经典文章系列:Feature Pyramid Networks for Object Detection(FPN)论文阅读
2018-02-18 14:14
896 查看
概述
本文是对 Faster R-CNN 在目标检测问题上的进一步完善。Faster R-CNN 有两个步骤, RPN以及 Fast R-CNN,在这两个步骤上FPN都利用更多的卷积特征图(Feature pyramid map)信息来提升RPN和 Fast R-CNN的效果。思想是参考 Fully Convolutional Networks for Semantic Segmentation ,对 coarse outputs 进行放大,分别用对应尺寸的卷积特征图对 outputs 进行微调,得到更好的结果。论文思想
首先论文比较了目前针对多尺度问题的各种解决思路
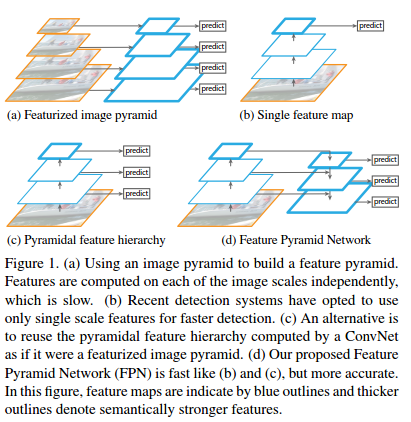
1. 生成图像金字塔,利用图像金字塔生产对应的特征图,在这些特征图上预测,但速度慢
2. 对单尺度图像使用 ConvNets 计算卷积特征,最后在最后一层卷积特征图上进行预测,该特征具有一定的 scale invariance, 但是如果有其他不同尺寸的卷积特征图效果会更好,速度较a快
3. 使用多个卷积特征图进行预测,如SSD(SSD从偏后的conv4_3开始,又往后加了几层,分别抽取每层特征,进行综合利用,但是SSD对于高分辨率的底层特征没有再利用,而这些层对于检测小目标很重要)
4. FPN很好的利用了各个卷积特征图,把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息
第四种思路,通过skip connections利用各个卷积特征图的思想实际已经有人做过了:

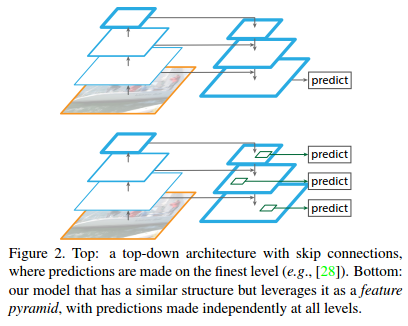
那么FPN和前人有/什么不同?前面的方法预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测,而FPN在各层output上独立检测目标(predictions made independently at all levels)。
形成feature pyramid的具体流程
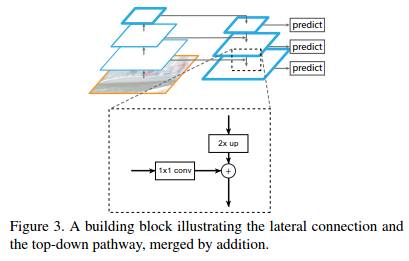
大致思路分为三个部分:一个自底向上的线路(前向传播),一个自顶向下的线路(上采样),横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的作用是减少低层feature map的channel的个数,使得可以element-wise相加。
一些细节:
1. 迭代开始阶段,作者在C5层后面加了一个1 * 1的卷积核来产生最粗略的特征图P5;
2. 自底向上过程中feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,理由是高层特征的特征更强;
3. 上采样采用最近邻插值(简单);
4. 在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect);
5. 金字塔结构中所有层级共享分类层(回归层),就像featurized image pyramid 中所做的那样。作者固定所有特征图中的维度(通道数,表示为d)。作者在本文中设置d = 256,因此所有额外的卷积层(比如P2)具有256通道输出。
FPN在Faster RCNN中的实际运用
FPN网络在Faster RCNN中的应用包括两部分,即分别在RPN和Fast RCNN中的应用。Faster RCNN是基于ResNet 101实现的版本,ResNet 101构成如下: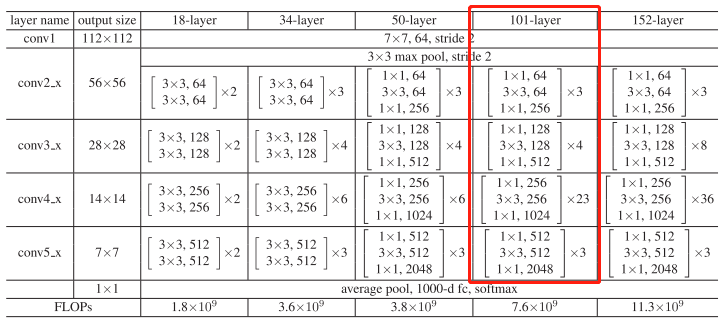
在此基础上实现得到的Faster RCNN框架如下:
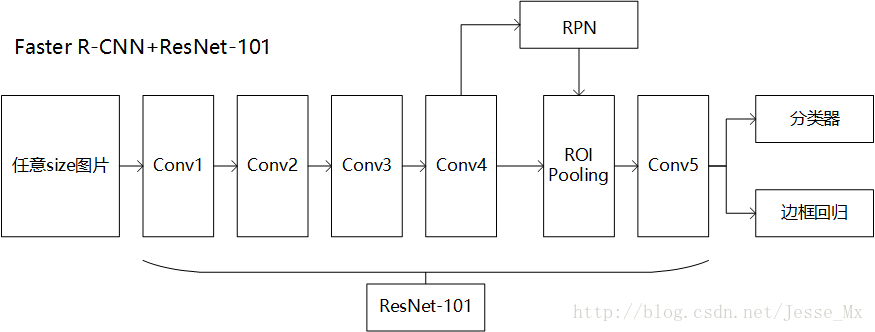
Conv4输出的feature map分别送入RPN和Fast RCNN网络中,最终得到检测的结果。将FPN引入后,最重要的就是构建feature map金字塔,具体实现方法是:
如果把conv2_x最后一层的输出称为C2,同样的有{C2, C3, C4, C5},他们相对于原图的步长分别为{4, 8, 16, 32},对{C2, C3, C4, C5}经过自上而下传播+融合+3*3卷积后得到的最终的输出称为{P2, P3, P4, P5},另外简单对P5下采样(步长为2)得到P6,P2~P6就构成了feature map金字塔。注意:这里conv5也作为了金字塔结构的一部分,作者用两个1024维的轻量级全连接层取代了原来conv5在faster rcnn中起到的全连接层的效果,作者认为这样速度也更快
RPN中的FPN
原始的RPN网络中,通常在conv4输出的单一feature map后接3*3滑动窗,然后分别接入两个1*1的卷积中得到classification和regression的结果,文中将这一部分称为一个head(参考1)。FPN引入RPN中后,将输入的单一feature map替换成多尺度的feature map金字塔(5层,P2~P6),文中采用的办法是在每一层都接一个head,且不同层之间的head共享参数(实验发现不共享head参数比共享head参数效果差,这是因为多层特征之间有相同的语义信息,与使用图像金字塔的网络中最后共享head层的参数是一致的)。实际上,在原始的RPN中classification和regression中是对head输出的每一个点对应的k=9个anchors进行处理,本文另辟蹊径,固定特征金字塔中每层特征图对应的anchor尺寸。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{32^2, 64^2, 128^2, 256^2, 512^2 },当然目标不可能都是正方形,本文仍然使用三种比例{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors(此处参考2中的图示有误,从上到下应该分别为P6~P2)。
Fast RCNN中的FPN
原始的fast rcnn的输入是conv4得到的单一feature map和RPN输出的region proposal,利用ROI pooling层即可得到不同大小的region proposal对应的同样大小的输出。此处因为输入是前面得到的feature map金字塔(注意fast rcnn中不使用P6层),本文采用的方式是,对不同尺度的region proposal,使用不同特征层作为ROI pooling层的输入,大尺度region proposal就用后面一些的金字塔层,比如P5(感受野更大);小尺度region proposal就用前面一点的特征层,比如P2。那怎么判断region proposal该用那个层的输出呢?这里作者定义了一个系数Pk:
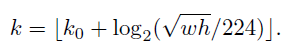
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值做向下取整处理。
实验部分
此处不再赘述
相关文章推荐
- Object Detection -- 论文FPN(Feature Pyramid Networks for Object Detection)解读
- Feature Pyramid Networks for Object Detection (FPN) 阅读笔记
- 目标检测 Feature Pyramid Networks for Object Detection(FPN)论文笔记
- Feature Pyramid Networks for Object Detection 阅读笔记
- FPN(Feature Pyramid Networks for Object Detection)安装与训练
- 论文解读之Feature Pyramid Networks for Object Detection
- 论文笔记:Feature Pyramid Networks for Object Detection
- 多尺度R-CNN论文笔记(6): Feature Pyramid Networks for Object Detection
- Feature Pyramid Networks for Object Detection 论文笔记
- 论文阅读笔记:Object Detection Networks on Convolutional Feature Maps
- 行人检测论文笔记:Fast Feature Pyramids for Object Detection?
- [Paper note] Feature Pyramid Networks for Object Detection
- 论文阅读-《Relation Networks for Object Detection》
- FPN Feature Pyramid Network for Object Detection
- 目标检测--Feature Pyramid Networks for Object Detection
- Feature Pyramid Networks for Object Detection
- 论文阅读笔记:R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation
- 论文阅读--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 目标检测“Feature Pyramid Networks for Object Detection”
- Feature Pyramid Networks for Object Detection