Docker 入门笔记 10 - Control groups
2018-01-24 18:14
525 查看
Linux上的Docker Engine也依赖于另一种称为CGroup的技术。CGroups 最初叫Process Container,顾名思义就是将进程放到一个组里进行统一控制。后来改名叫Control Groups。CGroups 是 Control Groups 的缩写,它为资源管理提供了一个统一框架,可以把系统任务及其子任务整合到按资源等级划分的不同任务组内。并且对这些任务组实施不同的资源分配方案。CGroups可以限制、记录、隔离进程组所使用的物理资源(包括CPU、memory、I/O等)。
cgroups有如下四个有趣的特点:
cgroups的API以一个伪文件系统的方式实现,即用户可以通过文件操作实现cgroups的组织管理。
cgroups的组织管理操作单元可以细粒度到线程级别,用户态代码也可以针对系统分配的资源创建和销毁cgroups,从而实现资源再分配和管理。
所有资源管理的功能都以“subsystem(子系统)”的方式实现,接口统一。
子进程创建之初与其父进程处于同一个cgroups的控制组。
控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;
子系统(subsystem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED)
用来限制cgroup的CPU使用率。
cpuacct (since Linux 2.6.24; CONFIG_CGROUP_CPUACCT)
统计cgroup的CPU的使用率。
cpuset (since Linux 2.6.24; CONFIG_CPUSETS)
绑定cgroup到指定CPUs和NUMA节点。
memory (since Linux 2.6.25; CONFIG_MEMCG)
统计和限制cgroup的内存的使用率,包括process memory, kernel memory, 和swap。
devices (since Linux 2.6.26; CONFIG_CGROUP_DEVICE)
限制cgroup创建(mknod)和访问设备的权限。
freezer (since Linux 2.6.28; CONFIG_CGROUP_FREEZER)
suspend和restore一个cgroup中的所有进程。
net_cls (since Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID)
将一个cgroup中进程创建的所有网络包加上一个classid标记,用于tc和iptables。 只对发出去的网络包生效,对收到的网络包不起作用。
blkio (since Linux 2.6.33; CONFIG_BLK_CGROUP)
限制cgroup访问块设备的IO速度。
perf_event (since Linux 2.6.39; CONFIG_CGROUP_PERF)
对cgroup进行性能监控
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
针对每个网络接口设置cgroup的访问优先级。
hugetlb (since Linux 3.5; CONFIG_CGROUP_HUGETLB)
限制cgroup的huge pages的使用量。
pids (since Linux 4.3; CONFIG_CGROUP_PIDS)
限制一个cgroup及其子孙cgroup中的总进程数。
Cgroup 与进程在以下方面类似:
- 它们是分级的,且
- 子 cgroup 会继承父 cgroup 的某些属性。
根本的不同是在某个系统中可同时存在不同的分级 cgroup。如果 Linux 进程模式是进程的单一树模式,那么 cgroup 模式是一个或者更多任务的独立、未连接树(例如:进程)。
需要多个独立 cgroup 分级,因为每个分级都会附加到一个或者多个子系统中。子系统代表单一资源,比如 CPU 时间或者内存。
默认情况都是挂载到/sys/fs/cgroup目录下,当然挂载到其它任何目录都没关系。
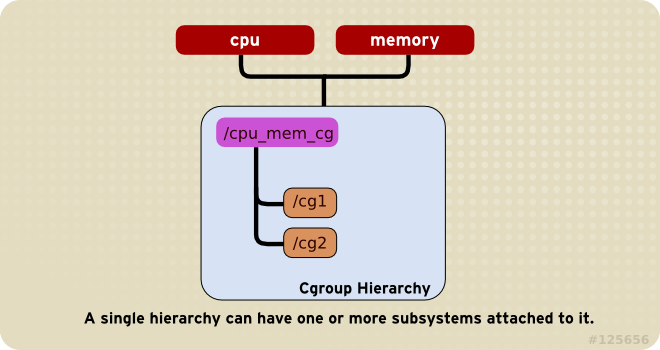
例如在ubuntu中,systemd就是将和cpu,cpuacct两个subsystem挂载到了/sys/fs/cgroup/cpu,cpuacct 这个hierarchy
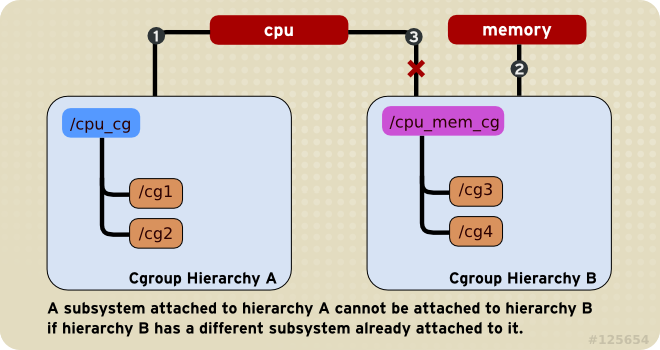
本质上将,一个subsystem只能关联到一颗cgroup hierarchy ,一旦关联并在这个hierarchy上创建了子cgroup,subsystems和这棵cgroup hierarchy就成了一个整体,不能再重新组合。

每次在系统中创建新hierarchy时,该系统中的所有task都是那个hierarchy的默认 cgroup(我们称之为 root cgroup)的初始成员。
这样,单一task可以是在多个 cgroup 中。前提是这些cgroup不能同时位于同一个hierarchy。
首先我们尝试创建一个root cgroup, 在系统中可以创建任意多个不和任何subsystem关联的cgroup树,name是这棵树的唯一标记,当name指定的是一个新的名字时,将创建一颗新的cgroup树,但如果内核中已经存在一颗一样name的cgroup树,那么将mount已存在的这颗cgroup树
再试一个例子:
每一行包含用冒号隔开的三列,他们的意思分别是
cgroup树的ID, 和/proc/cgroups文件中的ID一一对应。
和cgroup树绑定的所有subsystem,多个subsystem之间用逗号隔开。这里name=systemd表示没有和任何subsystem绑定,只是给他起了个名字叫systemd。
进程在cgroup树中的路径,即进程所属的cgroup,这个路径是相对于挂载点的相对路径。
接着之前的例子:
yum install libcgroup
ubuntu系统:
sudo apt-get install cgroup-bin cgroup-lite cgroup-tools cgroupfs-mount libcgroup1
service cgconfig start|stop
ubuntu系统(Systemd):
systemctl start cgmanager.service
systemctl start run-cgmanager-fs.mount
systemctl start cgroupfs-mount.service
/sys/fs/cgroup; 该文件夹包含一堆cgroup类型挂在的虚拟文件用来代表特定的cgroup层级.
/etc/init/cgroup-lite.conf. cgroup-lite.conf creates the /sys/fs/cgroup directory, based on the contents of
/proc/cgroups, 这个文件指定了cgroup-lite 应该创建哪些Control group.
安装cgroup-bin后,unbuntu的systemd已经帮我们将各个subsystem和cgroup树关联并挂载好了
/usr/bin/cgcreate – cgcreate在层级中创建新cgroup。
/usr/bin/cgdelete – cgdelete命令删除指定的cgroup。
/usr/bin/cgexec – cgexec命令在指定的cgroup中运行任务。
/usr/bin/cgget – cgget命令显示cgroup参数。
/usr/bin/cgset – cgset 命令为 cgroup 设定参数。
/usr/bin/lscgroup – lscgroup 命令列出层级中的 cgroup。
/usr/bin/lssubsys – lssubsys 命令列出包含指定子系统的层级
/usr/sbin/cgclear – cgclear 命令是用来删除层级中的所有cgroup。
/usr/sbin/cgconfigparser – cgconfigparser命令解析cgconfig.conf文件和并挂载层级。
/usr/sbin/cgrulesengd – cgrulesengd 在 cgroup 中发布任务。
相关配置文件:
- cgred.conf – cgred.conf是cgred服务的配置文件。
- cgrules.conf – cgrules.conf 包含用来决定何时任务术语某些 cgroup的规则。
- cgconfig.conf – 在cgconfig.conf文件中定义cgroup。
cgconfig.conf
cgconfig.conf是libcgroup用于定义控制组及其参数和挂载点的配置文件。 该文件由mount,group和default部分组成。 这些部分可以是任意的顺序,所有这些部分都是可选的。 (refer to “man cgconfig.conf”)
mount section
group section
default section
例如:
cgroup manager
cgroup manager(cgmanager)提供了一个D-Bus服务,允许程序和用户管理cgroup,而不需要直接了解或访问cgroup文件系统。 对于来自与管理者相同名称空间任务的请求,管理者可以直接执行所需的安全检查,以确保请求是合法的。 对于其他请求(例如来自容器中任务的请求),必须进行增强的D-Bus请求,其中将进程,用户和组ID作为SCM_CREDENTIALS传递,以便内核将标识符映射到其全局主机值。
为了便利所有用户使用简单的D-Bus呼叫,一个“cgroup管理器代理”(cgproxy)在容器中自动启动。 代理服务器接受来自相同命名空间中任务的标准D-Bus请求,并将它们转换为SCM传递给cgmanager的D-Bus请求。
创建一个运行cpu密集编译的新cgroup的简单例子如下所示:
cgm
cgm是一个简化cgroup manager请求的客户端脚本。 它只是调用dbus-send向运行中的cgmanager或cgproxy发送请求。
下面的例子中,首先创建一个名为foo的cgroup然后将当前shell移入其中:
cgproxy
cgproxy是cgmanager的D-Bus代理。 由于非初始pid或user namespace中的进程将引用任务,用户ID或组ID 在初始名称空间中是错乱的。cgproxy将依据内核将它们作为SCM凭证发送给cgmanager 翻译标识符。 通过这种方式,容器中的程序和用户可以使用相同的简单D-Bus调用通过代理服务器进行cgroup管理请求,就像它们在基本主机上直接与cgmanager交互一样。
example
创建一个耗CPU的脚本:
运行一下:
创建一个cpu受限的cgroup
cpu.cfs_period_us 表示将每个cpu时间片分成100000份。
cpu.cfs_period_us 表示当前这个组中的task(tasks中的taskid)将分配多少比例的cpu时间片。如果是双核cpu,这里就表示最多可以用到200%的CPU。
为我们的cgroup分配 50% cpu的配额
参考:
- Resource Management Guide
- Ubuntu 服务器指南(Control Group)
- linux kernel CGroup
- CGroup 介绍、应用实例及原理描述
- Introduction to Linux Control Groups (Cgroups)
- Docker 和 cgroup
cgroups有如下四个有趣的特点:
cgroups的API以一个伪文件系统的方式实现,即用户可以通过文件操作实现cgroups的组织管理。
cgroups的组织管理操作单元可以细粒度到线程级别,用户态代码也可以针对系统分配的资源创建和销毁cgroups,从而实现资源再分配和管理。
所有资源管理的功能都以“subsystem(子系统)”的方式实现,接口统一。
子进程创建之初与其父进程处于同一个cgroups的控制组。
相关概念
任务(task)。在 cgroups 中,任务就是系统的一个进程;控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;
层级(hierarchy)。控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;
子系统(subsystem)。一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
子系统
cgroups提供了subsystem(resource controllers)作为资源的控制器cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED)
用来限制cgroup的CPU使用率。
cpuacct (since Linux 2.6.24; CONFIG_CGROUP_CPUACCT)
统计cgroup的CPU的使用率。
cpuset (since Linux 2.6.24; CONFIG_CPUSETS)
绑定cgroup到指定CPUs和NUMA节点。
memory (since Linux 2.6.25; CONFIG_MEMCG)
统计和限制cgroup的内存的使用率,包括process memory, kernel memory, 和swap。
devices (since Linux 2.6.26; CONFIG_CGROUP_DEVICE)
限制cgroup创建(mknod)和访问设备的权限。
freezer (since Linux 2.6.28; CONFIG_CGROUP_FREEZER)
suspend和restore一个cgroup中的所有进程。
net_cls (since Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID)
将一个cgroup中进程创建的所有网络包加上一个classid标记,用于tc和iptables。 只对发出去的网络包生效,对收到的网络包不起作用。
blkio (since Linux 2.6.33; CONFIG_BLK_CGROUP)
限制cgroup访问块设备的IO速度。
perf_event (since Linux 2.6.39; CONFIG_CGROUP_PERF)
对cgroup进行性能监控
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
针对每个网络接口设置cgroup的访问优先级。
hugetlb (since Linux 3.5; CONFIG_CGROUP_HUGETLB)
限制cgroup的huge pages的使用量。
pids (since Linux 4.3; CONFIG_CGROUP_PIDS)
限制一个cgroup及其子孙cgroup中的总进程数。
概念相互关系及基本规则
传统的Unix进程管理,实际上是先启动init进程作为根节点,再由init节点创建子进程作为子节点,而每个子节点由可以创建新的子节点,如此往复,形成一个树状结构。Cgroup 与进程在以下方面类似:
- 它们是分级的,且
- 子 cgroup 会继承父 cgroup 的某些属性。
根本的不同是在某个系统中可同时存在不同的分级 cgroup。如果 Linux 进程模式是进程的单一树模式,那么 cgroup 模式是一个或者更多任务的独立、未连接树(例如:进程)。
需要多个独立 cgroup 分级,因为每个分级都会附加到一个或者多个子系统中。子系统代表单一资源,比如 CPU 时间或者内存。
基于虚拟文件系统的CGroup管理
Linux 使用了多种数据结构在内核中实现了 cgroups 的配置,关联了进程和 cgroups 节点,那么 Linux 又是如何让用户态的进程使用到 cgroups 的功能呢? Linux内核有一个很强大的模块叫 VFS (Virtual File System)。 VFS 能够把具体文件系统的细节隐藏起来,给用户态进程提供一个统一的文件系统 API 接口。 cgroups 也是通过 VFS 把功能暴露给用户态的,cgroups 与 VFS 之间的衔接部分称之为 cgroups 虚拟文件系统。使用cgroup很简单,挂载这个文件系统就可以了。这时通过挂载选项指定使用哪个子系统。默认情况都是挂载到/sys/fs/cgroup目录下,当然挂载到其它任何目录都没关系。
//挂载一颗和所有subsystem关联的cgroup树到/sys/fs/cgroup mount -t cgroup <cgroup name> /sys/fs/cgroup //挂载一颗和cpuset subsystem关联的cgroup树到/sys/fs/cgroup/cpuset mkdir /sys/fs/cgroup/cpuset mount -t cgroup -o cpuset <cgroup name> /sys/fs/cgroup/cpuset //挂载一颗与cpu和cpuacct subsystem关联的cgroup树到/sys/fs/cgroup/cpu,cpuacct mkdir /sys/fs/cgroup/cpu,cpuacct mount -t cgroup -o cpu,cpuacct <cgroup name> /sys/fs/cgroup/cpu,cpuacct //挂载一棵cgroup树,但不关联任何subsystem,下面就是systemd所用到的方式 mkdir /sys/fs/cgroup/systemd mount -t cgroup -o none,name=systemd <cgroup name> /sys/fs/cgroup/systemd
规则 1: 多个subsystem可附着到同一个hierarchy
例如在ubuntu中,systemd就是将和cpu,cpuacct两个subsystem挂载到了/sys/fs/cgroup/cpu,cpuacct 这个hierarchy
# mount |grep cpu,cpuacct cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
规则2: 一个subsystem不能同时附加到多个hierarchy,除非那个hierarchy不包含其他subsystem。
4000
//尝试将cpu subsystem重新关联cpu_cg hierarchy 并且将这棵树mount到./cpu目录
# mkdir -p /mnt/cgroup/cpu_cg
# mount -t cgroup -o cpu cpu_cg /mnt/cgroup/cpu_cg
mount: cpu_cg is already mounted or /mnt/cgroup/cpu_cg busy
//但是将memory subsystem 关联到另一个Cgroup hierarchy是可以的
# mkdir -p /mnt/cgroup/mem_cg
# mount -t cgroup -o memory mem_cg /mnt/cgroup/mem_cg
# mount|grep memory
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
mem_cg on /mnt/cgroup/mem_cg type cgroup (rw,relatime,memory)
//实际上,用同样的参数挂载时,会重用现有的cgroup hierarchy,也即两个挂载点看到的内容是一样的
# mkdir -p /mnt/cgroup/cpu,cpuacct && cd /mnt/cgroup
# mount -t cgroup -o cpu,cpuacct new-cpu-cpuacct ./cpu,cpuacct
# mount |grep cpu,cpuacct cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)new-cpu-cpuacct on /mnt/cgroup/cpu,cpuacct type cgroup (rw,relatime,cpu,cpuacct)
# mkdir -p /sys/fs/cgroup/cpu,cpuacct/test; ls -l /mnt/cgroup/cpu,cpuacct|grep test
drwxr-xr-x 2 root root 0 1月 23 18:18 test
//clean
# umount new-cpu-cpuacct
# umount mem_cg
# cgdelete cpu,cpuacct:test
本质上将,一个subsystem只能关联到一颗cgroup hierarchy ,一旦关联并在这个hierarchy上创建了子cgroup,subsystems和这棵cgroup hierarchy就成了一个整体,不能再重新组合。
规则3:同一个task不能同时作为同一个hierarchy的不同cgroup的成员
每次在系统中创建新hierarchy时,该系统中的所有task都是那个hierarchy的默认 cgroup(我们称之为 root cgroup)的初始成员。
这样,单一task可以是在多个 cgroup 中。前提是这些cgroup不能同时位于同一个hierarchy。
首先我们尝试创建一个root cgroup, 在系统中可以创建任意多个不和任何subsystem关联的cgroup树,name是这棵树的唯一标记,当name指定的是一个新的名字时,将创建一颗新的cgroup树,但如果内核中已经存在一颗一样name的cgroup树,那么将mount已存在的这颗cgroup树
// 由于name=test的cgroup树在系统中不存在,所以这里会创建一颗新的name=test的cgroup树 # mkdir -p /mnt/cgroup/test && cd /mnt/cgroup # mount -t cgroup -o none,name=test test ./test // 系统为新创建的cgroup树的root cgroup生成了默认文件 # ls /mnt/cgroup/test cgroup.clone_children cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks // 新创建的cgroup树的root cgroup里包含系统中的所有进程 # wc -l ./test/cgroup.procs 188 ./test/cgroup.procs // 创建子cgroup # cd test && mkdir subcg // 系统已经为新的子cgroup生成了默认文件 # ls subcg cgroup.clone_children cgroup.procs notify_on_release tasks //新创建的子cgroup中没有任何进程 # wc -l subcg/cgroup.procs 0 subcg/cgroup.procs //重新挂载这棵树到test1,由于mount的时候指定的name=test,所以和上面挂载的是同一颗cgroup树,于是test1目录下的内容和test目录下的内容一样 # mkdir -p /mnt/cgroup/test1 && cd /mnt/cgroup # mount -t cgroup -o none,name=test test ./test1 # ls ./test1 cgroup.clone_children cgroup.procs cgroup.sane_behavior notify_on_release release_agent subcg tasks #清理 # umount /mnt/cgroup/test1 # umount /mnt/cgroup/test # rm -rf /mnt/cgroup/test /mnt/cgroup/test1
再试一个例子:
// 换一个console 启动一个bash $ ps -ef|grep $$ chic 1944 1939 0 09:56 pts/1 00:00:00 -bash //查看这个bash所属的cgroup $ cat /proc/1944/cgroup 11:blkio:/user.slice 10:freezer:/ 9:memory:/user.slice 8:cpuset:/ 7:devices:/user.slice 6:net_cls,net_prio:/ 5:hugetlb:/ 4:pids:/user.slice/user-1000.slice 3:perf_event:/ 2:cpu,cpuacct:/user.slice 1:name=systemd:/user.slice/user-1000.slice/session-2.scope
每一行包含用冒号隔开的三列,他们的意思分别是
cgroup树的ID, 和/proc/cgroups文件中的ID一一对应。
和cgroup树绑定的所有subsystem,多个subsystem之间用逗号隔开。这里name=systemd表示没有和任何subsystem绑定,只是给他起了个名字叫systemd。
进程在cgroup树中的路径,即进程所属的cgroup,这个路径是相对于挂载点的相对路径。
# mount -t cgroup -o none,name=cgroup cgroup /mnt/cgroup # mkdir -p /mnt/cgroup/child1 # mkdir -p /mnt/cgroup/child2 //检查之前的bash现在也属于这个cgroup /mnt/cgroup# cat cgroup.procs |grep 1944 1944 //将bash移入 child1 cgroup # cd child1 # echo 1944 > cgroup.procs # cat /proc/1944/cgroup 13:name=cgroup:/child1 11:blkio:/user.slice 10:freezer:/ 9:memory:/user.slice 8:cpuset:/ 7:devices:/user.slice 6:net_cls,net_prio:/ 5:hugetlb:/ 4:pids:/user.slice/user-1000.slice 3:perf_event:/ 2:cpu,cpuacct:/user.slice 1:name=systemd:/user.slice/user-1000.slice/session-2.scope //再试着将bash放入 child2 cgroup # echo 1944 > /mnt/cgroup/child2/cgroup.procs # cat /proc/1944/cgroup 13:name=cgroup:/child2 11:blkio:/user.slice 10:freezer:/ 9:memory:/user.slice 8:cpuset:/ 7:devices:/user.slice 6:net_cls,net_prio:/ 5:hugetlb:/ 4:pids:/user.slice/user-1000.slice 3:perf_event:/ 2:cpu,cpuacct:/user.slice 1:name=systemd:/user.slice/user-1000.slice/session-2.scope //可以看见bash现在属于child2 而从child1 移除了,一个task不会同时属于同一hierarchy的不同cgroup
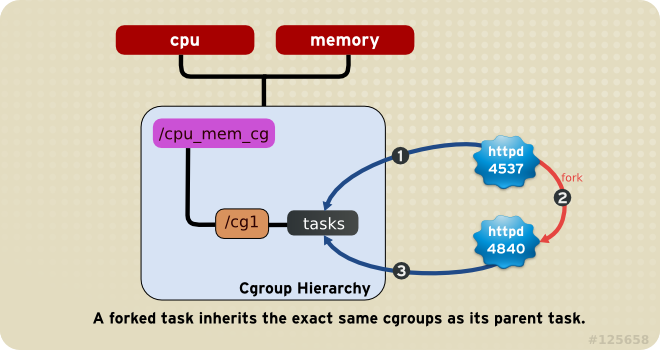
规则4:子进程(task)总是自动成为父进程所在的cgroup的成员,然后可以移动到不同的cgroup中去。
接着之前的例子:
//在新的bash(1944)中在启动一个bash(12110) $ pstree -p 1944 bash(1944)───bash(12110)───pstree(12142) $ cat /proc/12110/cgroup 13:name=cgroup:/child2 11:blkio:/user.slice 10:freezer:/ 9:memory:/user.slice 8:cpuset:/ 7:devices:/user.slice 6:net_cls,net_prio:/ 5:hugetlb:/ 4:pids:/user.slice/user-1000.slice 3:perf_event:/ 2:cpu,cpuacct:/user.slice 1:name=systemd:/user.slice/user-1000.slice/session-2.scope
使用libcgroup工具包
libcgroup工具安装
redhat系统:yum install libcgroup
ubuntu系统:
sudo apt-get install cgroup-bin cgroup-lite cgroup-tools cgroupfs-mount libcgroup1
cgroup服务的启动和停止:
redhat系统(Sys V init):service cgconfig start|stop
ubuntu系统(Systemd):
systemctl start cgmanager.service
systemctl start run-cgmanager-fs.mount
systemctl start cgroupfs-mount.service
CGroups功能测试(基于Ubuntu)
在Ubuntu上安装完成cgroup工具包后,系统会创建以下文件:/sys/fs/cgroup; 该文件夹包含一堆cgroup类型挂在的虚拟文件用来代表特定的cgroup层级.
/etc/init/cgroup-lite.conf. cgroup-lite.conf creates the /sys/fs/cgroup directory, based on the contents of
/proc/cgroups, 这个文件指定了cgroup-lite 应该创建哪些Control group.
安装cgroup-bin后,unbuntu的systemd已经帮我们将各个subsystem和cgroup树关联并挂载好了
# mount |grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (rw,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids,release_agent=/run/cgmanager/agents/cgm-release-agent.pids) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec, 10814 relatime,blkio) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event,release_agent=/run/cgmanager/agents/cgm-release-agent.perf_event) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb,release_agent=/run/cgmanager/agents/cgm-release-agent.hugetlb) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset,clone_children) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) # ls /sys/fs/cgroup/ blkio cgmanager cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd
cgroup-bin 包含的基本命令
/usr/bin/cgclassify – cgclassify命令是用来将运行的任务移动到一个或者多个cgroup。/usr/bin/cgcreate – cgcreate在层级中创建新cgroup。
/usr/bin/cgdelete – cgdelete命令删除指定的cgroup。
/usr/bin/cgexec – cgexec命令在指定的cgroup中运行任务。
/usr/bin/cgget – cgget命令显示cgroup参数。
/usr/bin/cgset – cgset 命令为 cgroup 设定参数。
/usr/bin/lscgroup – lscgroup 命令列出层级中的 cgroup。
/usr/bin/lssubsys – lssubsys 命令列出包含指定子系统的层级
/usr/sbin/cgclear – cgclear 命令是用来删除层级中的所有cgroup。
/usr/sbin/cgconfigparser – cgconfigparser命令解析cgconfig.conf文件和并挂载层级。
/usr/sbin/cgrulesengd – cgrulesengd 在 cgroup 中发布任务。
相关配置文件:
- cgred.conf – cgred.conf是cgred服务的配置文件。
- cgrules.conf – cgrules.conf 包含用来决定何时任务术语某些 cgroup的规则。
- cgconfig.conf – 在cgconfig.conf文件中定义cgroup。
cgconfig.conf
cgconfig.conf是libcgroup用于定义控制组及其参数和挂载点的配置文件。 该文件由mount,group和default部分组成。 这些部分可以是任意的顺序,所有这些部分都是可选的。 (refer to “man cgconfig.conf”)
mount section
mount {
<controller> = <path>;
...
}
//controller : kernel subsystem 名称
//path : 与给controller关联的hierarichy的目录路径。group section
group <name> {
[permissions]
<controller> {
<param name> = <param value>;
...
}
...
}
//name: Name of the control group
//permissions: 可选项,指定cgroup对应的挂载点文件系统的权限,root用户拥有所有权限
//param name 和 param value:子系统的属性及其属性值default section
default {
perm {
task {
uid = <task user>;
gid = <task group>;
fperm = <file permissions>
}
admin {
uid = <admin name>;
gid = <admin group>;
dperm = <directory permissions>
fperm = <file permissions>
}
}
}例如:
mount {
cpu = /sys/fs/cgroup/cpu;
cpuacct = /sys/fs/cgroup/cpu;
}
group daemons/www {
perm {
task {
uid = root;
gid = webmaster;
fperm = 770;
}
admin {
uid = root;
gid = root;
dperm = 775;
fperm = 744;
}
}
cpu {
cpu.shares = "1000";
}
}
group daemons/ftp {
perm {
task {
uid = root;
gid = ftpmaster;
fperm = 774;
}
admin {
uid = root;
gid = root;
dperm = 755;
fperm = 700;
}
}
cpu {
cpu.shares = "500";
}
}
相当于:
mkdir /sys/fs/cgroup/cpu
mount -t cgroup -o cpu,cpuacct cpu /sys/fs/cgroup/cpu
mkdir /sys/fs/cgroup/cpu/daemons
mkdir /sys/fs/cgroup/cpu/daemons/www
chown root:root /sys/fs/cgroup/cpu/daemons/www/*
chown root:webmaster /sys/fs/cgroup/cpu/daemons/www/tasks
echo 1000 > /sys/fs/cgroup/cpu/daemons/www/cpu.shares
mkdir /sys/fs/cgroup/cpu/daemons/ftp
chown root:root /sys/fs/cgroup/cpu/daemons/ftp/*
chown root:ftpmaster /sys/fs/cgroup/cpu/daemons/ftp/tasks
echo 500 > /sys/fs/cgroup/cpu/daemons/ftp/cpu.sharescgroup manager
cgroup manager(cgmanager)提供了一个D-Bus服务,允许程序和用户管理cgroup,而不需要直接了解或访问cgroup文件系统。 对于来自与管理者相同名称空间任务的请求,管理者可以直接执行所需的安全检查,以确保请求是合法的。 对于其他请求(例如来自容器中任务的请求),必须进行增强的D-Bus请求,其中将进程,用户和组ID作为SCM_CREDENTIALS传递,以便内核将标识符映射到其全局主机值。
为了便利所有用户使用简单的D-Bus呼叫,一个“cgroup管理器代理”(cgproxy)在容器中自动启动。 代理服务器接受来自相同命名空间中任务的标准D-Bus请求,并将它们转换为SCM传递给cgmanager的D-Bus请求。
创建一个运行cpu密集编译的新cgroup的简单例子如下所示:
cgm create cpuset build1 cgm movepid cpuset build1 $$ cgm setvalue cpuset build1 cpuset.cpus 1 make
cgm
cgm是一个简化cgroup manager请求的客户端脚本。 它只是调用dbus-send向运行中的cgmanager或cgproxy发送请求。
下面的例子中,首先创建一个名为foo的cgroup然后将当前shell移入其中:
sudo cgm create all foo sudo cgm chown all foo $(id -u) $(id -g) cgm movepid all foo $$ //then to freeze the cgroup cgm setvalue freezer foo freezer.state FROZEN
cgproxy
cgproxy是cgmanager的D-Bus代理。 由于非初始pid或user namespace中的进程将引用任务,用户ID或组ID 在初始名称空间中是错乱的。cgproxy将依据内核将它们作为SCM凭证发送给cgmanager 翻译标识符。 通过这种方式,容器中的程序和用户可以使用相同的简单D-Bus调用通过代理服务器进行cgroup管理请求,就像它们在基本主机上直接与cgmanager交互一样。
example
创建一个耗CPU的脚本:
$ cat cpu.sh #!/bin/bash tmp=1 while [ True ];do tmp=$tmp done;
运行一下:
#top -p `pidof -x cpu.sh` PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 26855 chic 20 0 14264 912 808 R 100.0 0.0 0:08.70 cpu.sh
创建一个cpu受限的cgroup
# cgcreate -a root -t chic -g cpu:mycpulimitgrp # ls -l /sys/fs/cgroup/cpu/mycpulimitgrp/ total 0 -rw-r--r-- 1 root root 0 1月 24 17:32 cgroup.clone_children -rw-r--r-- 1 root root 0 1月 24 17:32 cgroup.procs -r--r--r-- 1 root root 0 1月 24 17:32 cpuacct.stat -rw-r--r-- 1 root root 0 1月 24 17:32 cpuacct.usage -r--r--r-- 1 root root 0 1月 24 17:32 cpuacct.usage_percpu -rw-r--r-- 1 root root 0 1月 24 17:32 cpu.cfs_period_us -rw-r--r-- 1 root root 0 1月 24 17:32 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 1月 24 17:32 cpu.shares -r--r--r-- 1 root root 0 1月 24 17:32 cpu.stat -rw-r--r-- 1 root root 0 1月 24 17:32 notify_on_release -rw-r--r-- 1 chic root 0 1月 24 17:32 tasks # cat /sys/fs/cgroup/cpu/mycpulimitgrp/cpu.cfs_period_us 100000 # cat /sys/fs/cgroup/cpu/mycpulimitgrp/cpu.cfs_quota_us -1 //或者 # cgget -g cpu:mycpulimitgrp mycpulimitgrp: cpu.shares: 1024 cpu.cfs_quota_us: -1 cpu.stat: nr_periods 0 nr_throttled 0 throttled_time 0 cpu.cfs_period_us: 100000
cpu.cfs_period_us 表示将每个cpu时间片分成100000份。
cpu.cfs_period_us 表示当前这个组中的task(tasks中的taskid)将分配多少比例的cpu时间片。如果是双核cpu,这里就表示最多可以用到200%的CPU。
为我们的cgroup分配 50% cpu的配额
# echo 50000 > /sys/fs/cgroup/cpu/mycpulimitgrp/cpu.cfs_quota_us //或者 # cgset -r cpu.cfs_quota_us=50000 mycpulimitgrp $ cgexec -g cpu:mycpulimitgrp ./cpu.sh $ top -p `pidof -x cpu.sh` PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29224 chic 20 0 14264 904 800 R 50.0 0.0 0:21.42 cpu.sh //stop cpu.sh and clean # cgdelete -r cpu:mycpulimitgrp
参考:
- Resource Management Guide
- Ubuntu 服务器指南(Control Group)
- linux kernel CGroup
- CGroup 介绍、应用实例及原理描述
- Introduction to Linux Control Groups (Cgroups)
- Docker 和 cgroup

相关文章推荐
- excel入门,如何玩转excel,你早该这么玩Excel笔记10
- Docker入门笔记-1
- Docker从入门到实践笔记一
- docker学习笔记10:外部通过ssh访问centos容器
- Odoo10学习笔记一:入门与基础视图格式
- Docker 菜鸟笔记(一)Docker 入门
- Docker 入门笔记 6 - 在Docker Cloud上部署应用
- Docker 入门学习笔记一:Ubuntu安装 Docker
- docker学习笔记2-docker入门
- 10、ExtJS入门教程【学习笔记】
- 【day 10】python编程:从入门到实践学习笔记- 基于Django框架的Web开发-Django入门(一)
- Docker 入门笔记 7 - Namespace 简介(上)
- Docker学习笔记之docker入门
- Docker 入门笔记 1 - 安装docker
- Docker学习笔记1:入门使用
- Docker 入门笔记
- Docker 入门笔记 3 - Service
- Docker 入门笔记 5 - 在Stack中部署多个service
- 《第一本Docker》笔记(三)之Docker入门
- Docker 入门笔记 4 - 用Swarm部署服务