的每一端声明窗口大小进行控制(接收缓冲区大小) 20 00(00100000 00000000)= 8192 由于2字节能够表示的最大正整数为65535,故窗口最大值为65535u16位检验和:检验和覆盖了整个的TCP报文段: TCP首部和TCP数据。这是一个强制性的字段,一定是由发端计算和存储,并由收端进行验证。u16位紧急指针:注:一般不使用。只有当U R G标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。
2. UDP报头格式UDP有两个字段:数据字段和首部字段 用户数据报UDP有两个字段:数据字段和首部字段。首部字段很简单
1. 源端口:源端口号。在需要对方回信时选用,不需要时可用全0.
2. 目的端口:目的端口号。这在终点交付报文时必须要使用到。
3. 长度: UDP用户数据报的长度,其最小值是8(仅有首部)。
UDP用户数据报首部中检验和的计算方法有些特殊。在计算检验时,要在UDP用户数据报之前增加12个字的伪首部。
所谓“伪首部”是因为这种伪首部并不是UDP用户数据报真正的首部。只在计算检验和时,临时添加在UDP用户数据报前面,得到一个临时的UDP用户数据报。2. http协议的报文格式
HTTP协议的请求报文
http请求由三部分组成,分别是:请求行、消息报头、请求正文* 请求方法主要有GET和POST两种
GET:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源。
POST:要求被请求服务器接受附在请求后面的数据,常用于提交表单。当浏览器向服务器发送一个请求到Web服务器,它发送一个数据块,或请求信息,HTTP请求信息包括3部分:请求方法URI协议/版本;请求头(Request Header);请求正文;
HTTP协议的响应报文
和请求报文类似,HTTP响应主要也是3个部分构成:(1)协议状态版本代码描述(2)响应头(Response Header)(3)响应正文 6,http和https区别,https在请求时额外的过程,https是如何保证数据安全的1>. http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
2>. https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
3>. 原因是,https要比http更加安全一些,也就是说http协议是由ssl+http协议构建的可进行加密传输、身份验证的网络协议要比http协议安全,现在大多数的网站都逐渐用https://,因为安全问题太重要了,有很多的网站都被攻破了,用户数据被泄露。
7. SESSION机制、cookie机制
* cookie通过客户端确定记录信息确定用户身份,session通过服务器端记录信息确定用户身份。
* 虽然Session保存在服务器,对客户端是透明的,它的正常运行仍然需要客户端浏览器的支持。这是因为Session需要使用Cookie作为识别标志。HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一客户,因此服务器向客户端浏览器发送一个名为JSESSIONID的Cookie,它的值为该Session的id(也就是HttpSession.getId()的返回值)。Session依据该Cookie来识别是否为同一用户。
8. 交换机和路由器的区别
* 路由器可以给你的局域网自动分配IP,虚拟拨号,就像一个交通警察,指挥着你的电脑该往哪走,你自己不用操心那么多了。交换机只是用来分配网络数据的。
* 路由器在网络层,路由器根据IP地址寻址,路由器可以处理TCP/IP协议,交换机不可以。交换机在中继层,交换机根据MAC地址寻址
* 路由器可以把一个IP分配给很多个主机使用,这些主机对外只表现出一个IP。交换机可以把很多主机连起来,这些主机对外各有各的IP。
* 路由器提供防火墙的服务,交换机不能提供该功能。集线器、交换机都是做端口扩展的,就是扩大局域网(通常都是以太网)的接入点,也就是能让局域网可以连进来更多的电脑。 路由器是用来做网间连接,也就是用来连接不同的网络9.以下是TCP提供可靠性的方式: (1)应用数据被分割成TCP认为的最合适发送的数据块; (2)当TCP发出一个报文段后,就启动一个定时器,用来等待目的端确认收到这个报文段;若没能及时收到这个确认,TCP发送端将重新发送这个报文段(超时重传); (3)TCP收到一个发自TCP连接的另一端的数据后就将发送一个确认,不过这个确认不是立即就发送,而是要推迟几分之一秒后才发送; (对于收到的请求,给出确认响应) (之所以推迟,可能是要对包做完整校验)(4)TCP将保持它的首部和数据的检验和;(这是一个端到端的检验和,为了检验数据在传输过程中发生的错误;若检测到段的检验和有差错,TCP将丢弃和不确认收到此报文段并希望发端可以进行超时重传) (5)由于TCP报文段是作为IP数据报来传输的,又因为IP数据报的到达可能会失序,所以TCP报文段的到达也可能会失序;因此,有必要的话TCP会对收到的数据进行重新排序后交给应用层; (6)因为TCP报文段是作为IP数据报来传输的,并且IP数据报可能会发生重复,所以TCP的接收端必须丢弃掉重复的数据; (7)TCP提供流量控制;10TCP和UDP区别(从机制上来说)1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
11.浅谈一个网页打开的全过程(涉及DNS、CDN、Nginx负载均衡等)
2.1.1 DNS解析
什么是DNS解析?当用户输入一个网址并按下回车键的时候,浏览器得到了一个域名。而在实际通信过程中,我们需要的是一个IP地址。因此我们需要先把域名转换成相应的IP地址,这个过程称作DNS解析。
1) 浏览器首先搜索浏览器自身缓存的DNS记录。
或许很多人不知道,浏览器自身也带有一层DNS缓存。Chrome 缓存1000条DNS解析结果,缓存时间大概在一分钟左右。2) 如果浏览器缓存中没有找到需要的记录或记录已经过期,则搜索hosts文件和操作系统缓存。
在Windows操作系统中,可以通过 ipconfig /displaydns 命令查看本机当前的缓存。 通过hosts文件,你可以手动指定一个域名和其对应的IP解析结果,并且该结果一旦被使用,同样会被缓存到操作系统缓存中。Windows系统的hosts文件在%systemroot%\system32\drivers\etc下,linux系统的hosts文件在/etc/hosts下。3) 如果在hosts文件和操作系统缓存中没有找到需要的记录或记录已经过期,则向域名解析服务器发送解析请求。
其实第一台被访问的域名解析服务器就是我们平时在设置中填写的DNS服务器一项,当操作系统缓存中也没有命中的时候,系统会向DNS服务器正式发出解析请求。这里是真正意义上开始解析一个未知的域名。 一般一台域名解析服务器会被地理位置临近的大量用户使用(特别是ISP的DNS),一般常见的网站域名解析都能在这里命中。4) 如果域名解析服务器也没有该域名的记录,则开始递归+迭代解析。
这里我们举个例子,如果我们要解析的是mail.google.com。首先我们的域名解析服务器会向根域服务器(全球只有13台)发出请求。显然,仅凭13台服务器不可能把全球所有IP都记录下来。所以根域服务器记录的是com域服务器的IP、cn域服务器的IP、org域服务器的IP……。如果我们要查找.com结尾的域名,那么我们可以到com域服务器去进一步解析。所以其实这部分的域名解析过程是一个树形的搜索过程。 根域服务器告诉我们com域服务器的IP。 接着我们的域名解析服务器会向com域服务器发出请求。根域服务器并没有mail.google.com的IP,但是却有google.com域服务器的IP。 接着我们的域名解析服务器会向google.com域服务器发出请求。... 如此重复,直到获得mail.google.com的IP地址。 为什么是递归:问题由一开始的本机要解析mail.google.com变成域名解析服务器要解析mail.google.com,这是递归。 为什么是迭代:问题由向根域服务器发出请求变成向com域服务器发出请求再变成向google.com域发出请求,这是迭代。5) 获取域名对应的IP后,一步步向上返回,直到返回给浏览器。
2.1.2 发起TCP请求
浏览器会选择一个大于1024的本机端口向目标IP地址的80端口发起TCP连接请求。经过标准的TCP握手流程,建立TCP连接。2.1.3 发起HTTP请求
其本质是在建立起的TCP连接中,按照HTTP协议标准发送一个索要网页的请求。2.1.4 负载均衡
什么是负载均衡?当一台服务器无法支持大量的用户访问时,将用户分摊到两个或多个服务器上的方法叫负载均衡。 什么是Nginx?Nginx是一款面向性能设计的HTTP服务器,相较于Apache、lighttpd具有占有内存少,稳定性高等优势。 负载均衡的方法很多,Nginx负载均衡、LVS-NAT、LVS-DR等。这里,我们以简单的Nginx负载均衡为例。关于负载均衡的多种方法详情大家可以Google一下。Nginx有4种类型的模块:core、handlers、filters、load-balancers。 我们这里讨论其中的2种,分别是负责负载均衡的模块load-balancers和负责执行一系列过滤操作的filters模块。1) 一般,如果我们的平台配备了负载均衡的话,前一步DNS解析获得的IP地址应该是我们Nginx负载均衡服务器的IP地址。所以,我们的浏览器将我们的网页请求发送到了Nginx负载均衡服务器上。
2) Nginx根据我们设定的分配算法和规则,选择一台后端的真实Web服务器,与之建立TCP连接、并转发我们浏览器发出去的网页请求。
Nginx默认支持 RR轮转法 和 ip_hash法 这2种分配算法。 前者会从头到尾一个个轮询所有Web服务器,而后者则对源IP使用hash函数确定应该转发到哪个Web服务器上,也能保证同一个IP的请求能发送到同一个Web服务器上实现会话粘连。 也有其他扩展分配算法,如:fair:这种算法会选择相应时间最短的Web服务器url_hash:这种算法会使得相同的url发送到同一个Web服务器3) Web服务器收到请求,产生响应,并将网页发送给Nginx负载均衡服务器。
4) Nginx负载均衡服务器将网页传递给filters链处理,之后发回给我们的浏览器。
而Filter的功能可以理解成先把前一步生成的结果处理一遍,再返回给浏览器。比如可以将前面没有压缩的网页用gzip压缩后再返回给浏览器。2.1.5 浏览器渲染
1) 浏览器根据页面内容,生成DOM Tree。根据CSS内容,生成CSS Rule Tree(规则树)。调用JS执行引擎执行JS代码。
2) 根据DOM Tree和CSS Rule Tree生成Render Tree(呈现树)
3) 根据Render Tree渲染网页
但是在浏览器解析页面内容的时候,会发现页面引用了其他未加载的image、css文件、js文件等静态内容,因此开始了第二部分。2.2 网页静态资源加载
以阿里巴巴的淘宝网首页的logo为例,其url地址为 img.alicdn.com/tps/i2/TB1bNE7LFXXXXaOXFXXwFSA1XXX-292-116.png_145x145.jpg 我们清楚地看到了url中有cdn字样。什么是CDN?如果我在广州访问杭州的淘宝网,跨省的通信必然造成延迟。如果淘宝网能在广东建立一个服务器,静态资源我可以直接从就近的广东服务器获取,必然能提高整个网站的打开速度,这就是CDN。CDN叫内容分发网络,是依靠部署在各地的边缘服务器,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度。接下来的流程就是浏览器根据url加载该url下的图片内容。本质上是浏览器重新开始第一部分的流程,所以这里不再重复阐述。区别只是负责均衡服务器后端的服务器不再是应用服务器,而是提供静态资源的服务器。
相关文章推荐
- 备战校招必备的计算机网络知识(二)
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 校招面试计算机网络基础知识面试常考点
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 计算机基础知识学习(网络必备)强烈推荐!!!
- 牛人整理分享的面试知识:操作系统、计算机网络、设计模式、Linux编程,数据结构总结
- [IT综合面试]牛人整理分享的面试知识:操作系统、计算机网络、设计模式、Linux编程,数据结构总结
- linux系统编程之基础必备(一):计算机体系结构一点基础知识
- 计算机网络基础知识(ISO各层体系结构)
- 计算机网络:传输层(TCP/UDP) 应用层(HTTP) 知识总结
- 计算机网络基础知识
- 计算机网络基础知识