吴恩达《深度学习-神经网络和深度学习》2--神经网络基础
2018-01-23 21:12
561 查看
1.二分类
对特征X以及y的矩阵一般这样标记:(统一的标记方法会让后续的处理更容易)
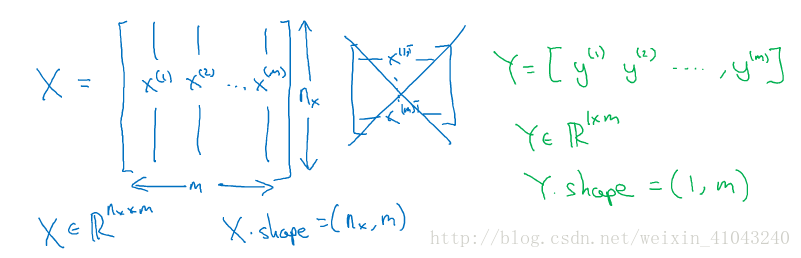
X.shape是python中的命令,来确保X矩阵中每一列是一个样本的数据。
2. 逻辑回归为什么引入sigmoid函数
对于线性回归

,y可能是任意值,而逻辑回归希望完成的是(离散)分类,即确定什么情况下属于此类而什么情况下不属于此类,对此,很难找到一个实数来划分,若能控制y的取值在0到1之间,通过判断y是否为1来确定分类,那么这个问题就可解了,所以这里引入了sigmoid函数,将实数投影到(0,1)这个区间。
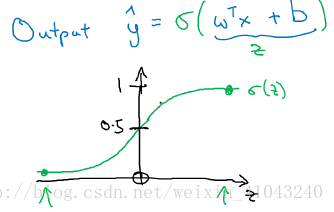
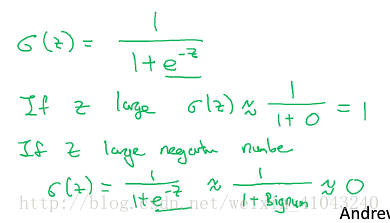
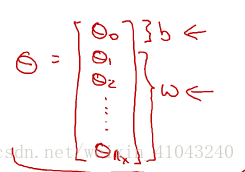
在深度学习里面用w和b来代替机器学习里面的参数theta
3. 逻辑回归的损失函数和成本函数
(1) 损失函数为什么取log?
损失函数用来衡量单个样本预测值与实际值的相似度,通常定义为

,但这个函数会导致后面优化问题为非凸性的,即会有多个局部最优解,可能找不到全局最优解。
(2) 成本函数(cost function)用来衡量算法在整个样本集中的表现

4. 梯度下降(Gradient Descent)
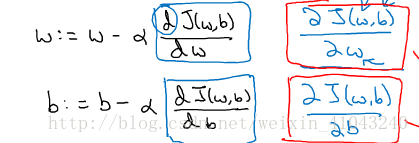

由导数的正负来控制下降的方向
5. 神经网络的梯度下降
欲用梯度下降求最优解,需先求偏导,对于神经网络来说求导需要链式法则+反向传播
6. 向量化
用向量代替for循环可以大大提高运行效率

GPU和CPU 都可以使用SIMD进行并行计算,相比CPU来说,GPU更擅长。
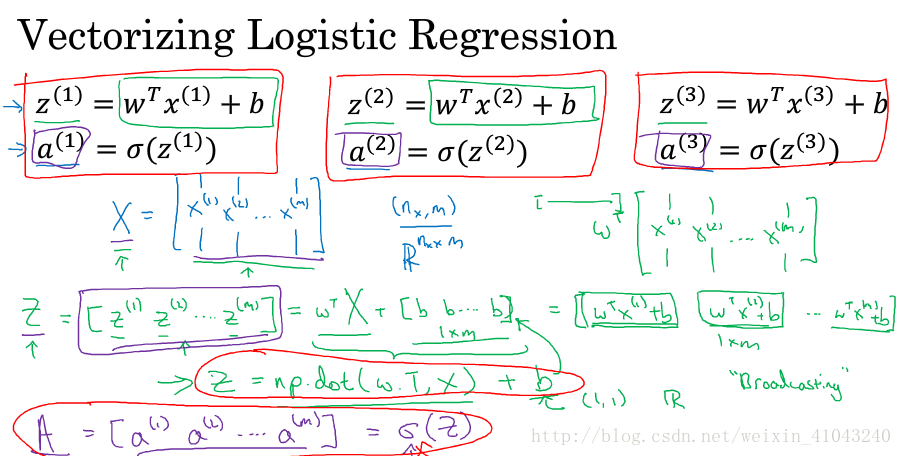
7. 用python写code的一些建议
1)构建矩阵时要标注行列号
import numpy as np
a.np.random.randn(5) //这样构建的其实并不是一个向量,打印a.shape为(5,),是一个秩为1的数组(rank 1 array),其转置等于本身,即aT=a,所以后续操作如果将其看作向量,会产生很多问题。可以用a.reshape((5,1))转换成向量形式
a.np.random.randn(5,1) //推荐这种方式,显示指出行列号,构建向量,a.shape为(5,1).
assert(a.shape=(5,1)) //如果不确定向量的维度,可以使用assert,来确保这是一个列向量( 行向量assert(a.shape=(1,5)))
8. 逻辑回归成本函数详解(选修)

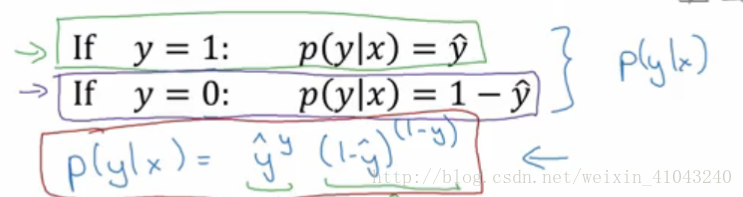
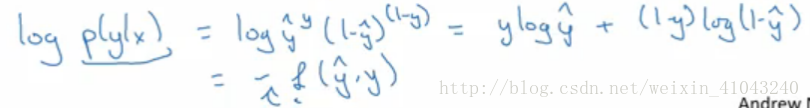
以上是单个样本的损失函数,对于整个数据集来说,其成本函数如下:

计算过程采用的极大似然估计,极大似然估计的求解步骤为:1写出似然函数,2如果无法对似然函数求导,那么就先取对数,3求导,并令偏导为0,4求解模型最优参数。
训练样本独立分布,所以整个样本集的似然函数是P=P(y1|x1)*P(y2|x2)*……*P(ym|xm),
求其最大值,最理想的做法是求一阶导令其为零,而似然函数为乘积形式,无法通过求导获得最优解,所以取对数令乘积变成求和,且其最优值与原函数保持一致
令似然函数最大等价于对其负值求最小值,这就引出了成本函数。(分类问题的最优解即是令成本函数最小的参数)
对特征X以及y的矩阵一般这样标记:(统一的标记方法会让后续的处理更容易)
X.shape是python中的命令,来确保X矩阵中每一列是一个样本的数据。
2. 逻辑回归为什么引入sigmoid函数
对于线性回归
,y可能是任意值,而逻辑回归希望完成的是(离散)分类,即确定什么情况下属于此类而什么情况下不属于此类,对此,很难找到一个实数来划分,若能控制y的取值在0到1之间,通过判断y是否为1来确定分类,那么这个问题就可解了,所以这里引入了sigmoid函数,将实数投影到(0,1)这个区间。
在深度学习里面用w和b来代替机器学习里面的参数theta
3. 逻辑回归的损失函数和成本函数
(1) 损失函数为什么取log?
损失函数用来衡量单个样本预测值与实际值的相似度,通常定义为
,但这个函数会导致后面优化问题为非凸性的,即会有多个局部最优解,可能找不到全局最优解。
(2) 成本函数(cost function)用来衡量算法在整个样本集中的表现
4. 梯度下降(Gradient Descent)
由导数的正负来控制下降的方向
5. 神经网络的梯度下降
欲用梯度下降求最优解,需先求偏导,对于神经网络来说求导需要链式法则+反向传播
6. 向量化
用向量代替for循环可以大大提高运行效率
GPU和CPU 都可以使用SIMD进行并行计算,相比CPU来说,GPU更擅长。
7. 用python写code的一些建议
1)构建矩阵时要标注行列号
import numpy as np
a.np.random.randn(5) //这样构建的其实并不是一个向量,打印a.shape为(5,),是一个秩为1的数组(rank 1 array),其转置等于本身,即aT=a,所以后续操作如果将其看作向量,会产生很多问题。可以用a.reshape((5,1))转换成向量形式
a.np.random.randn(5,1) //推荐这种方式,显示指出行列号,构建向量,a.shape为(5,1).
assert(a.shape=(5,1)) //如果不确定向量的维度,可以使用assert,来确保这是一个列向量( 行向量assert(a.shape=(1,5)))
8. 逻辑回归成本函数详解(选修)
以上是单个样本的损失函数,对于整个数据集来说,其成本函数如下:
计算过程采用的极大似然估计,极大似然估计的求解步骤为:1写出似然函数,2如果无法对似然函数求导,那么就先取对数,3求导,并令偏导为0,4求解模型最优参数。
训练样本独立分布,所以整个样本集的似然函数是P=P(y1|x1)*P(y2|x2)*……*P(ym|xm),
求其最大值,最理想的做法是求一阶导令其为零,而似然函数为乘积形式,无法通过求导获得最优解,所以取对数令乘积变成求和,且其最优值与原函数保持一致
令似然函数最大等价于对其负值求最小值,这就引出了成本函数。(分类问题的最优解即是令成本函数最小的参数)

相关文章推荐
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第二周:神经网络基础)
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第二周:神经网络基础)
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第四节:为什么深度学习会兴起?
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第一周)
- 深度学习基础(一)神经网络 分类: 深度学习 2015-01-19 21:29 84人阅读 评论(0) 收藏
- 吴恩达Coursera深度学习(4-1)卷积神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达深度学习视频笔记1-2:《神经网络和深度学习》之《神经网络基础》
- 吴恩达《深度学习-神经网络和深度学习》4--深层神经网络
- 吴恩达神经网络和深度学习课程自学笔记(二)之神经网络基础
- 吴恩达《深度学习-神经网络和深度学习》3--浅层神经网络
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础(转载)
- 吴恩达《深度学习-神经网络和深度学习》1--深度学习概论
- 吴恩达深度学习课程笔记之神经网络基础
- 吴恩达深度学习视频笔记1-4:《神经网络和深度学习》之《深层神经网络》
- 吴恩达深度学习视频笔记1-1:《神经网络和深度学习》之《深度学习概论》
- [DeeplearningAI笔记]神经网络与深度学习2.1-2.4神经网络基础
- 吴恩达mooc神经网络与深度学习
- 零基础入门深度学习(5) - 循环神经网络