微信房卡牛牛源码和数据库性能分析利器—执行计划
在讲这个问题之前,说一种现象,大家可能会经常遇到这样的情况感觉数据库好慢啊,数据库cpu咋这么高,内存好像不够用了,应该咋办呢,很多同学一脸茫然,也有少部分同学能说建索引,读写分离,分库分表这样大而化之的优化策略,那具体到执行层面如何细化呢?相信绝大多数测试同学已经进入盲区,数据库的优化是从定性到定量的过程,比如是否沿着索引查询,扫描减少了多少行,文件排序减少没,tps提升多少等等,今天就从sql本身给大家剖析数据库执行计划。 数据库执行计划是啥意思?在我看来,就是告诉我这条sql需要做什么,它是怎么做的,通过执行计划我们能分析出sql的性能以及改进思路。我们以主流的mysql为例,给大家举例如何做执行计划;在mysql中,执行计划在sql语句前加上explain即可,如图1,大家已经看到出现了很多行,
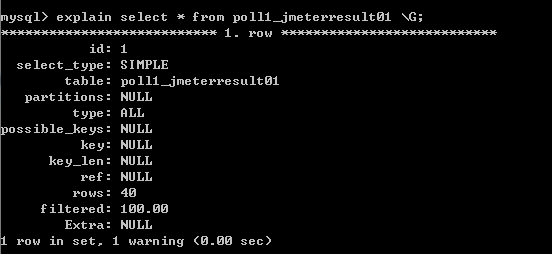 图1我先逐行解释下字面意思 Id代表select语句的编号,相当于标识作用;Select_type查询类型,常见的例如:simple(不含子查询),primary(含子查询或派生查询);Table所查询的表;Partitions一般查看表分区情况;Type查询方式,数据库性能诊断的重要依据,一般有all,index,ref,eq_ref,这一行是重点,大家先记住很重要!Possible_keys和key:possible_keys列指出MySQL能使用哪个索引在该表中找到行。而下面的key是MYSQL实际用到的索引,这意味着在possible_keys中的是计划中的,而key是实际的,也就是计划中有这个索引,实际执行时未必能用到Key_len: 显示MySQL决定使用的键长度。如果KEY键是NULL,则长度为NULL。
图1我先逐行解释下字面意思 Id代表select语句的编号,相当于标识作用;Select_type查询类型,常见的例如:simple(不含子查询),primary(含子查询或派生查询);Table所查询的表;Partitions一般查看表分区情况;Type查询方式,数据库性能诊断的重要依据,一般有all,index,ref,eq_ref,这一行是重点,大家先记住很重要!Possible_keys和key:possible_keys列指出MySQL能使用哪个索引在该表中找到行。而下面的key是MYSQL实际用到的索引,这意味着在possible_keys中的是计划中的,而key是实际的,也就是计划中有这个索引,实际执行时未必能用到Key_len: 显示MySQL决定使用的键长度。如果KEY键是NULL,则长度为NULL。
使用的索引的长度。在不损失精确性的情况下,长度越短越好;row表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。Extra包含不适合在其他列中显示但十分重要的额外信息,请记住,这行也很重要;Using index:该值表示相应的select操作中使用了覆盖索引(Covering Index)MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件 包含所有满足查询需要的数据的索引称为 覆盖索引Using where:表示MySQL服务器在存储引擎受到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询Using filesort: MySQL中无法利用索引完成的排序操作称为“文件排序” 下面我们重点解析type列,会结合官网的案例进行说明,我们按性能从高到低的顺序展示;1、system
这是const的一个特例联接类型。表只有一行(=系统表)。mysql> explain select * from (select * from customer where customer_id=1) a;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | customer | const | PRIMARY | PRIMARY | 2 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
2 rows in set2、const表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const表很快,因为它们只读取一次!
const用于用常数值比较PRIMARY KEY或UNIQUE索引的所有部分时。在下面的查询中,tbl_name可以用于const表:
SELECT * from tbl_name WHERE primary_key=1;
SELECT * from tbl_name WHERE primary_key_part1=1和 primary_key_part2=2;3、eq_ref对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
eq_ref可以用于使用= 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。
在下面的例子中,MySQL可以使用eq_ref联接来处理ref_tables:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
# 相对于下面的ref区别就是它使用的唯一索引,即主键或唯一索引,而ref使用的是非唯一索引或者普通索引。id是主键
mysql> explain select a.*,b.* from testa a,testb b where a.id=b.id
;
+----+-------------+-------+--------+---------------+---------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------+------+-------------+
| 1 | SIMPLE | b | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | sakila.b.id | 1 | NULL |
+----+-------------+-------+--------+---------------+---------+---------+-------------+------+-------------+
2 rows in set4、ref对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
ref可以用于使用=或<=>操作符的带索引的列。
在下面的例子中,MySQL可以使用ref联接来处理ref_tables:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
# 使用非唯一性索引或者唯一索引的前缀扫描,返回匹配某个单独值的记录行。name有非唯一性索引
mysql> explain select * from testa where name='aaa';
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | testa | ref | idx_name | idx_name | 33 | const | 2 | Using index condition |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
1 row in set
mysql> explain select a.*,b.* from testa a,testb b where a.name=b.cname;
+----+-------------+-------+------+---------------+----------+---------+----------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+----------------+------+-------------+
| 1 | SIMPLE | b | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
| 1 | SIMPLE | a | ref | idx_name | idx_name | 33 | sakila.b.cname | 1 | NULL |
+----+-------------+-------+------+---------------+----------+---------+----------------+------+-------------+
2 rows in set5、 fulltext使用FULLTEXT索引进行联接。6、ref_or_null该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
在下面的例子中,MySQL可以使用ref_or_null联接来处理ref_tables:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
mysql> explain select * from (select cusno from testa t1,testb t2 where t1.id=t2.id) t where cusno =2 or cusno is null;
+----+-------------+------------+-------------+---------------+-------------+---------+--------------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------------+---------------+-------------+---------+--------------+------+--------------------------+
| 1 | PRIMARY | <derived2> | ref_or_null | <auto_key0> | <auto_key0> | 5 | const | 2 | Using where; Using index |
| 2 | DERIVED | t2 | index | PRIMARY | PRIMARY | 4 | NULL | 1 | Using index |
| 2 | DERIVED | t1 | eq_ref | PRIMARY | PRIMARY | 4 | sakila.t2.id | 1 | NULL |
+----+-------------+------------+-------------+---------------+-------------+---------+--------------+------+--------------------------+
3 rows in set此处按照官网的格式未测试出例子来,若有例子的请留言,我测试更新7、index_merge该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。此处按照官网的格式未测试出例子来,若有例子的请留言,我测试更新8、unique_subqueryunique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
该类型替换了下面形式的IN子查询的ref:
value IN (SELECT primary_key FROM single_table WHERE some_expr)此处按照官网的格式未测试出例子来,若有例子的请留言,我测试更新9、index_subquery该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:
value IN (SELECT key_column FROM single_table WHERE some_expr)此处按照官网的格式未测试出例子来,若有例子的请留言,我测试更新10、range只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。
当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);11、index索引类型与ALL类型一样,除了它是走索引树扫描的,它有两种方式:如果该覆盖索引能满足查询的所有数据微信房卡牛牛源码搭建(h5.hxforum.com)联系方式 17061863533 企鹅 2952777280 微信Tel17061863533,那仅仅扫描这索引树。在这种情况下,
Extra列就会显示用
Using index。一般仅仅用索引是扫描的比ALL扫描的要快,因为索引树比表数据小很多。全表扫描被用到从索引中去读取数据,
Extra列就不会显示用
Using index。如果查询仅仅是索引列,那MySQL会这个
index索引类型mysql> alter table testa add primary key p_id(id);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> create index idx_name on testa(name);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into testa values(2,2,'aaa');
Query OK, 1 row affected
# 因为查询的列name上建有索引,所以如果这样type走的是index
mysql> explain select name from testa;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | testa | index | NULL | idx_name | 33 | NULL | 2 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
1 row in set
# 因为查询的列cusno没有建索引,或者查询的列包含没有索引的列,这样查询就会走ALL扫描,如下:
mysql> explain select cusno from testa;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | testa | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1 row in set
# *包含有未见索引的列
mysql> explain select * from testa;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | testa | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1 row in set12、all对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。 阅读更多

- 数据库性能分析利器—执行计划
- 数据库性能优化-1-使用SQL Server Profiler工具和执行计划分析
- OCM_第十五天课程:Section6 —》数据库性能调优 _SQL 访问建议 /SQL 性能分析器/配置基线模板/SQL 执行计划管理/实例限制
- MongoDB 性能优化:分析执行计划
- SQL点滴27—性能分析之执行计划
- SQL Sever 2008性能分析之执行计划
- 数据库性能调优技术系列文章(2)--深入理解单表执行计划
- 数据库执行语句性能分析
- SQL点滴27—性能分析之执行计划
- 数据库性能调优技术─嵌套循环执行计划
- SQL性能分析之执行计划
- MongoDB 性能优化:分析执行计划
- Android数据库ORM框架用法、源码和性能比较分析
- SQL性能分析之执行计划
- sql server性能分析--执行计划重用次数
- Pig源码分析: 逻辑执行计划优化
- 数据库性能调优技术—深入理解单表执行计划
- Presto源码分析(和hive执行计划的比较)
- 记录数据库执行情况来分析数据库查询性能问题
- 数据库性能调优技术系列文章(3)--深入理解嵌套循环执行计划