神经网络三:浅析神经网络backpropagation算法中的代价函数
2018-01-27 16:48
267 查看
在博客神经网络一:介绍,示例,代码中,Backpropagation
Algorithm中用到了代价函数:
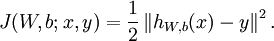
该代价函数是否是最好的?其有没有自身的局限性?还有其他的代价函数吗,有何特点?本文将针对这些问题进行分析。具体的分析是借鉴麦子学院的相关课程中的内容。
假设有一个神经网络模型:

该模型很简单,只有一个输入,一个神经元,一个输出。假设输入值x=1, 真实输出值y=0。初始w=0.6,b=0.9,学习率为0.15,使用的f函数为sigmoid函数:
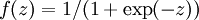
。我们最终的目标是求得预测值a接近0或等于0。将相关参数值带入,求得第一次正向的最后的预测值输出为a=0.82。接下来就要进行反向传播算法,代价函数和循环迭代次数(epoch)的函数关系如下图:

从图可以看到,一开始迭代的时候代价函数就下降很快。当迭代次数为100的时候代价函数基本上就开始收敛,迭代到300的时候最后的输出为0.09,已经很接近目标值0了。此时的权重w=-1.28,偏向值b=-0.98。
上面的过程都建立在初始值得基础上得到的,重新改变初始值:w=2.0,b=2.0,学习率还是0.15,此时第一次正向的输出值为:0.98再z进行Backpropagation
Algorithm的迭代,如下图;

当迭代到300次时,输出为0.20,也可以认为接近0,当该图在迭代次数为160左右的时候才开始下降,开始学习。对比于上面的情况,可以看出模型开始下降很快的迭代次数是不一样的,即学习情况是不一样的。为什么后一种情况“学习慢”这是为什么呢?
原因分析为:
由公式
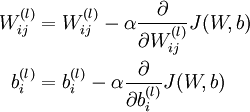
可以看出,学习慢(更新迭代慢)是因为

的值很小造成的,
值小和代价函数有关,分析使用的代价函数:
对于模型只有一个x,一个神经元,一个输出y时,代价函数可以改为:
J = (y-a)*(y-a)/2。其中的a=f(z),z=wx+b。
将J分别关于w和b 求偏导,并将x=1,y=0带入得:


所以
都和f(z)的导数有关,即和f(z)有关,而
,即sigmoid函数,下面分析sigmoid函数,如图为sigmoid函数的图形:

观察图形得到,当f(z)快接近1(或接近0)的时候,其变化很小,变化很小即f(z)导数很小,则
的值就会小,更新就会很慢,即学习就会慢。直接从f(z)的导数
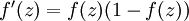
也可以看出。
综上分析可知学习的快慢和代价函数是有关系的,只用代价函数为
未必一定是最好的,那么是否还有其他的代价函数来解决上述学习慢的情况呢?是否能解决学习慢,效率低的区问题呢?下面将进行分析。
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量,设X是一个取有限个值得随机变量,其概率分布为:

则随机变量X的熵定义为:

当X只取两个值:1,0时,

此时变化曲线为:

假设有一个神经网络:

定义cross-entropy函数:

这里对比于熵中X只取1和0的二类概况下:log->ln,y和a与p有关。
为什么可以用该函数做cost函数?原因为:
1)函数值C大于等于0,由上图的H(p)变化曲线可以得知。
2)当a=y时,C->0.
下面关于对w做偏导(对b同理可得):

这里定义函数σ(z) =
,即sigmoid函数,对σ(z)求导,得
将导数带入C对w的偏导中,分母可以消掉,为:

所以最终的学习快慢取决于:σ(z)-y。即当我们的错误率比较大,即σ(z)-y比较大的时候,更新多,学习快;相反,错误小的时候,学习慢,趋于收敛,这正是神经网络中代价函数所需要的。对于偏向值b同理可得。
下面是代价函数为:
时。第二种情况下,代价函数为cross-entropy函数时的变化曲线:

相比于第一种代价函数,cross-entropy函数显示出其优势。
1)cross-entropy函数几乎总是比二次cost函数
好;
2)如果神经元的方程式线性的(在上面分析中,两种都是非线性的情况),用二次函数不会有学习慢的问题,即用二次函数的效果是很好的。
Algorithm中用到了代价函数:
该代价函数是否是最好的?其有没有自身的局限性?还有其他的代价函数吗,有何特点?本文将针对这些问题进行分析。具体的分析是借鉴麦子学院的相关课程中的内容。
1 代价函数(二次cost)
假设有一个神经网络模型:该模型很简单,只有一个输入,一个神经元,一个输出。假设输入值x=1, 真实输出值y=0。初始w=0.6,b=0.9,学习率为0.15,使用的f函数为sigmoid函数:
。我们最终的目标是求得预测值a接近0或等于0。将相关参数值带入,求得第一次正向的最后的预测值输出为a=0.82。接下来就要进行反向传播算法,代价函数和循环迭代次数(epoch)的函数关系如下图:
从图可以看到,一开始迭代的时候代价函数就下降很快。当迭代次数为100的时候代价函数基本上就开始收敛,迭代到300的时候最后的输出为0.09,已经很接近目标值0了。此时的权重w=-1.28,偏向值b=-0.98。
上面的过程都建立在初始值得基础上得到的,重新改变初始值:w=2.0,b=2.0,学习率还是0.15,此时第一次正向的输出值为:0.98再z进行Backpropagation
Algorithm的迭代,如下图;
当迭代到300次时,输出为0.20,也可以认为接近0,当该图在迭代次数为160左右的时候才开始下降,开始学习。对比于上面的情况,可以看出模型开始下降很快的迭代次数是不一样的,即学习情况是不一样的。为什么后一种情况“学习慢”这是为什么呢?
原因分析为:
由公式
可以看出,学习慢(更新迭代慢)是因为
的值很小造成的,
值小和代价函数有关,分析使用的代价函数:
J = (y-a)*(y-a)/2。其中的a=f(z),z=wx+b。
将J分别关于w和b 求偏导,并将x=1,y=0带入得:
所以
都和f(z)的导数有关,即和f(z)有关,而
,即sigmoid函数,下面分析sigmoid函数,如图为sigmoid函数的图形:
观察图形得到,当f(z)快接近1(或接近0)的时候,其变化很小,变化很小即f(z)导数很小,则
的值就会小,更新就会很慢,即学习就会慢。直接从f(z)的导数
也可以看出。
综上分析可知学习的快慢和代价函数是有关系的,只用代价函数为
未必一定是最好的,那么是否还有其他的代价函数来解决上述学习慢的情况呢?是否能解决学习慢,效率低的区问题呢?下面将进行分析。
2 代价函数cross-entropy
(1)熵(entropy)
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量,设X是一个取有限个值得随机变量,其概率分布为:则随机变量X的熵定义为:
当X只取两个值:1,0时,
此时变化曲线为:
(2)cross-entropy
代价函数
假设有一个神经网络:定义cross-entropy函数:
这里对比于熵中X只取1和0的二类概况下:log->ln,y和a与p有关。
为什么可以用该函数做cost函数?原因为:
1)函数值C大于等于0,由上图的H(p)变化曲线可以得知。
2)当a=y时,C->0.
下面关于对w做偏导(对b同理可得):
这里定义函数σ(z) =
,即sigmoid函数,对σ(z)求导,得
将导数带入C对w的偏导中,分母可以消掉,为:
所以最终的学习快慢取决于:σ(z)-y。即当我们的错误率比较大,即σ(z)-y比较大的时候,更新多,学习快;相反,错误小的时候,学习慢,趋于收敛,这正是神经网络中代价函数所需要的。对于偏向值b同理可得。
下面是代价函数为:
时。第二种情况下,代价函数为cross-entropy函数时的变化曲线:
相比于第一种代价函数,cross-entropy函数显示出其优势。
3 总结
1)cross-entropy函数几乎总是比二次cost函数好;
2)如果神经元的方程式线性的(在上面分析中,两种都是非线性的情况),用二次函数不会有学习慢的问题,即用二次函数的效果是很好的。

相关文章推荐
- 神经网络三:浅析神经网络backpropagation算法中的代价函数
- 五、改进神经网络的学习方法(1):交叉熵代价函数
- 关于神经网络中的代价函数——交叉熵的由来
- 神经网络的代价函数到底怎么在算
- 神经网络与深度学习笔记(四)为什么用交叉熵代替二次代价函数
- 神经网络学习之代价函数详解
- Machine Learning第五讲[神经网络: 学习] --(一)代价函数和BP算法
- 机器学习(11.3)--神经网络(nn)算法的深入与优化(3) -- QuadraticCost(二次方代价函数)数理分析
- 神经网络与深度学习 笔记4 交叉熵代价函数 softmax函数
- 神经网络中sigmoid 与代价函数
- 神经网络与深度学习读书笔记第五天----交叉熵代价函数入门
- 课程笔记之六:神经网络的代价函数和误差反向传播算法
- 神经网络中的激活函数
- 【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数
- 神经网络中的能量函数
- 使用神经网络来拟合函数y = x^3 +b
- 神经网络可以拟合任意函数的视觉证明A visual proof that neural nets can compute any function
- Tensorflow中神经网络的激活函数
- 斯坦福cs231n学习笔记(7)------神经网络训练细节(激活函数)
- 利用神经网络方法进行复杂函数的求导