Visualizing and Understanding Convolutional Networks 阅读笔记-网络可视化NO.1
2018-02-18 20:34
621 查看
Visualizing and Understanding Convolutional Networks 阅读笔记
综述:此篇paper是CNN可视化的开山之作(由Lecun得意门生Matthew Zeiler发表于2013年),主要解决了两个问题1)why CNN perform so well?
2)how CNN might be improved?
背景介绍:
1)近些年来,CNN针对图像分类问题有着令人惊叹的效果,2012年的AlexNet(test error:15.3%)碾压第二名(test error:26.2%),由此CNN如雨后春笋般疯狂生长,CNN之所以成功主要归功于三个方面:①数以百万计的带标签数据,②强大的GPU计算能力,③更好的正则化处理
2)提出问题:训练出来的CNN模型为什么能够奏效?怎样奏效?在科研方面,这些问题并没有得到解决。论文介绍了CNN各层到底学到了原始图像的什么特征以及这些特征对最终预测结果的影响力度
实现(paper的展开以2013年的ZFNet=5层conv+3层FC 为基础,在此基础上进行了略微调整(such as:kernel size、stride),并提升了效果)
1)我们都知道ZFNet以conv+ReLU+Maxpooling为主要的实现方式,“看懂并理解”网络就是这个过程的逆过程,即Unpooling+ReLU+反卷积,下面我们分别进行介绍:
2)Unpooling:毫无疑问,maxpooling是一个不可逆过程,例如在一个3*3的pool中,我们选择9个元素的最大值进而实现降采样,我们必然会损失其他8个元素的真实数据。实现过程中,我们需要记录pool中最大值的位置信息,我们称之为“Switches”表格,在unpooling过程中,我们将最大值直接放回该位置,将其他位置直接置0;
3)ReLU:在CNN中,我们使用ReLU作为激活函数是为了修正feature map,使其恒不为负,为了重构每一层的输出,这种约束依然成立,我们继续使用ReLU;
4)反卷积:CNN中,上层的输出与学习到的filters进行卷积,得到本层的特征,逆过程的实现就是通过使用相同卷积核的转置,与矫正之后的特征进行卷积,从而实现反卷积。这时候便产生了疑问?为什么使相同卷积核的转置?下面将进行粗浅说明:
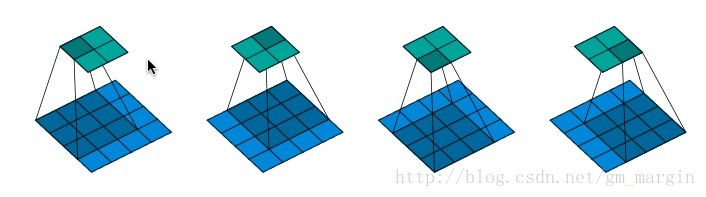
注:假设在某次的卷积过程如图所示,feature map size=4*4,padding=0,strides=1,则会产生2*2的feature map
1.将输入矩阵(蓝色)展开为16维向量,记作x
2.将输出矩阵(绿色)可展开为4维向量,记作y
3.由1,2可知,卷积运算可表示为y = Cx,正向传播时接收16维,输出4维;反向传播时接收4维,输出16维,正向传播与反向传播可类比于卷积与逆卷积运算,其中的C为:

注:其中的wi,jwi,j 代表卷积核的中的元素,推导过程如下:

具体实现过程如图所示:
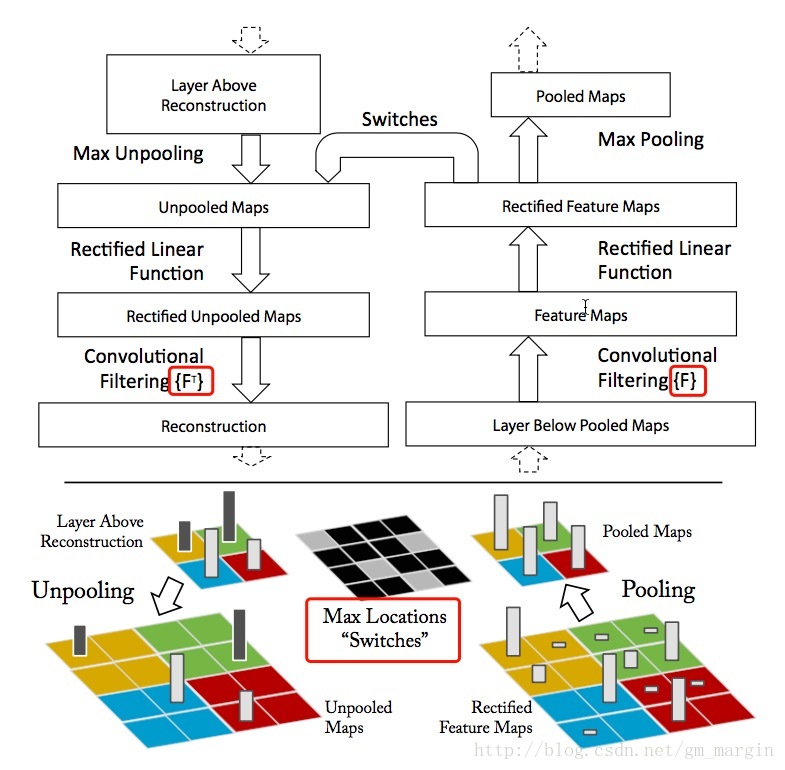
注:Max Locations “Switches”在maxpooling过程中保存了最大值得坐标信息,反卷积的卷积核使用的是相同卷积核的转置
训练细节
1)dataset:模型使用的数据集是ImageNet 2012 training set (130万张照片, 1000个种类),每张照片都从中间截取256*256大小的图片,而后减去所有训练图片像素的均值,每张图片使用10个不同的field,可以通过水平翻转+移动方式获得
2)training:初始学习率0.01,使用SGD学习方式,minibatch为128,momentum动量为0.9,当validation error平稳时对learning rate进行调节,在fc层我们使用dropout(rate为0.5)
网络可视化
1)网络每层的可视化结果展示了网络层次化的特点,较低的网络层级学到的特征较为明显,一般表现为颜色、形状、纹理,随着网络层级的加深,网络学到的特征越抽象。同时,较低的网络层级收敛速度较快,但对输入图像的敏感性很高;较高层级收敛速度较慢,但对输入图像的鲁棒性较高。
2)CNN模型对图像的平移、缩放具有较强的鲁棒性,但图像的旋转操作会对CNN的feature map影响较大。效果如下图所示:
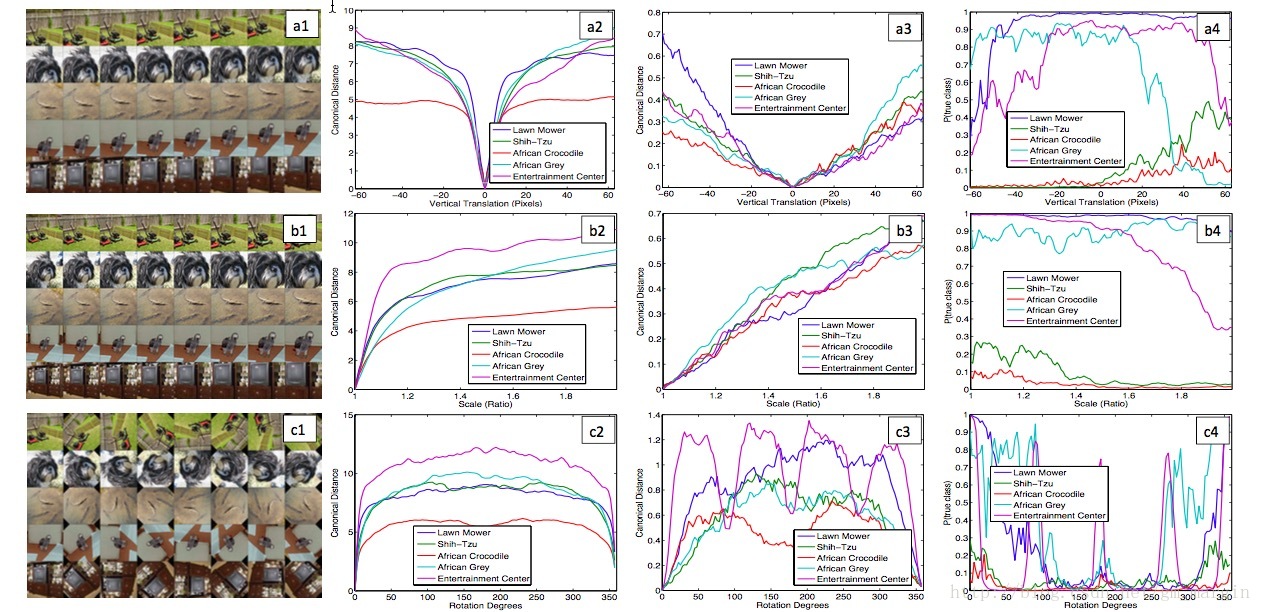
注:a1,b1,c1分别是对原始图像进行垂直移动、放大、旋转等操作;a2,b2,c2和a3,b3,c3分别是对应变化与原始图像在layer1和layer7中feature的欧几里得距离;a4,b4,c4分别是预测正确的概率(其中有两个class预测正确的概率超级低,不知道为什么。。。不过目前的这个结果已经足够有意思了,哈哈哈)
部分图像遮挡对分类结果的影响
实验证明,当对图像的关键位置进行遮挡时,图像预测正确的概率将大大降低
论文中还做了一个实验,很有意思,如下图所示:

注:图片展示了对原始图像进行不同部位的遮挡,第1列为原始图像,第2,3,4分别是对狗的左眼、右眼、鼻子进行遮挡,其他列则是随机进行遮挡,layer5和layer7的
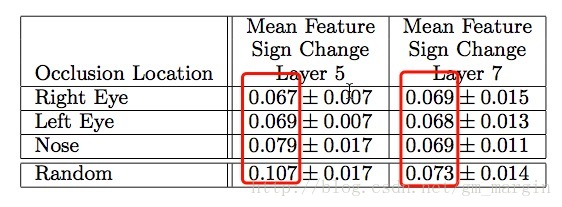
注:layer5关注局部特征,而layer7则关注类别特征(原文:Measure of correspondence for dierent object parts in 5 different dog images. The lower scores for the eyes and nose (compared to random object parts) show the model implicitly establishing some form of correspondence of parts at layer 5 in the model. At layer 7, the scores are more similar, perhaps due to upper layers trying to discriminate between the different breeds of dog.)
之后论文详细阐述了如何重构Alexnet、做出的哪些微调以及最终的效果,此处不再赘述
Summary:论文通过conv+ReLU+maxpooling的逆过程可视化CNN,并通过观察重构结果调整网络结构,提高了模型精确度。是网络可视化的开山经典之作,而后还有几篇可视化的经典之作,如下:
1)《Visualizing and Understanding Convolutional Networks》–就是此篇开创了可视化的先河
2)《Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps》
3)《Learning Deep Features for Discriminative Localization》
4)《Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization》
有时间的话,再和大家一起分享
*作者:gengmiao 时间:2018.02.18,原创文章,转载请保留原文地址、作者等信息*

相关文章推荐
- Visualizing and Understanding Convolutional Networks阅读笔记
- 【论文阅读笔记】Visualizing and Understanding Convolutional Networks
- [深度学习]Visualizing and Understanding Convolutional Networks阅读笔记
- Visualizing and Understanding Convolutional Networks论文笔记
- Visualizing and Understanding Convolutional Networks笔记2
- Visualizing and Understanding Convolutional Networks笔记
- Visualizing and understandingConvolutional Networks笔记3
- [深度学习论文笔记][Visualizing] Visualizing and Understanding Convolutional Networks
- 图像文章阅读2-ZFNet-Visualizing and Understanding Convolutional Networks
- Visualizing and understandingConvolutional Networks笔记4
- Visualizing and Understanding Convolutional Networks笔记1
- 论文笔记 Visualizing and understanding convolutional networks
- Visualizing and Understanding Convolutional Networks笔记
- Visualizing and Understanding Convolutional Networks
- Visualizing and Understanding Convolutional Networks
- Understanding Convolutional Neural Networks for NLP(理解NLP中的卷积神经网络) 阅读笔记
- 【论文阅读笔记】CVPR2015-Long-term Recurrent Convolutional Networks for Visual Recognition and Description
- 关于Visualizing and understanding convolutional networks的一次报告
- Visualizing and Understanding Convolutional Networks
- Visualizing and Understanding Convolutional Networks(精读)